 Python爬虫:寻找并分析百度云的转存api
Python爬虫:寻找并分析百度云的转存api
寻找并分析百度云的转存api
首先你得有一个百度云盘的账号,然后登录,用浏览器(这里用火狐浏览器做示范)打开一个分享链接。F12打开控制台进行抓包。手动进行转存操作:全选文件->保存到网盘->选择路径->确定。点击【确定】前建议先清空一下抓包记录,这样可以精确定位到转存的api,这就是我们中学时学到的【控制变量法】2333。
可以看到上图中抓到了一个带有 “transfer” 单词的 post 请求,这就是我们要找的转存(transfer)api 。接下来很关键,就是分析它的请求头和请求参数,以便用代码模拟。

点击它,再点击右边的【Cookies】就可以看到请求头里的 cookie 情况。
cookie分析
因为转存是登录后的操作,所以需要模拟登录状态,将与登录有关的 cookie 设置在请求头里。我们继续使用【控制变量法】,先将浏览器里关于百度的 cookie 全部删除(在右上角的设置里面,点击【隐私】,移除cookies。具体做法自己百度吧。)
然后登录,右上角进入浏览器设置->隐私->移除cookie,搜索 "bai" 观察 cookie 。这是所有跟百度相关的 cookie ,一个个删除,删一个刷新一次百度的页面,直到删除了 BDUSS ,刷新后登录退出了,所以得出结论,它就是与登录状态有关的 cookie 。
同理,删除掉 STOKEN 后,进行转存操作会提示重新登录。所以,这两个就是转存操作所必须带上的 cookie 。
弄清楚了 cookie 的情况,可以像下面这样构造请求头。
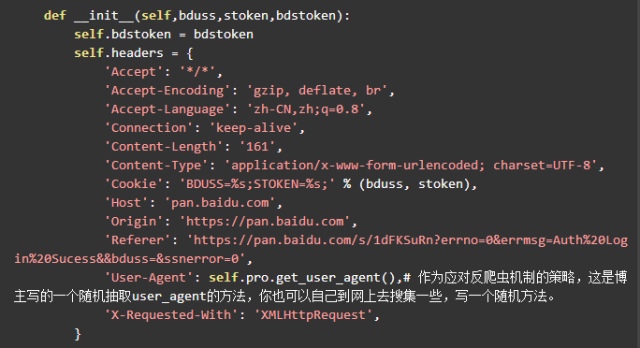
除了上面说到的两个 cookie ,其他的请求头参数可以参照手动转存时抓包的请求头。这两个 cookie 预留出来做参数的原因是 cookie 都是有生存周期的,过期了需要更新,不同的账号登录也有不同的 cookie 。
参数分析
接下来分析参数,点击【Cookies】右边的【Params】查看参数情况。如下:
上面的query string(也就是?后跟的参数)里,除了框起来的shareid、from、bdstoken需要我们填写以外,其他的都可以不变,模拟请求的时候直接抄下来。
前两个与分享的资源有关,bdstoken与登录的账号有关。下面的form data里的两个参数分别是资源在分享用户的网盘的所在目录和刚刚我们点击保存指定的目录。
所以,需要我们另外填写的参数为:shareid、from、bdstoken、filelist 和 path,bdstoken 可以手动转存抓包找到,path 根据你的需要自己定义,前提是你的网盘里有这个路径。其他三个需要从分享链接里爬取,这个将在后面的【爬取shareid、from、filelist,发送请求转存到网盘】部分中进行讲解。
搞清楚了参数的问题,可以像下面这样构造转存请求的 url 。
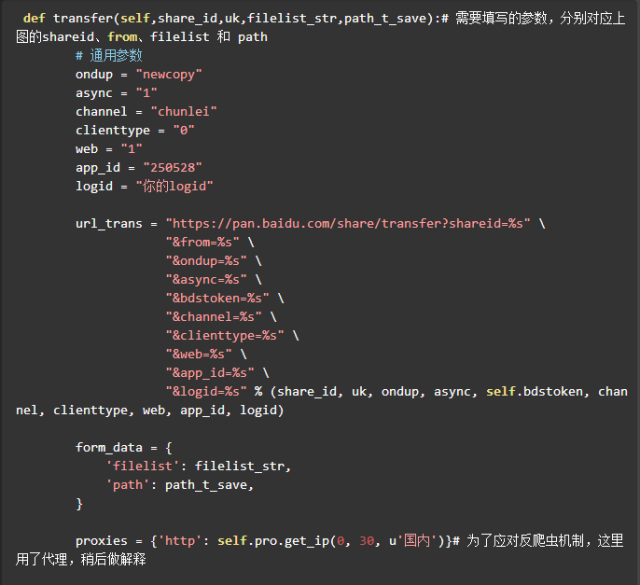
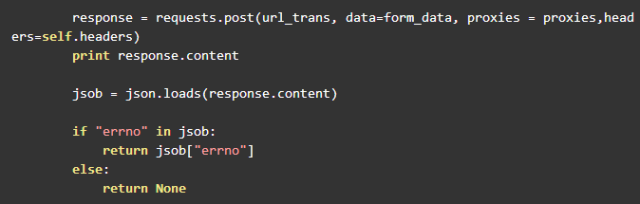
爬取shareid、from、filelist,发送请求转存到网盘

以上面这个资源链接为例(随时可能被河蟹,但是没关系,其他链接的结构也是一样的),我们先用浏览器手动访问,F12 打开控制台先分析一下源码,看看我们要的资源信息在什么地方。控制台有搜索功能,直接搜 “shareid”。
定位到4个shareid,前三个与该资源无关,是其他分享资源,最后一个定位到该 html 文件的最后一个标签块里。双击后可以看到格式化后的 js 代码,可以发现我们要的信息全都在里边。如下节选:
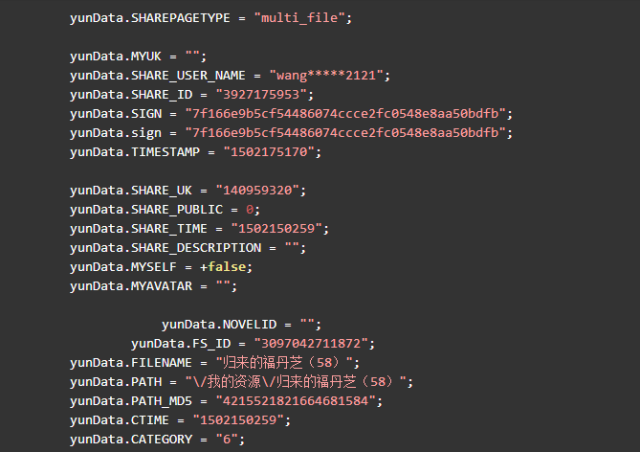
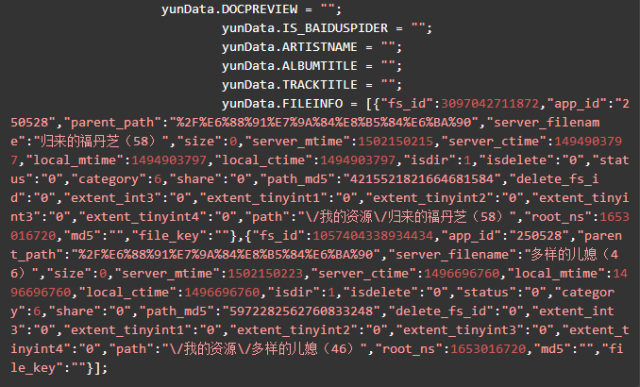
可以看到这两行

yunData.PATH 只指向了一个路径信息,完整的 filelist 可以从 yunData.FILEINFO 里提取,它是一个 json ,list 里的信息是Unicode编码的,所以在控制台看不到中文,用Python代码访问并获取输出一下就可以了。
直接用request请求会收获 404 错误,可能是需要构造请求头参数,不能直接请求,这里博主为了节省时间,直接用selenium的webdriver来get了两次,就收到了返回信息。第一次get没有任何 cookie ,但是baidu 会给你返回一个BAIDUID ,在第二次 get 就可以正常访问了。
yunData.FILEINFO 结构如下,你可以将它复制粘贴到json.cn里,可以看得更清晰。
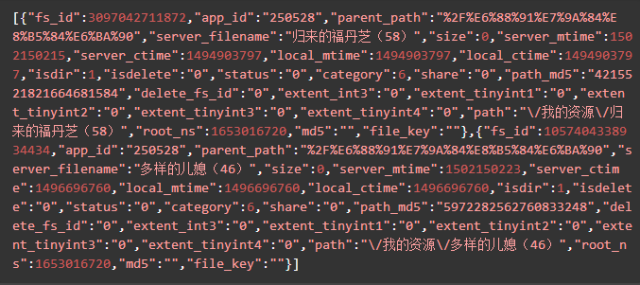
清楚了这三个参数的位置,我们就可以用正则表达式进行提取了。代码如下:
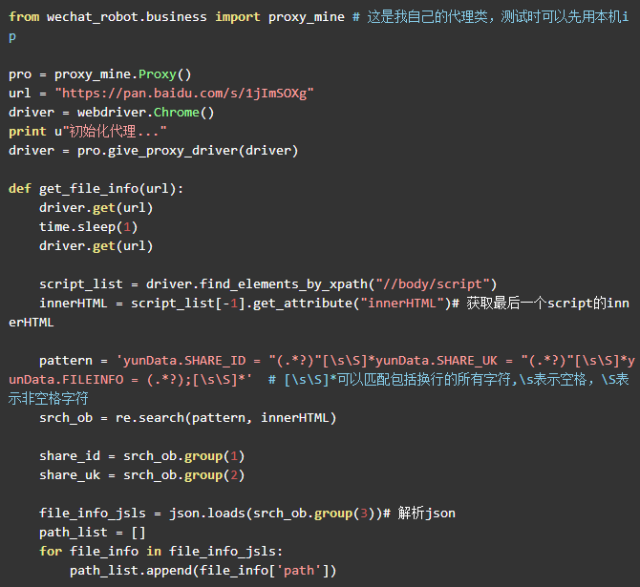
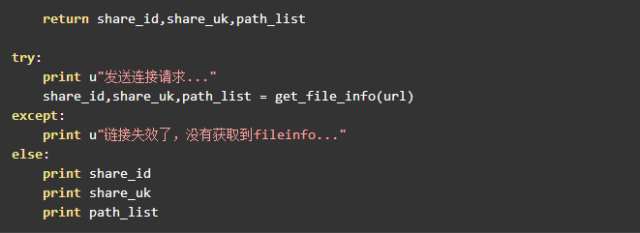
爬取到了这三个参数,就可以调用之前的 transfer 方法进行转存了。
-
python
+关注
关注
55文章
4779浏览量
84440 -
百度云
+关注
关注
0文章
53浏览量
7759
原文标题:Python爬虫实战:抓取并保存百度云资源(附代码)
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
百度地图离线API调用教程
Python数据爬虫学习内容
Python爬虫初学者需要准备什么?
0基础入门Python爬虫实战课
百度API调用(三)——语音识别 精选资料推荐
基于互联网云脑架构,对百度的未来发展趋势进行分析
百度正式推出百度云ABC 3.0,与各行业结合实现产业变革
百度Apollo高精定位方案分析
新基建时代 百度如何加速百度智能云发展
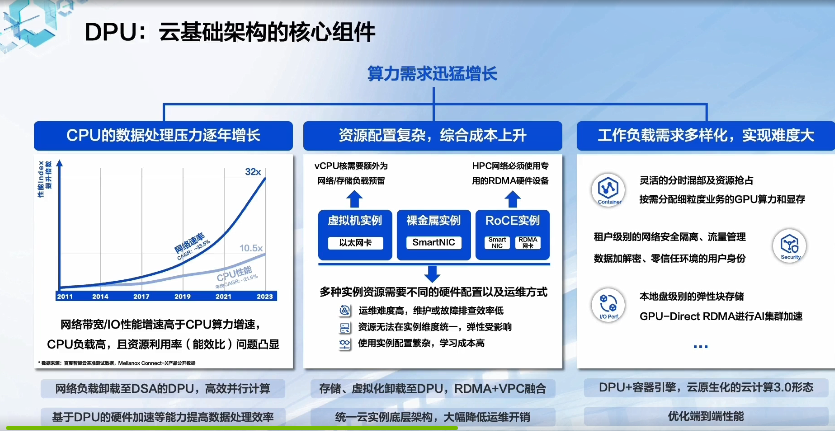
GTC 2023:百度智能云DPU落地实践





 工商网监
工商网监
评论