 分享下Kaiming大神在CVPR‘18 又有了什么新成果?
分享下Kaiming大神在CVPR‘18 又有了什么新成果?
一年一度的CVPR这就来了,各种前沿的、新奇的、惊人的成果又将给我们带来全新的认知。忍不住想去关注大神们的杰出工作,其中曾获得两次CVPR最佳论文的Kaiming是第一个想要检索的对象。在今年的主论坛上,共有四篇论文出现了Kaiming He的身影,他们分别是:
图像分割领域的:Learning to Segment Every Thing;
利用数据蒸馏的全向监督学习:Data Distillation:Toward Omni-Supervised Learning;
研究人与物互动:Detecting and Recognizing Human-Object Interactions;
一种非局域的神经网络结果:Non-Local Neural Netwroks。
(另一位著名的rbg大牛也是这四篇论文的共同作者>>http://www.rossgirshick.info/)
下面就让我们一起来学习这四篇论文中的精妙思想吧!

目标检测中最有趣的工作之一就是预测被检测物体的前景掩膜了,这项被称为实例分割的任务能将每个物体所包含的像素精确的预测出来。但在实际中的系统只包含了视觉世界的一小类物体,大约100中的目标分类限制了它的应用。这主要是由于先进的实例分割算法需要强监督样本进行训练。目前的训练数据类别有限而增添一个新类别的强监督实例分割样本十分耗时耗力。但另一方面,边界框标记的样本却十分丰富也容易获取。于是研究人员提出了一个想法:有没有可能不依靠完整的实例分割标记来生成对于所有类都有效的高质量分割模型呢?在这个想法的指导下,这篇论文引入了一种新的部分监督实例分割任务,并提出了一种新颖的迁移学习方法来解决这一问题。
这一新的半监督问题定义如下:1.训练数据中包含很多类对象,只有很小的子集类别拥有实例掩膜标注而其余只有边界框标记;2.实例分割算法需要充分利用这些数据来生成一个可以为数据集中所有类别预测实例分割的模型。由于训练数据是强标记(掩膜)和弱标记(边框)数据的混合,所以将这一任务称为部分监督学习。
部分监督任务最主要的优点在于可以通过对已有小类别掩膜标记数据和大类被边框标记数据的探索,建立大规模的实例分割模型,得以将在小类别上表现优异的先进模型拓展到上千个分类中去,这对于实际生活中的使用至关重要。
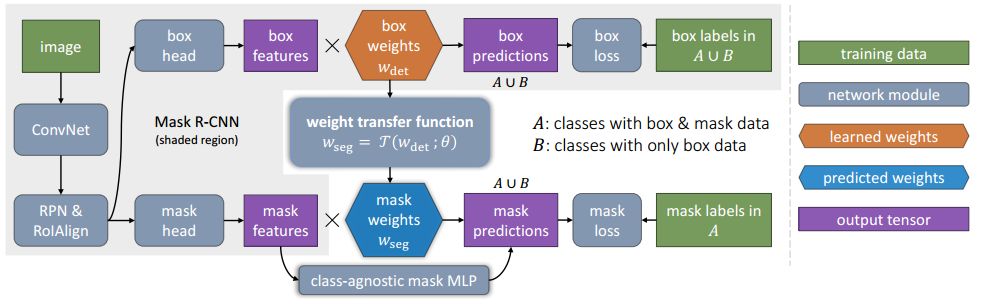
在具体实现过程中,基于Mask R-CNN提出了一种新颖的迁移学习方法。Mask R-CNN可以将实例分割问题分解为边框目标检测和掩膜预测两个子任务。在训练中分类信息会被编码到边框头单元中,就可以将这一视觉类别信息迁移到部分监督的掩膜头中去。其次,作者还提出了一个称为权重迁移函数的单元用于从边框参数预测出每一分类的分割参数。在预测时,它将用于对每一类物体预测实例分割的参数,包括在训练时没有掩膜标记的类别。
图中绿框表示拥有掩膜标记的类别和红框则表示只有边框标记,而后预测出掩膜的类别。
最终通过学习小类别中边框到分割的权重迁移函数,成功地通过混合数据的训练实现了部分监督学习,将强大的图像分割模型拓展到了3000类物体中。也开拓了非全监督条件下大规模实例分割的研究方向。
论文>>http://openaccess.thecvf.com/content_cvpr_2018/papers/Hu_Learning_to_Segment_CVPR_2018_paper.pdf

这篇文章同样是关于充分利用数据方面的工作,探索了一种称为全向监督学习的机制来使得模型尽可能的利用标记数据,并提供了潜在的无限制的无标记数据,它属于半监督学习的一个特殊领域。但目前大多数研究人员研究半监督问题主要从标记数据中分割出标记和未标记数据来模拟这样的数据集,这样的方法就决定了其上限是利用所有标记数据来实现的全监督学习。而全向监督学习则是利用所有的标记数据得到的精确结果作为模型的下限,来探索超越全监督学习基线的可能性。
这篇文章在模型精炼思想的启发下提出了数据精馏的方法来处理全向监督问题。首先了利用大规模标记数据训练的模型来为无标签数据创建标签;随后又将新得到的标签数据与原数据一起训练新的模型。为了避免模型预测的数据标签没有意义,研究人员利用的单个模型对不同变换后(翻转和尺度变换)未标记数据进行处理并组合了它们的结果,通过数据变化来增强单个模型的精度。
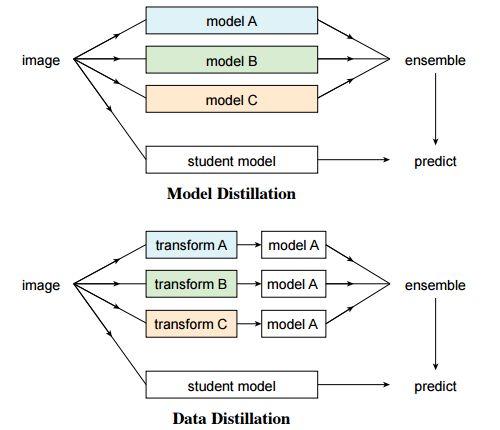
实验证明这样的变换可以提供不寻常的信息。换句话说,和利用多个模型来精炼知识的预测方法相比,这种方法通过单个模型在不同变化下的非标签数据中进行了数据精馏。
由于全监督学习模型的飞速发展,目前的模型产生的错误越来越少,对于未知数据的预测结果也越来越可信。所以数据精馏无需改变识别模型,并且可以用于规模化的处理大规模未标记数据。
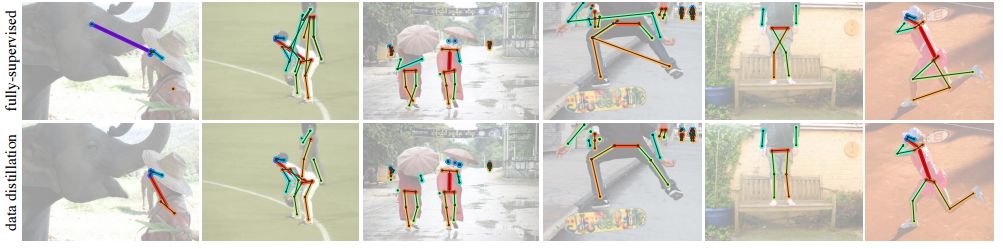
为了验证对于全向监督学习的数据蒸馏是否有效,在COCO数据集上对人体关键点检测任务进行了测评。通过原始标记的COCO数据集和连一个大规模非标记数据集(Sports-1M)进行数据精馏并训练了Mask R-CNN模型。
通过模型对未标记数据生成的标注
通过对未标记数据的精馏,研究人员观察到了留存验证集上精度的明显提升:对于基准Mask R-CNN提升了2个点AP;作为参考的是利用相同数据量的手工标记数据得到了近3个点的提升,这说明利用本文的方法是有希望利用未标记数据提高模型表现的。
利用数据精馏实现的结果
总结一下,本文主要探索了利用全向监督学习(omni-supervised)的方法超越大规模全监督学习的可能性,利用所有的监督数据与非监督数据的精馏来实现提升。
论文>>http://openaccess.thecvf.com/content_cvpr_2018/papers/Radosavovic_Data_Distillation_Towards_CVPR_2018_paper.pdf

第三篇文章提出了一种以人为中心的思想,通过图像中出现的人作为一个强大的线索来定为与之交互的对象,并基于这个想法开发了称为InteractNet的模型,检测<人、动作、对象>三元组,实现人与物之间交互的检测与识别。
在视觉任务中,理解图像中发生了什么除了检测出其中的对象,还需要识别出对象间的关系,这篇文章主要集中与解决人与物的交互。识别人与物之间的交互关系可以被表示为检测<人、动作、对象>三元组的过程。在互联网的图片中有很大部分包含了人物,所以以人为中心的理解具有很大的现实意义。事实上在研究者看来,图片中的任务提供了丰富的动作信息,并衔接了与其发生交互的物体。但对于细粒度的人体行为及其交互的多种类的对象识别比起单纯的对象检测来说还面临着一系列挑战。
研究人员们发现图片中的人物的行为和姿态中包含了大量与之交互物体的位置信息,所以基于这一前提相关物体的搜索范围可以大大缩小。虽然每幅图像中会检测大大量物体,但由人体预测的目标位置可以帮助模型迅速地找到与特定动作相关的目标物体。研究人员把这一想法称为“以人为中心”的识别,并利用Faster R-CNN框架进行了实现。
具体来说,在与人物相关的ROI中,这个分支实现了行为分类和对行为目标物体的密度估计。密度估计器生成一个四维的高斯分布,对于每一种行为模型将会把目标对象的位置与人物联系起来。这个以人为中的识别分支与另一个简单的对偶交互分支一起组成了多任务的学习系统,并可以联合优化。
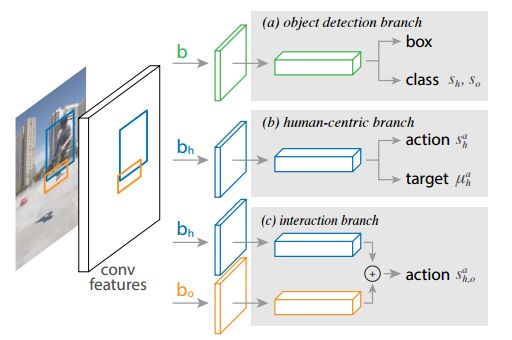
基于faster R-CNN的三分支架构
作者最后在V-COCO数据集上进行了测评,实现了26%的AP(31.8to40.0)提升,这主要来自于利用与人物相关的目标位置。同时这一称为InteractNet的模型在HICO-DET数据集上实现了27%的提升。在复杂任务中达到了135ms/image的速度,具有潜在的实用性。
与动作相关目标区域的估计
一些结果展示
想了解实现的细节,请看论文中的具体描述:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Gkioxari_Detecting_and_Recognizing_CVPR_2018_paper.pdf

第四篇论文提出了一非局域化的操作单元来获取长程的依赖信息。在这种构建单元的帮助下,模型可以在视频分类任务和静态目标检测任务中得到十分优异的表现。
在深度神经网络中长程依赖性的抓取是十分重要的,对于序列数据来说一般采用递归操作来实现,而对于图像数据则主要通过深层卷积操作的堆叠而实现大感受野来实现。但卷积和递归操作主要用于处理时空局域信息,所以长程(大范围)依赖性只能通过重复的操作,逐步传播信号来获取。这样的重复操作会带来一系列局限性:首先是计算效率低;其次导致了优化困难;最后这样的方法使得处理不同节点间信息来回传输的多次反射依赖模型变得十分困难。
为了克服这些困难,在这篇文章中作者提出了一种非局域的操作,作为高效、简便、通用的模块用于深度神经网络来抽取长程依赖性。这种操作是传统非局域化均值操作的泛化,它通过加权输入特征图的所有位置特征来计算某一位置的响应,而这些位置可以是空间、时间或者是时空相关的,所以它适用于图像、序列和视频信号的处理。
非局域操作的优点有以下三个方面:首先与卷积和递归的逐渐传播过程相比,非局域操作可以直接通过计算位置间的相互作用来抓取长程特征;其次高效率的操作在少数几层的模型下也能取得很好的结果;最后它可以适应变化大小的输入并便捷地集成到其他操作中去。
在视频中像素具有时空上的长程相关性,单个非局域单元可以直接在前馈中抓取这些时空相关性。通过少数几个非局域单元构建的非局域神经网络来对视频进行处理其精度要优于传统的2D/3D卷积网络。同时,非局域神经网络相比于3D卷积计算更经济。
其数学表示如下:
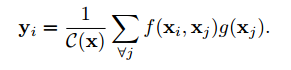
x为输入信号(图像、视频、序列、特征等)y为相同大小的输出信号,i表示输出结果中位置i的索引,它由所有可能位置j的响应结果来计算。其中f用于计算位置ij之间的关系,而g用于计算输入信号在位置j出的表示。C表述响应的归一化函数。
其构成的空时计算单元结构如下图所示:
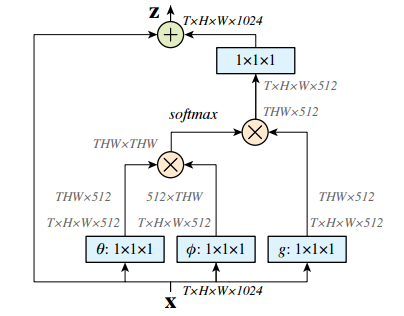
其中输入为特征张量,其中g可以通过1*1卷积实现,而计算相关性的函数可以由高斯和embedded高斯来实现。这里使用softmax来进行归一化。具体实现请参看论文,其中描述了公式中的每一步包括f的点乘、相互联系等方式的实现,以及非局域化单元的实现。
在Kinetics和Charades数据集中,仅仅使用RGB图像而不使用各种花哨的技巧,这种方法就能得到与当前最好算法相比拟(甚至更好)的结果。同时在COCO数据集上这种方法可以提高目标检测、分割和位姿估计三个任务的精度,而只需要引入很少的而外计算。对于视频和图像的处理证明非局域化操作具有通用性,并将成为深度网络的基本构建单元。
论文>>http://openaccess.thecvf.com/content_cvpr_2018/papers/Wang_Non-Local_Neural_Networks_CVPR_2018_paper.pdf
除此之外,Kaiming还将在今年的CVPR上带来名为Visual Recognition and Beyond的教程,内容包括视觉识别的前沿研究领域及其在高级任务中的应用。Kaiming,Ross Girshick,Alex Kirillov将从不同角度阐述图像分类、目标检测、实例分割和语义分割后支撑的方法和原理,而后Georgia Gkioxari和Justin Johnson将会在两个报告中探索基于行为和推理视觉识别的新任务。感兴趣的小伙伴可以关注:
https://sites.google.com/view/cvpr2018-recognition-tutorial
http://kaiminghe.com/
另外,从Facebook Research的网站查询后发现,几年CVPR共接收其论文28篇,除了上述四篇外,各领域文章如下,有兴趣的小伙伴可以进行更深入的学习。(点击图片放大)

-
神经网络
+关注
关注
42文章
4789浏览量
101751 -
图像分割
+关注
关注
4文章
182浏览量
18111 -
数据集
+关注
关注
4文章
1215浏览量
25061
原文标题:蹭热度 | 梳理下Kaiming大神在CVPR‘18 又有了什么新成果?(赠论文下载工具)
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
北斗在列 中国八大神器震惊全球
中国在量子科技领域又有新突破!
ProbeRequest是什么 它又有什么作用
lsh_tracking_cvpr2013英文版资料
国外大神恶搞iOS10.2.1-10.3越狱, 看的人差点就信了!
大神F2联通版性能怎么样
62篇论文入选十年来最难CVPR,商汤研究再创佳绩
AI观察室(三)|顶会推荐!获选CVPR oral paper的Xilinx AI研发团队最新成果揭秘
CVPR 2021华为诺亚方舟实验室发表30篇论文 |CVPR 2021

CVPR2020 | 对数字屏幕拍照时的摩尔纹怎么去除?
CVPR2020 | MAL:联合解决目标检测中的定位与分类问题,自动选择最佳anchor
深兰团队已连续5年在CVPR挑战赛中斩获冠军
高通在2023年国际计算机视觉与模式识别会议上,展示先进研究成果并将生成式AI引入边缘侧






 工商网监
工商网监
评论