 基于FPGA技术实现FFShark方案
基于FPGA技术实现FFShark方案
三端口可编程NIC设备,以其与生俱来的结构优势在各种场景下都可以大显身手,尤其是在网络测量和网络监控领域。在FCCM2020会议上,一篇100G开源的类似于本公众号之前介绍的1G“网络监兵”的研究文章(实验室自研产品介绍:一种多功能的三端口T型转发器):FFShark: A 100G FPGA Implementation of BPF Filtering for Wireshark,介绍了100G速率下Wireshark的快速FPGA实现FFShark。这种设备对于网络测量、网络管理等很多具体的应用具有非常重要的意义,但文中对添加上NIC设备之后对整个网络造成影响的讨论稍显粗糙。我们结合最近的一些热点话题可以分析一下。
最近几天,老美又加大了对华为的约束,几乎将华为逼上绝路。老美之所以费尽心机的制裁华为,最重要的原因就是以5G为代表的网络战略地位的抢夺。网络,已不仅仅是数据通道,而是能够传输互联网时代生命之水的渠道。对数据而言,网络就是上帝。谁主宰了网络,谁就能够掌控未来!而华为现在就是能够修这条新水渠的中国企业,而以前的旧水渠是美国人修的,并且让特朗普恼火的是,华为修这条新的水渠比他们修的快,还修的好。
网络的重要,体现在当代生活中的方方面面。比如笔者所在实验室做的适用于封闭空间的时间触发以太网TTE网络就是如此。谁掌握了TTE网络的规划,谁就掌管了话语权。网络在传递数据信息之前,需要对整个网络提前规划,对整个网络中的关键业务规划调度表,另外还要求各个网络节点之间能够时间同步等等。网络规划者必须对整个系统里所有传感器的每种业务都熟悉。所以,谁规划了整个网络,谁就是总管,当然就可以对所有网络设备以及在网络通道上的所有信息进行“理所应当”的监控。本文介绍的FFshark就可以做这件事情。
Mellanox Spectrum 4000以太网交换机,每个端口支持400Gbps带宽,交换容量高达25.4Tbps。首先数据缓冲架构可以测量交换机的整体带宽,进而可以给每个端口分配一个均衡且可预测的带宽:其次,无与伦比的虚拟化技术,实现跨超大规模数据中心的VXLAN路由虚拟化;第三,你可以通过全新的WJH(What Just Happened)技术准确掌握最新状况。
可编程智能NIC,NVIDIA Mellanox Bluefield 2,世界上最先进的可编程智能NIC,以最高200Gbps的线速度加速安全和数据包处理,网络、存储和安全协议栈现在被完全分离,运行在这些可编程的智能NIC上,它将成为一个重要的基本数据处理单元。成为未来计算发展的三大支柱之一,CPU负责通用计算,GPU负责加速计算,DPU负责数据中心的数据传输和处理。
看完整个演讲,笔者认为,其实,基于FPGA的NIC才是最重要的。因为,不管是什么PU,都是先在FPGA上RUN起来之后再去ASIC化的。硬件加速的极限效果,或许是人类下一个PK的目标。用硬件去实现软件算法,几块FPGA板卡的运算能力秒杀传统的基于CPU软件的超算或传统数据中心已经不再是梦。
因此,掌握采用HDL语言来实现交换机和端节点可编程NIC核心功能将成为未来决胜的最核心技术。而老黄手里的NIC设备,如果再增加上第三个端口,则立即可以实现本文所介绍的FFShark。下面我们就一起看一下FFShark这篇文章。
基于Wireshark的调试可以在普通桌面计算机上以1G的速度进行,但只有功能强大的计算机才能跟上10G的速度,在100G时,这种调试几乎不可能在一台计算机上进行。
本文介绍了Wireshark的快速FPGA实现FFShark。其结果是一个紧凑的、相对便宜的直通设备,可以插入任何正在运行的100G网络中。数据包将在FFShark中传输,不会中断,并且附加的延迟最小。开发人员可以随时向FFShark设备发送标准的Wireshark过滤程序;满足过滤条件的数据包将被复制并通过单独的连接发送回开发人员的工作站。
我们展示了我们的开源直通设备比商用100G交换机具有更低的延迟,并且我们的设计已经能够处理400G的速度。
1. 引言
Wireshark[1]是一个软件工具,允许网络开发人员和管理员在不中断通信的情况下检查实时网络数据包。此检查要求捕获指定的数据包子集,然后可以分析数据包的相关字段。这种能力对于网络分析和调试是非常宝贵的。Wireshark的一个主要优点是它使用了BSD包过滤器(BPF),大多数操作系统内核都支持BPF。BPF技术减少了内存复制,并带来了显著的性能改进。
高性能处理器可以在10G时进行数据包过滤。当我们移动到100G或更高级别时,使用Wireshark就变得不可能了。例如,第9代Intel i99900KS处理器配备16个PCIe3.0[2]通道,每个通道的最大带宽为8 Gbps[3]。假设没有开销,从NIC到CPU的100 Gbps通信需要16个可用PCIe通道中13个的带宽。除此之外,如果时钟速度为5ghz[2],CPU将必须通过PCIe接收数据包,根据用户的规范对其进行过滤,并且可能以每32位字1.6个或更少的时钟周期复制数据包。即使CPU以其他方式被卸载并且从未遭受缓存未命中,仍然不可能以这些速度执行必要的筛选。在非常乐观的假设下,积极的多线程处理可能会使CPU上的100G过滤成为可能,但这是不切实际的,而且无法扩展到更快的速度。

图1 FFShark的体系结构 图4中详细说明了通过部分,图5中详细说明了过滤部分
为了使用Wireshark超过10 Gbps的速度,我们建议使用FFShark。 FFShark是一种开源[4],低延迟直通设备,可以放置在网络中的任意两个点之间。它支持以PCAP过滤器语法1 [5]编写的任意过滤器。在调试中,它可用于对100G流量进行全网分析,例如监视两个交换机之间或数据中心与广域网之间的所有流量。FFShark的额外延迟成本与交换机相当,从而可以进行实时系统测试。
FFShark使用FPGA技术实现,其中并行的过滤器阵列将监听数据包数据(图1)。过滤器被实现为FPGA架构内的CPU,并本地模拟BSD数据包过滤器虚拟机[6]。附加电路将传入的高速网络线路分配到多个较低速度的流中,每个过滤CPU一个。FFShark目前可以在真实的100G网络中执行Wireshark过滤,但是我们将证明FFShark可以以高达400G的速度正确运行(第IV-C节),并且一旦收发器可用就可以立即使用。
本文的其余部分安排如下:第二节提供了Wireshark和BSD包过滤方法的背景讨论。第三节介绍了相关工作。第四节详细介绍了FFShark的设计,包括高速技术和滤波CPU的设计。第五节介绍了实施结果。最后,第六节讨论了今后的工作,第七节对论文进行了总结。
2. 背景
在典型的桌面计算机上,所有传入的数据包都由操作系统内核处理,并复制到正确用户应用程序的内存中。对于实时网络调试,用户应用程序(如Wireshark)请求将数据包也复制到自己的内存中。本节说明Wireshark用于有效复制感兴趣数据包的方法;此方法依赖于BSD数据包过滤技术,本节也将对此进行说明。
2.1 Wireshark体系结构
Wireshark允许开发人员从操作系统请求数据包的副本。此外,开发人员可能不希望看到所有数据包,因此Wireshark还允许隐藏不需要的数据包。最简单的实现是将每个数据包复制到Wireshark的内存中,Wireshark仅显示感兴趣的数据包。一个更有效的解决方案是首先避免复制不需要的数据包。

图2 标准Wireshark操作
图2说明Wireshark如何在标准操作系统环境中操作。开发人员以PCAP语法[5]输入过滤器规范。例如,表达式tcp src port 100仅选择源自端口100的tcp包。Wireshark将此表达式编译为BPF机器代码(在下一小节中描述),并使用内核系统调用安装筛选器代码。到达网卡的数据包由内核数据包处理通过套接字定向到相关的用户应用程序。此外,所有数据包都被复制到BPF过滤器,与过滤器代码描述的过滤器匹配的任何数据包都被复制到Wireshark的用户内存中。
2.2 BSD包过滤器(BPF)
BPF方法源自以下观察结果:“尽早就地过滤数据包会得到回报” [6]。使用这种方法,用户提交一个BPF程序,内核将在每个传入的数据包上执行该程序。这些程序是由OS内核中的仿真器执行的一系列机器代码指令。任何与Wireshark兼容的操作系统都有责任正确模拟BPF计算机。内核只会根据BPF程序的返回值将数据包复制回用户。
BPF机器的简要概述如下。有两个32位寄存器:累加器(A)和辅助(X)。该处理器对整个数据包(包括标头)具有字节可寻址的只读访问权限,对小型暂存存储器具有读/写访问权限。一条指令由其类(表I),寻址模式,跳转偏移和立即值定义。BPF指令布局如图3所示。
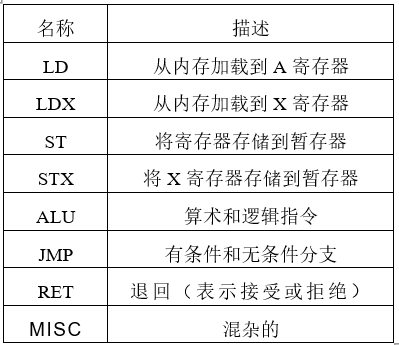
表1 BPF指令类

图3 BPF指令布局。数字是位索引
3. 相关工作
Campbell和Lee[7]实现了一个仅使用普通硬件的100G入侵检测系统(IDS)。使用100G路由器将数据包均匀地分发给多台工作机[8]。为了进一步减少单个机器上的负载,中央管理节点可以允许某些类型的流量在确定安全后绕过IDS。这个IDS的体系结构需要一个100G负载均衡器和几个高性能CPU机器的操作。这样做的优点是使用立即可用的零件,但不具有成本效益。
有许多商用100G网卡和交换机实现了对硬件包过滤的支持,每个网卡和交换机都提供自己的专有API。nBPF[9][10]可以将简单的PCAP表达式转换为这些特定于供应商的格式,但根据特定NIC支持的操作,只能翻译有限的表达式子集。在nBPF利用商用100G硬件的过滤能力的地方,FFShark本机实现完整的BPF标准,作为一个单独的设备,可以插入到任何位置的网络中。这满足了我们保持与Wireshark完全兼容的目标。
另一种类型的100G数据包过滤涉及根据高层过滤器描述自动生成FPGA设计。这种方法利用了FPGA的高性能和可重新配置性,但是旨在满足希望使用简单数据包过滤规范的系统管理员的需求。Xilinx netCope [11]根据P4过滤器规范[12]生成VHDL。此外,更高级的综合技术可以使开发人员编写自己的数据包过滤算法并在FPGA上实现。这些方法几乎没有支持交互地更改过滤器规格的方法。FFshark是符合标准BPF接口的FPGA覆盖层,在更改过滤器时不需要生成新的FPGA配置。
FMAD Engineering提供了一种持续的100G数据包捕获解决方案[13]。该产品是具有两个QSFP28输入端口和十个SSD的阵列的机架式盒子。设备接受BPF过滤器并保存接受的数据包以供以后查看。FMAD是一种商业产品,支持与FFShark相同的过滤功能,并且可以以高达100G的速度运行。但是,FFShark是开源的,可供社区自定义和用于实验。FFShark还显示可在400G网络中使用。
Bittware生产具有包过滤功能的封闭源10/25/40/100G包代理设备[14]。这是具有四个QSFP28端口的PCIe扩展卡。对于过滤,它支持10G速度和过滤器参数的运行时配置,这些参数可以从PCAP过滤器表达式合成。通过更改FPGA映像,可以将解决方案升级为支持100G过滤,而无需其他硬件。该Bittware产品的说明说,它支持“一组行业标准的PCAP ASCII表达式”,这意味着它不具备BPF引擎的全部灵活性,例如FFShark。同样,就像刚刚描述的FMAD产品一样,Bittware产品是一种商业产品,而FFShark则具有开源和为400G速度做好准备的优势。
4. 设计
图1显示了FFShark的概述。该设计包括一个直通扇区(图4)和一个过滤扇区(图5)。使用Xilinx Zynq Ultrascale + XCZU19EG-FFVC1760-2I(MPSoC)来实现FPGA和ARM组件[15]。筛选扇区本身分为三个子组件:斩波器,多个BPF核心和转发器。斩波器将高速输入数据分为几个以较低速度运行的队列。每个队列都馈入一个BPF Core,后者执行一个BPF过滤程序。最后,如果数据包被接受,则转发器将其发送出过滤器。这些子组件中的每一个都在下面的单独小节中详细介绍。
4.1 直通扇区

图4 直通扇区的设计
直通扇区如图4所示。Ultrascale+器件中经过100G加固的CMAC提供了称为LBUS的本地总线接口。由于所有其他Xilinx内核都使用AXI,因此LBUS到AXIS转换器电路[16]将PHY层的原始信号转换为标准AXI流消息,反之亦然。AXI Streaming通道连接在一起,允许所有消息直接转发到相对的端口。

图5 过滤部分的设计
两个QSFP28收发器的时钟速度约为323 MHz,但由两个独立的时钟驱动。因此,需要其他逻辑将消息从一个时钟域转换到另一个时钟域。尽管使用的时钟略有不同,但两个收发器的额定工作频率均为100G,并且在业务突发之间存在间隙的情况下,可以维持此数据速率。添加了FIFO缓冲以允许这些随机的短期突发。
直通流量通过AXI流通道发送。构成此通道的连线也直接送入斩波器,从而使其能够观察到任何通过的通讯。
4.2 斩波器
过滤扇区旨在允许用户指定任何过滤器(即BPF程序)。由于指令的数量(因此,程序运行时间的长度)事先未知,因此我们允许用户在多个并行BPF内核之间分配任务,如图5所示。为此,我们实现了一个带有一个Chopper的Chopper。每个数据包过滤器一个输出队列。这也使我们能够以较低的频率为BPF CPU提供时钟,从而大大减轻了复杂结构的FPGA编译负担[17]。
这种架构为我们提供了向上扩展的巨大余地。BPF内核具有最大可操作比特率;即使如此,当到400G速度时,斩波器也可以很容易地重新配置,以将输入比特率分配到大量的较慢输出队列中。
斩波器在HLS中实现如下。单个AXI流输入接收数据包。该输入的时钟频率最高可达475 MHz,并且对输入通道的数据宽度没有限制。一个仲裁器,基于检测到前向拥塞和缓冲区使用情况的探测器,并根据其最近的历史上发送的前几个数据包的位置,为每个数据包选择一个输出流,使每条输出线的平均比特率保持在指定的量以下。决策逻辑与交叉开关分开,让斩波器有一个较小的关键路径。输出决策基于四个周期的信息。但是,由于我们有足够的输出缓冲来容纳至少一个数据包加四个滤波器,因此不会影响可靠性。数据包被认为是不可分割的;来自输入流的整个数据包被发送到相同的输出流,其中数据被缓存在FIFO存储器中。第二条电路从该FIFO存储器中读取数据,并将其作为具有适当时钟速度和通道宽度的AXI流信号输出,以支持BPF Core的最大比特率。
斩波器的仲裁部分将每条输出线上的平均比特率设置为50 Gbps。但是,数据包的不可分割性要求斩波器使用165 Gbps的间歇性突发(在322MHz时为512位宽的信号)来完成此任务。出于这个原因,数据需要进行缓冲,因为BPF内核无法支持超过51.2Gbps的突发。为防止该FIFO缓冲区溢出,将容量设置为足够大以缓冲两个最大数据包(3kB或18kB,启用巨型数据包)。即使尚未完全读取数据包,缓冲区也可以接受整个新数据包。使用大小范围从64B到9kB的随机分组进行的测试表明,当平均输入比特率保持在100 Gbps时,不会丢失任何分组。
仲裁器能够不考虑网络流量的组成(即,大小分组的分布)而工作。然而,并行方法可能会导致数据包被记录得不整齐。为了解决这个问题,每个传入的包都会记录一个时间戳(基于全局FPGA时钟计数器),并将其添加到报头。目前,软件可以执行包的重新排序任务,但是,在硬件中进行包的重新排序更为可取。一种选择是完全删除时间戳,而改为修改斩波器和转发器,使数据包从不出差错;这将具有最低的额外FPGA资源成本,并且只会遭受最大吞吐量的小损失。或者,一个通用的重排序缓冲器将以显著增加片上存储器成本为代价来保持最大吞吐量。这些进展留作今后的工作。
4.3 时钟
直通扇区在每个方向上使用一个时钟为322 MHz的512位AXI流通道。每个通道支持的最大比特率为164 Gbps(322 MHz时为512b)。斩波器以全速监听此通道,并输出几个流,这些流以100 MHz的时钟速度运行,总线宽度为512位,比特率为51.2 Gbps,这是BPF内核可接受的速度。每个BPF内核都能够以51.2 Gbps的相同速率输出接受的数据包。
目前,我们没有可用的400G硬件。但是,我们使用内部生成的随机数据包信号进行了400G Chopper测试,该数据包的大小在40至9000字节之间,时钟频率为450MHz。总线宽度为1024位宽,最大位速率为460.8G。即使在这种比特率下,斩波器也能够将输入正确地分为51.2 Gbps的九个输出信号(100 MHz的512位总线),而不会丢包。
4.4 BPF核心
当前,Wireshark依靠OS内核从网络硬件接收数据包,并基于任意BPF程序执行过滤。如第一节所述,即使功能强大的CPU机器也无法在100G时执行这些任务之一。FFShark将过滤操作从OS内核转移到100G网络中嵌入的直通设备,并使用称为BPF内核的并行处理器阵列执行过滤(图5)。

图6 BPF核心
每个BPF内核都配备了自己的指令存储器和数据包存储器,如图6所示。来自斩波器的每个数据包都被复制到BPF内核的数据包存储器中。每个内核的指令存储器可以在运行时通过外部配置总线加载BPF程序,该BPF程序将针对接收到的每个数据包执行一次。程序使用RET指令使BPF内核发出接受或拒绝信号。接受后,转发器(第IV-G节)会将数据包发送到外部存储。
BPF CPU由一个数据路径和一个控制器组成。图7中详细显示了数据路径。控制器通过三个阶段进行流水线处理:获取,执行和写回。最后两个阶段通过控制信号线控制数据路径,并支持除MUL,DIV和MOD(实际过滤应用中很少使用)之外的所有BPF操作。有四个未连接到数据路径的控制信号:inst_rd_en和pack_rd_en信号直接连接到它们各自的存储器,并且cpu_acc和cpu_rej用于向Ping-Pang-Pong互连发送信号,如第IV-F节所述。数据路径通过其inst_rd_data线连接到指令存储器,并通过其pack_rd_addr和pack_rd_data线连接到分组存储器。图7中的所有其他连线都是内部的,请勿离开模块。
4.5 并行BPF核数的选择
斩波器必须在具有最大可操作比特率的多个并行BPF内核之间分配输入流。但是,如果BPF程序很长和/或BPF内核被过多的小数据包淹没,则每个内核的有效比特率会降低,并且需要更多的比特率来支持100G带宽。
本小节将提供一种用于估算所需并行核数的通用技术,以及一个正在运行的示例,如清单1所示。此清单显示了tcp src端口100 PCAP过滤器表达式产生的BPF指令。对于我们正在运行的示例,我们假设20%的输入数据包既不使用IPv4也不使用IPv6,30%的数据包使用IPV4和UDP,25%的数据包使用IPv4和TCP,但不是来自源端口100,而25%的数据包 使用IPv4和TCP,并且来自源端口100。对于我们的示例,平均数据包长度将为680B。
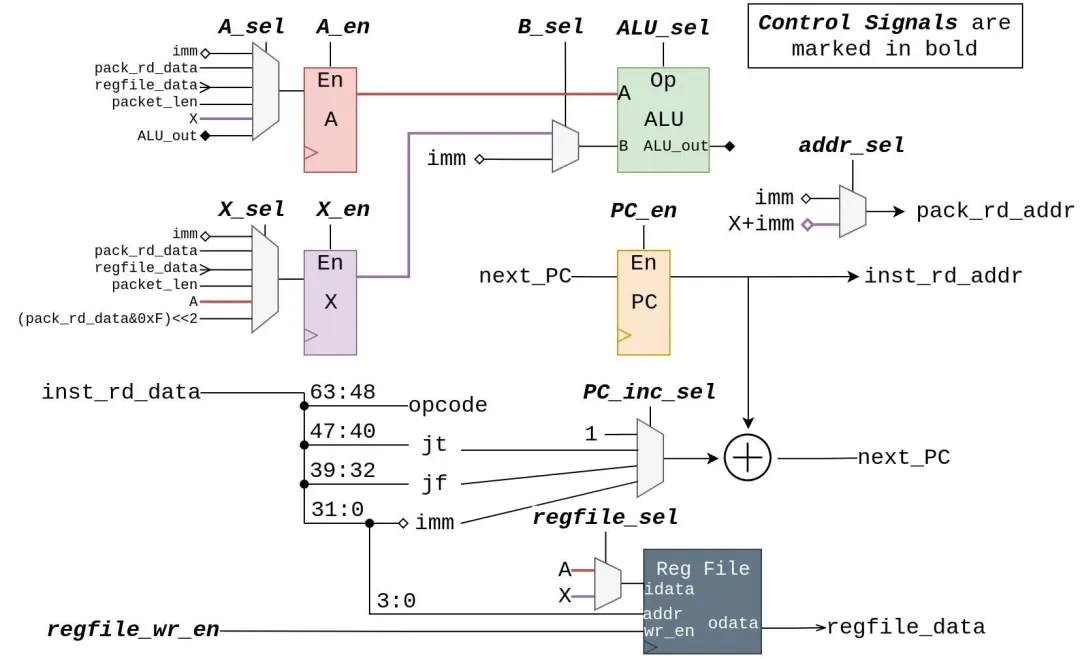
图7 BPF CPU数据路径

清单1 为PCAP筛选器tcp src端口100编译的BPF机器代码
通常,包的输入流可以分为k个不同的类,其中每个类在过滤器代码中触发相同的执行路径。在我们的运行示例中,k =4。类i中的每个数据包均具有长度为Ii的指令的代码路径,并且具有平均长度的中断。最后,随机选择的输入分组具有属于类别i的概率Pi。表II中显示了运行示例的Ii,li和Pi的值。
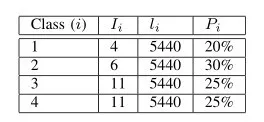
表2 i,li和Pi值,用于运行第IV -E节中的示例
对于这些计算,我们将假设BPF CPU每条指令需要四个周期,即CPI =4。如果CPU以时钟周期T秒运行,那么BPF CPU(RCPU)的平均比特率为:

公式1中的分母表示CPU处理单个数据包所需的时间(以秒为单位)。
RCPU代表BPF CPU的比特率。但是,要选择正确数量的BPF核心,请计算RCore,即BPF核心的比特率:

其中512位×100 MHz表示可用于填充BPF核心的分组存储器的最大比特率(c.f.第IV-c节)。
因此,所需的并行BPF核心数是N =“100G/RCore”。在我们的示例中,RCPU=19.8G,因此RCore=19.8G,N=6。在实际应用程序中,FFShark用户必须根据对正在调试的系统的了解,对k、Ii、li和pi进行有根据的猜测。
一般来说,我们已经发现六个并行核心足以用于常见的过滤器,例如选择所有到/来自特定地址或端口范围的数据包。更复杂的滤波器可能需要更多的BPF核,并且应该完成所描述的估计所需数量的过程。然而,即使当一个过滤器变得更复杂时,过滤器代码也能够在被拒绝的包上提前终止,而被接受的包的比例通常会降低。考虑表3所示的例子:这个例子为一个过滤器建模,其中有更多的条件应用于与我们前面的例子相同的流量模式。具体来说,过滤器检查包含数据的任何HTTP包。类1和类2仍然被提前拒绝,类4在被拒绝之前需要另外两条指令。然而,类3分为两类:3a是通过新过滤器的某些条件但最终被拒绝的包,3b是通过所有条件的包。即使接受包的指令数要大得多,在本例中,所需的并行核心数仍然是6。

表3 Ii、li和PiVALUES用于过滤器TCP端口80和((IP[2:2]-((IP[0]&0XF)>2))!=0)
4.6 乒乓控制器
BPF内核是一个BPF CPU,配备了一个指令存储器和一个数据包存储器(图6)。立即我们注意到,包内存在三个代理之间共享:斩波器,BPF CPU和转发器。一个重要的性能优化是“乒乓球”缓冲区,如图8所示。此方案使所有三个代理可以同时全速访问内存。

图8 乒乓缓冲区
自定义互连维护三个fifo,表示每个代理的作业队列。在任何给定时刻,多路复用器都会使用代理队列头部的令牌将代理与Ping、Pang或Pong缓冲区之一连接。
图9展示了实际的技术。左上角的块表示作业队列的初始状态,可以理解为“所有三个缓冲区都在等待斩波器读取数据包,斩波器当前连接到Ping缓冲区”。当斩波器完成将数据包读入Ping缓冲区时,Ping令牌将从斩波器队列中弹出并添加到CPU队列(右上角块)。此时,斩波器现在连接到Pang缓冲区,CPU开始在Ping缓冲区中处理数据包。左下角的块显示了如果斩波器在CPU完成其程序执行之前读取完数据包会发生什么情况:Pang令牌从斩波器队列中弹出并添加到CPU队列中。右下角的图显示了CPU接受数据包的结果:Ping令牌从CPU队列中弹出并添加到转发器队列中。

图9 乒乓球互连中的作业队列
4.7代理
接收到数据包后,BPF核心将Ping,Pang或Pong缓冲区之一放在转发器的工作队列上。然后,转发器从缓冲区读取并在512位宽的AXI流(以100 MHz输出)上输出数据包数据。
如果目标FPGA器件配备了三个(或更多)QSFP28端口,则可以重新组合接受的数据包流并以全100G速率发送出去。这项工作中使用的FPGA只有两个QSFP28端口,但是具有到连接的ARM CPU的高带宽通道。
从Vega等人的工作中借鉴[18],扩展了它们的协议,实现了FPGA与ARM处理器之间的双向消息传输。使用该方案,我们能够连接来自BPF核心的已接受数据包并将其转发到ARM核心。还添加了一个头,以允许一些元数据随数据包一起传输。一旦进入ARM核心,就可以根据需要处理消息。出于功能目的,初始测试将过滤后的消息打印到ARM处理器的终端上。为了更实际的实现,单独开发的存储系统[19]允许我们可靠地、低开销地将收集到的消息存储到远程存储服务器。该系统可同时供FPGAs和cpu使用。然而,由于我们缺少第三个网络端口,数据包被转发到ARM以使用ARM的网络端口。
为了将这个通道用于接收的数据包流,我们为转发器构建了一个自定义数据宽度转换器,该转换器将时钟保持在100MHz,但将总线宽度减小到64位(比特率为6.4 Gbps)。对于ARM处理器而言,这足够慢以接收接受的数据包。如果接受的数据包的带宽超过了此6.4 Gbps瓶颈的速度,则“过滤扇区”将丢弃数据包,但“直通扇区”不会受到影响。
5. 结果与讨论
对于这些结果,FFShark系统在Zynq Ultrascale + XCZU19EG-FFVC1760-2-I上实现[15]。该芯片在同一硅芯片上包括FPGA和ARM CPU。两者可以通过几个高速AXI通道进行通信。FPGA具有110万个逻辑元件和9.8 MB的片上存储器。该处理器是64位ARM Cortex-A53。该芯片是Fidus Sidewinder 100 [15] FPGA板的一部分,该板将MPSoC连接到两个QSFP28 4x25G端口,一个1G以太网端口以及许多其他外设。
为了表征FFShark的性能,我们收集了三种测量方法:增加的直通业务延迟、包丢弃率、滤波器和直通扇区的性能以及设计所需的FPGA资源数量。
5.1 插入延迟
此测试的目标是测量lP,即FFShark的passthrough扇区的插入延迟,定义为数据包在一个QSFP端口上进入另一个QSFP端口上离开所用的时间。图10概述了测试设置。图中的每个灰盒代表一个侧板,每个连接都是2 m 100G电缆。UDP被选为具有一致延迟的轻量级可路由协议,可以从总延迟中减去。

图10 延迟测量的测试设置
测量了直接连接的往返时间,如图10a所示。此数量用LD表示,并表示数据包到达以下状态所花费的时间:
1)100G UDP内核进行处理[16]
2)穿过2 m的电缆(lC)
3)进入和退出环回
4)传递通过2 m的电缆。
5)返回流量生成器后,由100G UDP核心进行处理。
当数据包发送到UDP核心时(步骤1),以及数据包返回后离开UDP核心时(步骤5),流量生成器板都会保存时间戳。
接下来,如图10b所示,测量包括FFShark的往返时间。该数量用LP表示。

表4 直接连接和通过测试的往返时间
表IV列出了各种数据包大小(包括36字节UDP报头)的LD和LP的测量值,连续100G传输中平均超过4000个数据包。给定通过铜电缆的传播速度,发现2 m电缆的传播延迟lC为0.009μs[20]。图11示出了计算值lP =(LP-LD-2·lC)/ 2。用Dell Z9100-ON 100G交换机代替FFShark进行了类似的测试,如图10c所示。在图11中还示出了该交换机ls的测量的插入等待时间,以呈现FFShark和商品100G硬件之间的比较。请注意,该交换机不支持大于MTU限制1.5KB的数据包。

图11 FFShark(LP)与Dell Z9100-ON 100G交换机(LS)的插入等待时间
小于100字节的数据包记录了更高的延迟。这是由于我们的测试超出了第V-D节中所述的小数据包的最大数据包速率。当比特率降低时,大小为100字节或更小的数据包的插入等待时间大约等于164字节大小的数据包的测试等待时间(约0.3μs)。此外,FFShark的延迟随着数据包大小的增加而增加。目前,我们正在使用Xilinx CMAC控制器,这迫使我们存储和转发整个数据包,而不是使用直通方法。
5.2 最高性能
为了测试最高性能,通过FFShark以全100G比特率将32768个数据包(大小从16B到1500B)发送到回送设备,并在原始位置重新收集。原始设备验证了数据包的完整性,并计算了丢失或损坏的数据包的数量。在此高度拥塞的应用程序中,正确返回了99.41%的数据包。没有数据包被返回损坏。修改测试以测试大小在176B到1500B之间的数据包时,没有数据包被丢弃。V-D节探讨了这些数据包丢弃的来源。可以添加握手或流控制来减轻这些数据包丢失。
已显示直通扇区和过滤扇区永远不会丢失数据包4。通过多次运行测试来证明这一点,在该测试中,具有唯一标头的单个数据包被隐藏在100G流量突发中的不同位置。对数据包过滤器进行编程以检测签名。在所有情况下,FFShark都能正确识别数据包并将其转发给ARM,而忽略所有其他数据包。
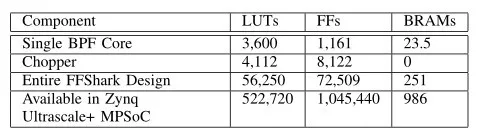
表5 FFSHARK和所选子组件的资源使用
5.3 资源使用
表5显示了该项目的资源使用情况。前两行显示单个BPF Core和Chopper的资源使用情况。第三行显示了最终FFShark设计的全部成本;该表包括六个BPF内核,一个斩波器,以及直通扇区以及将指令存储器和转发器与板载ARM CPU接口所需的额外逻辑。此设计中未使用DSP。由于此设计仅使用FPGA总容量的一小部分,因此剩余资源可用于添加更多的过滤核心,或将FFShark嵌入更大的设计中。或者,可以将FFShark放置在更小,更便宜的FPGA上。
5.4 讨论
在包含小于176B的数据包(100G比特率)的测试中,发现了高延迟和偶尔的数据包丢弃。已经发现,FPGA上的100G CMAC和收发器具有每个数据包的开销[21],除了最大比特率约束之外,还创建了最大数据包率约束。在使用小数据包的测试中,每秒的数据包数超过了此最大值,并且网络硬件开始施加反压。GULF流UDP内核具有内部缓冲区,可以暂时缓解此问题。然而,随着这些缓冲区的填满,数据包的积压意味着等待时间线性增加,导致在较小的数据包大小下出现高等待时间,如第V-A节所示。最终,GULF流FIFO完全填满,导致在V-B节中看到的基于拥塞的数据包丢失很少。对于较小的数据包大小,当降低比特率时,对于所有数据包大小,数据包丢弃都会停止,并且延迟遵循相同的趋势。
除了基于硬件的限制之外,FFShark的性能达到了预期的目标,与高端100G交换机相比,它增加了更小的延迟,并且不影响数据包数据。当不超过转发器的带宽时,筛选器可以检查100%的传入数据包。
总体设计仅占用FPGA资源的不到四分之一,并且Chopper能够以400G的速度正确分配输入流。当MAC /收发器支持可用时,这会使FFShark立即扩展到400G。
6. 未来的工作
这项工作具有广阔的发展前景,因为它可以扩展到各种速度,并且用途广泛。虽然在这种情况下,它用于交互式分析网络流量,但可以通过修改直通扇区来调试任何类型的数据通信。例如,PCIe信号也可以转换为AXI流,并以类似方式进行[P1] 观察。FFShark还可以用于监视和调试FPGA设计中的常规信号。
寻找和是否可以修改BPF语言以更好地用作交互式调试工具是一个研究问题。例如,eBPF[22]在Linux内核中用于跟踪文件系统调用,创建I/O传输的直方图以及其他高级调试任务。并非eBPF支持的所有功能都能很好地映射到FPGA实现中,但是共享内存模型对于以100G的速度收集全局统计信息至关重要。
BPF Core是可以接受任意程序的处理器。尽管通用统计信息易于收集,但我们希望为用户创建一种方法,以编程新类型的测量并让该系统报告实时值。然后,SDN应用程序可以使用这些自定义统计信息来改进路由和其他决策。
当前这项工作与Wireshark兼容,因为它使用相同的BPF机器代码并返回相同的结果。但是,需要一些工作才能将其与Wireshark代码库集成在一起,以便可以使用熟悉的Wireshark GUI和实用程序。这可以通过创建一个自定义OS网络驱动程序来完成,该驱动程序将筛选器程序传输到FFShark,而不是在内核中执行它们。
7. 结论
我们创建了一个工作在100G的直通设备,可以对其进行编程以标记和存储观察到的数据包的子集。该子集使用PCAP过滤语言指定,允许用户继续使用熟悉的语法。该器件还被证明可以在全100G的速度下运行而不会丢包,并且一旦收发器和FPGA网络支持可用,它就可以立即扩展到400G。与商用100G交换机相比,该设备为网络数据增加了400ns的延迟。由于网络设计期望延迟在此范围内,并且FFShark不会显着改变环境,因此这证明它可用于实时环境中的调试。
8. 致谢
M.A.Merlini和J.C.V.ega是这项工作的同等贡献者。作者们要感谢匿名评论者的深刻反馈。我们感谢Edward S.Rogers高级电气和计算机工程系、安大略大学研究生奖学金、华为、Xilinx和NSERC的资助。最后,我们感谢Xilinx和Fidus系统捐赠芯片、工具和支持。
9. 参考文献
[1] Wireshark, “Wireshark User’s Guide Version 3.3.0,” 2018, https://www. wireshark.org/docs/wsug html/.
[2] Intel, “Intel Core I9 9900KS processor specifications,” 2019, https://www.intel.ca/content/www/ca/en/products/processors/core/i9-proce....
[3] PCIe-Consortium, “PCI Express® Base Specification Revision 3.0,” PCIe Group, pp. 1–860, 2010, http://www.lttconn.com/res/lttconn/pdres/ 201402/20140218105502619.pdf.
[4] M. Merlini and C. Vega, “A versatile Wireshark-compatible packet filter, capable of 100G speeds and higher,” 2020, https://github.com/ UofT-HPRC/fpga-bpf.
[5] V. Jacobson, C. Leres, and S. McCanne, pcap-filter(7) - Linux man page, Lawrence Berkely National Laboratory.
[6] S. McCanne and V. Jacobson, “The BSD Packet Filter: A New Archi- tecture for User-level Packet Capture.” in USENIX winter, vol. 46, 1993.
[7] S. Campbell and J. Lee, “Prototyping a 100G monitoring system,” in 2012 20th Euromicro International Conference on Parallel, Distributed and Network-based Processing.IEEE,2012,pp.293–297.
[8] V. Paxson, “Bro: a system for detecting network intruders in real-time,”Computer networks, vol. 31, no. 23-24, pp. 2435–2463, 1999.
[9] A.Cardigliano,“PF-RING-nBPF,”92019,https://github.com/ntop/PFRING/tree/dev/userland/nbpf.
[10] D. Luca, “nBPF,” Sharkfest Europe, pp. 26–37, 2016, https:// sharkfesteurope.wireshark.org/assets/presentations16eu/02.pdf.
[11] “NetcopeP4,”productBrief.[Online].Available:https://www.xilinx. com/products/intellectual-property/1-pcz517.html
[12] “P4 Language Specification,” 2019. [Online]. Available: https://p4.org/ p4-spec/docs/P4-16-v1.2.0.pdf
[13] “Full Line Rate Sustained 100Gbit Packet Capture,” product Brief. [On- line]. Available: https://www.fmad.io/products-100G-packet-capture. html
[14] “10/25/40/100G Packet Broker with PCAP Filtering,” product Brief. [Online]. Available: https://www.bittware.com/ 102540100g-packet-broker-with-pcap-filtering/
[15] Fidus, “Sidewinder-100 Datasheet,” 2018, https://fidus.com/wp-content/ uploads/2019/01/Sidewinder Data Sheet.pdf.
[16] Q. Shen, “100G UDP Link for FPGAs though AXI STREAM (GULF STREAM),” 2019, https://github.com/UofT-HPRC/GULF-Stream.
[17] R. Fung, V. Betz, and W. Chow, “Simultaneous Short-Path and Long- Path Timing Optimization for FPGAs,” IEEE/ACM International Confer- ence on Computer Aided Design, pp. 838–845, 2004, https://ieeexplore. ieee.org/document/1382691.
[18] J. Vega, Q. Shen, A. Leon-Garcia, and P. Chow, “Introducing ReCPRI: A Field Re-configurable Protocol for Backhaul Communication in a Radio Access Network,” IEEE/IFIP International Symposium on Integrated Network Management, pp. 329–336, 2019, https://ieeexplore.ieee.org/ document/8717902.
[19] J. Vega, “SHIP: A Storage System for Hybrid Interconnected Proces- sors,” Master’s thesis, University of Toronto, Department of Electrical and Computer Engineering, Apr. 2020.
[20] Mellanox, “100Gb/s QSFP28 Direct Attach Copper Cable,” 2018, https://www.mellanox.com/related-docs/prod cables/PB MCP1600-Exxx 100Gbps QSFP28 DAC.pdf.
[21] Xilinx, “UltraScale Devices Integrated 100G Ethernet Subsystem v2.5,” 2019, https://www.xilinx.com/support/documentation/ip documentation/ cmac/v2 5/pg165-cmac.pdf.
[22] B. Gregg, BPF Performance Tools. Addison-Wesley Professional, 2019.
编辑:hfy
-
FPGA
+关注
关注
1633文章
21816浏览量
607093 -
斩波器
+关注
关注
0文章
63浏览量
9203 -
以太网交换机
+关注
关注
0文章
124浏览量
14314 -
PCAP
+关注
关注
0文章
12浏览量
12642
发布评论请先 登录
相关推荐
基于FPGA实现图像直方图设计
FPGA驱动AD芯片之实现与芯片通信
如何实现FPGA的IO输出脉冲信号放大?
FPGA技术的主要应用
基于FPGA的人脸识别技术
FPGA无芯片HDMI接入方案及源码
FPGA实现LeNet-5卷积神经网络
如何在FPGA上实现神经网络
采用创新的FPGA 器件来实现更经济且更高能效的大模型推理解决方案
珠海錾芯实现28纳米FPGA流片
基于FPGA设计频率计方案介绍分享
FPGA实现的“俄罗斯方块”游戏系统设计







 工商网监
工商网监
评论