 Abhay Pawar总结的进入Kaggle2%的技巧
Abhay Pawar总结的进入Kaggle2%的技巧
编者按:Kaggle竞赛对很多数据科学爱好者来说都不陌生,今天论智君为大家带来Abhay Pawar总结的进入Kaggle2%的技巧。以下是对原文的编译。
过去几年,我创建了很多研究特征并建立更好地机器学习模型的方法。这些简单强大的技巧帮我在Instacart Market Basket Analysis竞赛中得到了前2%的名次,不单单在竞赛中,这些技巧在其他任务中也运用到了。
用数字数据创建任何监督式学习模型中,最重要的一个方面就是完全理解特征。观察模型的partial dependence plot可以帮助了解模型在任意特征下的输出变化。
但是,这些图存在的问题是,它们都需要用经过训练的模型创建。如果我们能直接从训练数据中创建图形,就更有助于了解数据。事实上,它能帮助我们做以下工作:
理解特征
辨别噪声特征(这是最有趣的部分!)
处理特征(feature engineering)
特征重要性
特征debugging
泄漏检测和理解
模型监控
为了更易于使用,我会在本文中用一个名为featexp的Python包表示出来,同时会讲解它是如何用于特征研究的。我们将利用Kaggle上的Home Credit Default Risk竞赛中的数据集,该竞赛的任务是根据数据预测信用违约者。
1. 特征理解
如果因变量(目标变量)是二元的,所有的点要么分布在0,要么分布在1,散点图是无法工作的。对于连续的目标,数据点太多会难以理解目标和特征趋势。但是Featexp可以解决这一问题,创建更好的散点图。让我们试试吧!
from featexp import get_univariate_plots
# Plots drawn for all features if nothing is passed in feature_list parameter.
get_univariate_plots(data=data_train, target_col='target',
features_list=['DAYS_BIRTH'], bins=10)
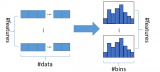
特征 vs. 目标的散点图
Featexp首先用横轴的数字特征创建人口,之后计算每段人口上目标的平均值,然后作为竖轴。在我们的案例中,目标平均值指的是违约率。散点图表示,DAYS_BIRTH负值越大(年龄越大),违约率越低。这比较好理解,因为年轻人更容易委员。这一折线图帮助我们了解了特征所反映的顾客特点,以及它是如何影响模型的。右侧的图表展示了每一阶段人口所含的顾客数量。
2. 辨别噪声特征
噪声特征会造成过度拟合,所以辨别它们时有一定难度。在featexp中,你可以输入一个测试集(或验证集),比较在训练或测试中的特征趋势,来确定噪声。
get_univariate_plots(data=data_train, target_col='target', data_test=data_test, features_list=['DAYS_EMPLOYED'])
训练和测试中的特征趋势比较
Featexp通过两种尺度计算出图中结果:
趋势相关性(在测试图中):如果特征在训练和验证集上并没有表现出相同的趋势,就有可能导致过度拟合。因为模型学习的东西并不能应用于测试数据中。趋势相关性能帮助我们了解训练趋势和测试趋势之间的相似程度。而上述特征有99%的相关性,说明并无太多噪声。
趋势变化:趋势方向突然和重复的改变都有可能暗示特征的出现,但是这类特征的改变也可能会因为其他特征上每组人数不同而产生。所以,违约路不能与其他组相比较。
下方的特征图由于没有同样的趋势,所以相关性为85%。这两个尺度可以用来减少噪声特征。
当特征较多时,减少趋势相关特征非常容易,因为它们互相连接。这会导致更少的过度拟合,其他相关特征会避免信息损失。另外,要注意不要丢掉过多重要的特征,因为这可能导致性能下降。同时,你不能用特征重要性辨别噪声,因为它们也很重要。
利用不同时间点中的测试数据结果会更好,因为这样可以验证特征趋势是否会随时间而改变。
Featexp中的gettrendstats()函数会为每个特征返回一个带有趋势相关性和变化的数据框架。
from featexp import get_trend_stats
stats = get_trend_stats(data=data_train, target_col='target', data_test=data_test)
让我们试试在数据中减少低相关性的特征,看看结果会如何变化:

不同特征选择的AUC
可以看到,从越高的趋势相关性开始减少特征,排行榜上的AUC就越高。保留重要特征后,AUC分数提升到了0.74。有趣的是,测试AUC并不如LB AUC变化的多。完整代码:github.com/abhayspawar/featexp/blob/master/featexp_demo.ipynb
3. 特征处理
通过观察图表,可以创建更好的特征;了解掌握数据,可以进行更好的特征工程处理。但是除此之外,这些工作还能让你改进现有的特征。让我们看看另一个特征EXT_SOURCE_1:
EXT_SOURCE_1值越高的顾客,违约率越低,但是,第一组数值(约有8%)的违约率,并不足讯这一特征趋势,它的负值约为-99.985,并且其中的人数非常多。这可能表明其中有特殊值,所以不符合整体规律。不过非线性模型在学习这类关系时不会受阻,但是对于线性回归这类的线性模型,在含有如此特殊值和null值的情况下,应该输入有着相同违约率的值,而不是简单地输入平均值。
4. 特征重要性
Featexp还能帮你估算特征重要性。DAYSBIRTH和EXT_SOURCE_1都展现出较好的趋势。但是EXT_SOURCE_1中的人数大多集中在一个特殊的组中,这有可能表明它并不如DAYSBIRTH重要。我们用XGBoost模型的特征重要性验证后的确符合这一结论。
5. 特征debugging
观察Featexp的散点图,有助于在复杂特征工程代码中找出bug,你只需做两件事:
检查特征的人数分布是否正确。
在呈现在散点图之前,先自己预测特征趋势是怎样的,如果和自己估计的相差较大,就有可能存在问题。这种预测过程在搭建机器学习模型时非常有趣!
6. 泄漏检测
数据从目标泄漏到特征可能会导致过度拟合,泄露特征具有很高的特征重要性,但是想要了解某一特征中泄漏为什么会发生具有一定难度,不过通过Featexp图表可以帮助你理解。
在下方的图中,“Null”一栏中的违约率是0%,其他数值都是100%。很显然,这是泄漏发生的极端情况。只要当客户违约,特征才会有一个数值。产生这种情况的原因可能是bug的存在,或者实际只针对违约者进行的特征计算(在这种情况下会降低)。弄清楚泄露特征的问题才能使debug的速度加快。
7. 模型监控
由于Featexp可以计算两个数据及之间的趋势关系,它也可以用来监控模型。每次当模型重新训练后,新的训练数据可以和经过测试的训练数据相比较。趋势之间的关系可以帮你监控,当特征中某处发生变化,它和目标的关系有何改变。
结语
这些简单技巧帮助我在现实和Kaggle上搭建了更好的模型,只需要15分钟,就能用Featexp创建清晰明了的模型,让我们对数据和模型特征了解更多。
-
机器学习
+关注
关注
66文章
8420浏览量
132680 -
数据集
+关注
关注
4文章
1208浏览量
24711
原文标题:我进入Kaggle前2%的秘密——Featexp
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Kaggle机器学习/数据科学现状调查

机器学习特征选择方法总结
Kaggle没有否认将被谷歌收购
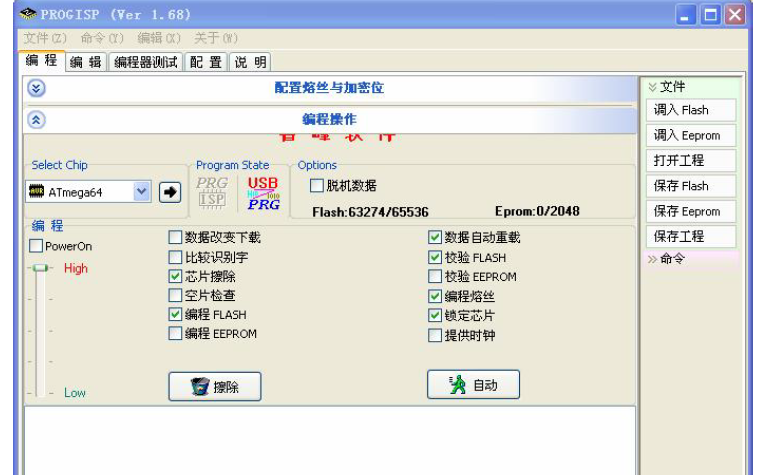
AT烧录软件Progisp和使用手册和对于ISP编程进入不了编程模式的总结
如何很容易地将数据共享为Kaggle数据集

腾讯宣布其人工智能球队获首届谷歌足球Kaggle竞赛冠军
Kaggle神器LightGBM的最全解读






 工商网监
工商网监
评论