 大数据开发最火技术Kafka背后的“黑科技”
大数据开发最火技术Kafka背后的“黑科技”
Kafka是由Apache软件基金会开发的一个开源流处理平台,被广泛地应用在数据缓冲、异步通信、汇集日志、系统解耦等方面。相比较于其他常见消息系统,Kafka在保障了大部分功能特性的同时,还在高吞吐、低延迟等方面有很突出的表现。这篇文章不同于其他介绍Kafka使用或实现的文章,只是谈谈Kafka用了什么“黑科技”使他在性能方面有这么突出的表现。
消息顺序写入磁盘
磁盘大多数都还是机械结构(SSD不在讨论的范围内),如果将消息以随机写的方式存入磁盘,就需要按柱面、磁头、扇区的方式寻址,寻址是一个“机械动作”也最耗时。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
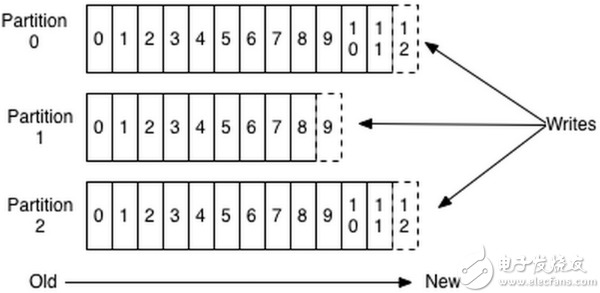 图 1 Kafka顺序IO
图 1 Kafka顺序IO
上图中,每个partition就是一个文件,每条消息都被append 到该 partition 中,属于顺序写磁盘,因此效率非常高。这种方法有一个缺陷—— 没有办法删除数据 ,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示读取到了第几条数据 。
关于磁盘顺序读写和随机读写的性能,引用一组Kafka官方给出的测试数据(Raid-5,7200rpm):
Sequence I/O: 600MB/s
Random I/O: 100KB/s
所以通过只做Sequence I/O,给Kafka带来了性能的极大提升。
Zero Copy
考虑一个web程序读取文件内容并传输到网络的场景,实现的核心代码如下:

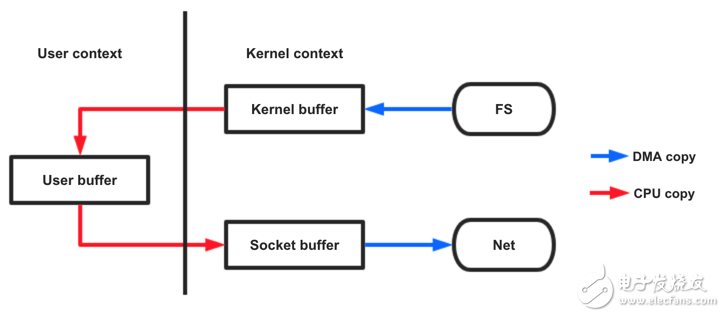 图 2 普通read方法
图 2 普通read方法
虽然只是两个调用,但却经过了4次copy,其中有2次cpu copy,还有多次用户态与内核态的上下文切换,这会加重cpu的负担,而零拷贝就是为了解决这种低效。
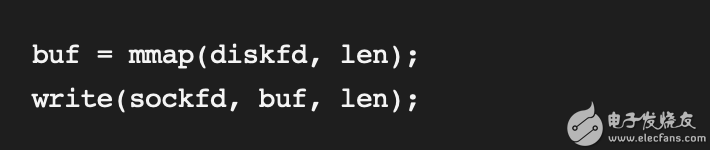
# mmap:
减少拷贝次数的一种方法是调用mmap()来代替read()调用:
应用程序调用mmap(),磁盘上的数据会通过DMA被拷贝到内核缓冲区,接着操作系统会把这段内核缓冲区与应用程序共享,这样就不需要把内核缓冲区的内容往用户空间拷贝。应用程序再调用write(),操作系统直接将内核缓冲区的内容拷贝到socket缓冲区中,最后再把数据发到网卡去。
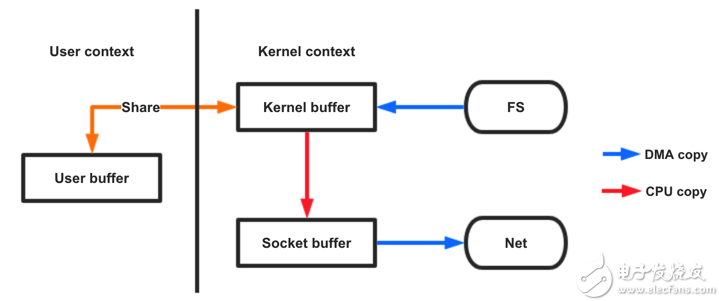 图 3 mmap方法
图 3 mmap方法
使用mmap可以减少一次cpu copy,但也会遇到一些陷阱,当你的程序map了一个文件,但是当这个文件被另一个进程截断(truncate)时, write系统调用会因为访问非法地址而被SIGBUS信号终止。通常可以通过,为SIGBUS信号建立信号处理程序或使用文件租凭(file leasing)的方式去解决,这里就不再赘述了。
# sendfile:
从2.1版内核开始,Linux引入了sendfile来简化操作

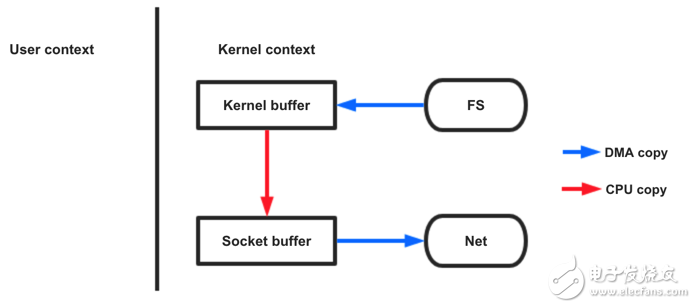 图 4 sendfile方法
图 4 sendfile方法
sendfile() 方法引发 DMA 引擎将文件内容拷贝到一个读取缓冲区(DMA copy)然后由内核将数据拷贝到socket buffer(cpu copy)最后再拷贝到网卡(DMA copy)使用sendfile不仅减少了数据拷贝的次数,还减少了上下文切换,数据传送始终只发生在kernel space
聊到这里,sendfile至少还需要一次cpu copy,那么这一步能不能省去呢?为了消除内核完成的所有数据复制,我们需要一个支持收集(gather)操作的网络接口。同时,在内核版本2.4中,也修改了套接字缓冲区描述符以适应零拷贝要求。 这种方法不仅减少了多个上下文切换,还完全取消了cpu copy。
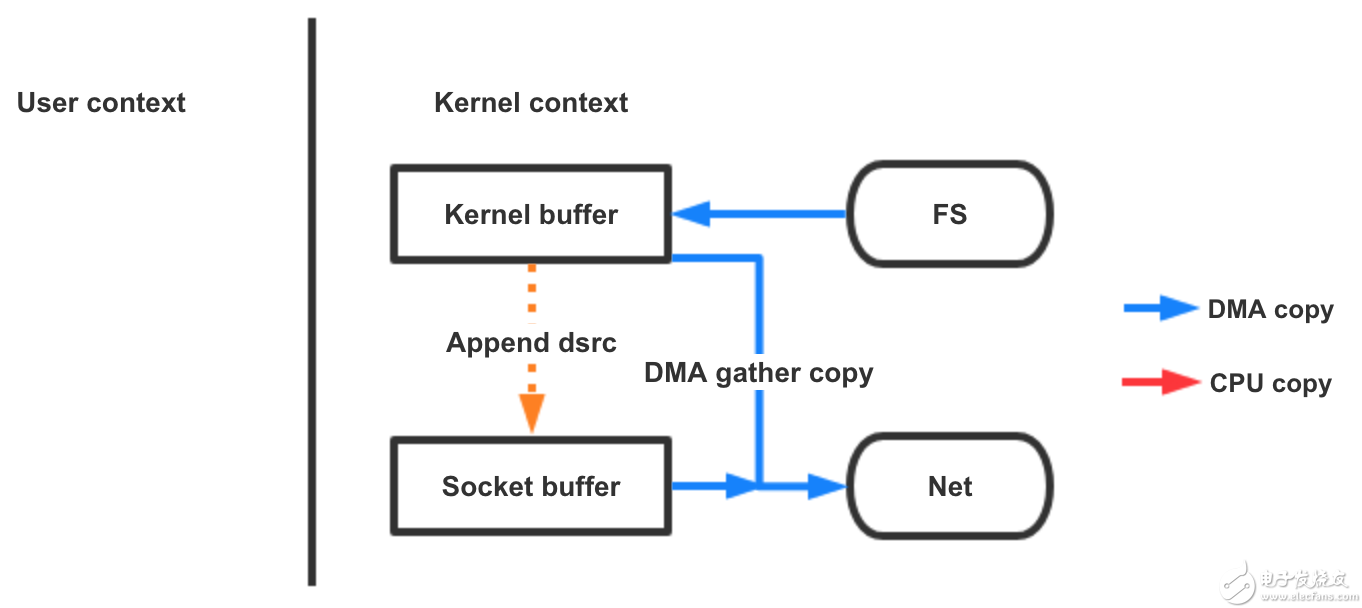 图 5 sendfile方法(DMA gather)
图 5 sendfile方法(DMA gather)
sendfile系统调用利用DMA引擎将文件内容拷贝到内核缓冲区去,然后将带有文件位置和长度信息的缓冲区描述符添加socket缓冲区去,这一步不会将内核中的数据拷贝到socket缓冲区中,DMA引擎会将内核缓冲区的数据拷贝到协议引擎中去,避免了最后一次CPU拷贝。
零拷贝技术非常普遍,JAVA的transferTo、transferFrom方法就是Zero Copy。
发布评论请先 登录
相关推荐
大数据与云计算是干嘛的?
工程大数据平台
华为云 FlexusX 实例下的 Kafka 集群部署实践与性能优化
超详细“零”基础kafka入门篇
raid 在大数据分析中的应用
智慧城市与大数据的关系

基于Kepware的Hadoop大数据应用构建-提升数据价值利用效能
迅为RK3588开发板!黑神话悟空,启动?
《黑神话:悟空》背后的数字化中国——天创信用守卫数据安全
独家探秘!Datasheet5背后的大数据机制
火语言RPA中有哪些优势,可以提高开发效率?
大数据采集系统分为几类
大数据在军事方面的应用有哪些
面试官:Kafka会丢消息吗?





 工商网监
工商网监
评论