 2019年冬季CS224N最新课程:基于深度学习的自然语言处理
2019年冬季CS224N最新课程:基于深度学习的自然语言处理
本笔记基于斯坦福大学2019年冬季CS224N最新课程:基于深度学习的自然语言处理,希望可以接触到最前沿的进展。
主要内容
这一节主要讨论自然语言处理中的旗舰任务:机器翻译。
神经机器翻译之前机器翻译早期机器翻译:1950s统计机器翻译:1990s-2010s对齐很复杂对齐学习SMT解码SMT特点神经机器翻译序列到序列模型用途广泛条件语言模型NMT训练贪心解码穷举搜索解码柱搜索解码终止条件最终修正NMT优点NMT缺点机器翻译评测机器翻译进展NMT仍然存在问题NMT研究仍在继续注意力序列到序列的瓶颈问题注意力注意力很厉害注意力应用广泛注意力变体下节预告阅读更多
神经机器翻译之前
讲神经机器翻译之前,先来看看机器翻译的历史。
机器翻译
机器翻译任务是将一种语言(原始语言)的句子x翻译成另一种语言(目标语言)的句子y。
例如:
x: L'homme est né libre, et partout il est dans les fers
y: Man is born free, but everywhere he is in chains
早期机器翻译:1950s
机器翻译研究始于1950年初。
1954 年,美国乔治敦大学(Georgetown University) 在 IBM 公司协同下, 用 IBM-701计算机首次完成了英俄机器翻译试验,向公众和科学界展示了机器翻译的可行性,从而拉开了机器翻译研究的序幕。
中国开始这项研究也并不晚, 早在1956年,国家就把这项研究列入了全国科学工作发展规划,课题名称是“机器翻译、自然语言翻译规则的建设和自然语言的数学理论”。1957 年,中国科学院语言研究所与计算技术研究所合作开展俄汉机器翻译试验,翻译了9 种不同类型的较为复杂的句子。
早期机器翻译大都基于规则,并使用双语词典。
统计机器翻译:1990s-2010s
核心思想:从数据中学习概率模型。
假定翻译方向是从法语到英语。
给定法语句子x,那么目标就是找到最佳英语句子y:
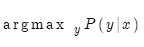
也就是找到概率分布P。
通常的做法是使用贝叶斯法则,将上式分解成两项,便于分别学习: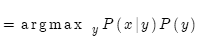
其中:
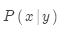 是翻译模型,是关于词语和短语如何翻译的模型,考查的是忠实度。翻译模型从平行数据中学习;
是翻译模型,是关于词语和短语如何翻译的模型,考查的是忠实度。翻译模型从平行数据中学习;
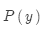 是语言模型,是关于如何书写正确英语的模型,考查的是流畅度。语言模型从单语数据中学习。之前已经学过。
是语言模型,是关于如何书写正确英语的模型,考查的是流畅度。语言模型从单语数据中学习。之前已经学过。
那么如何学习翻译模型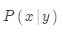 ?
?
首先需要平行语料库。
举世闻名的罗赛塔石碑就是一个早期的平行语料库。
罗赛塔石碑
在这个石碑上,同一文本被书写成了三种语言。而这恰恰成了19世纪人们破解古埃及文的关键。如果你在伦敦,不妨亲自去大英博物馆看一看这个平行语料库。
当然,我们需要的平行语料库要大得多,远非一块石碑所能写下。
有了大规模平行语料库后,如何从中学习翻译模型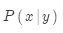 ?
?
方法是进一步分解。实际上我们希望考虑:
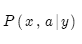
其中a是对齐,即法语句子x和英语句子y之间的词语对齐。
所谓对齐就是句对之间词语的对应。
对齐很复杂
无对应
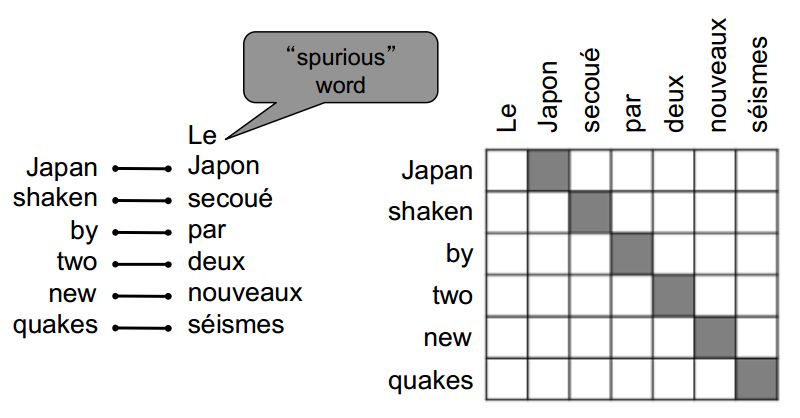
无对应
多对一
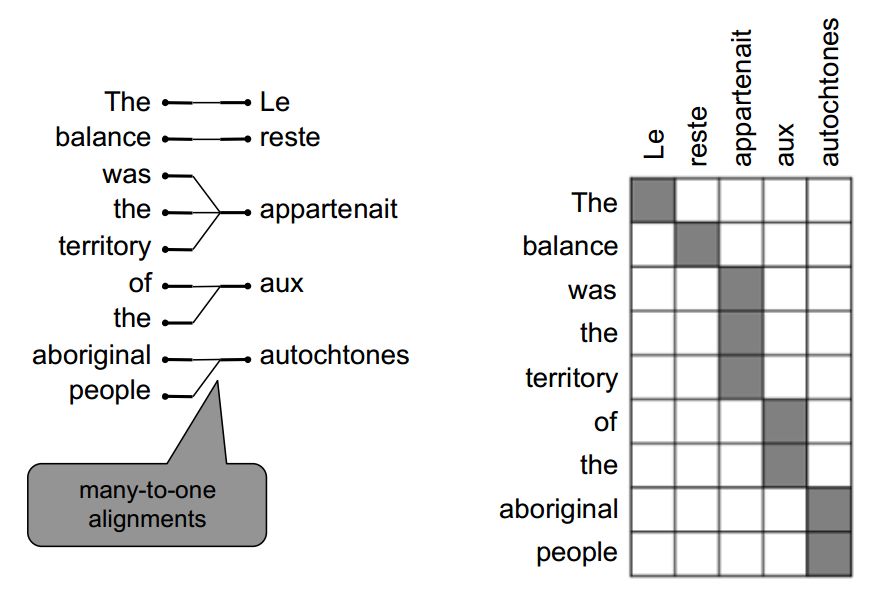
多对一
一对多(这样的词称为能产词)
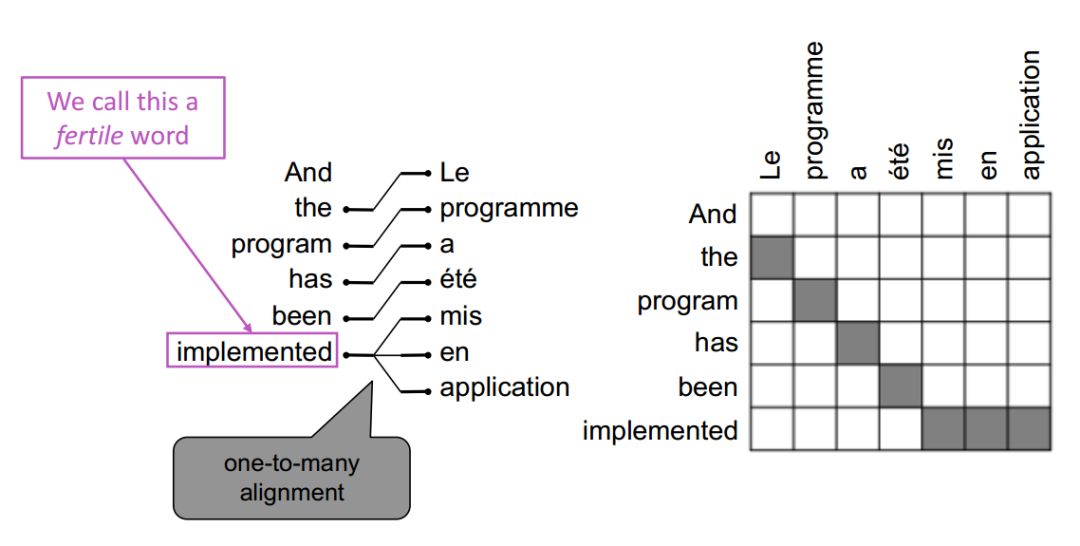
一对多
一对很多
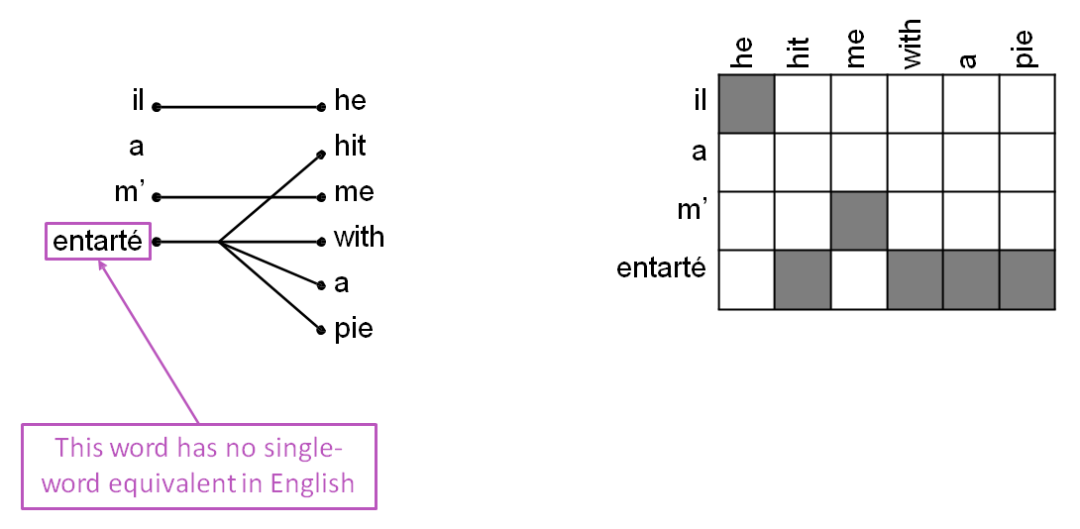
一对很多
多对多(短语对齐)
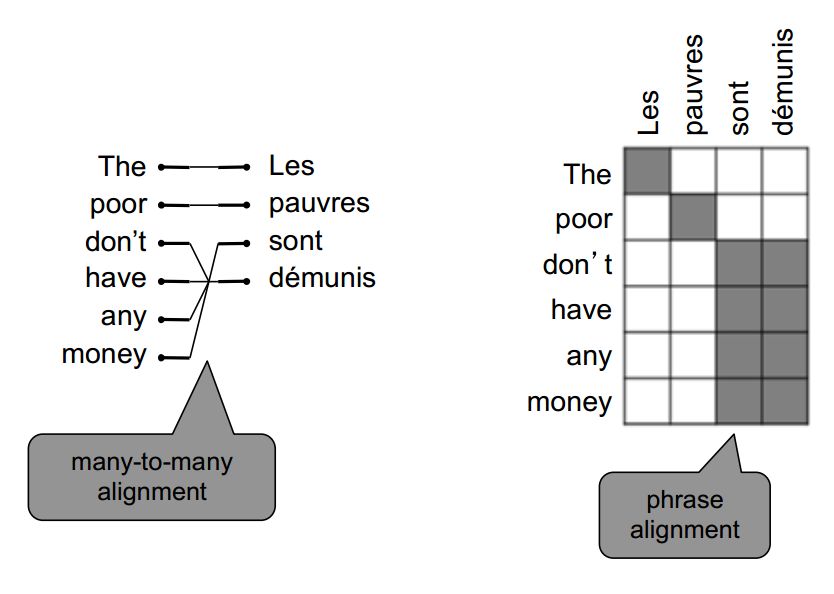
多对多
对齐学习
学习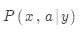 就是学习多种因素的组合,包括:
就是学习多种因素的组合,包括:
词语对齐的概率(同时取决于词语在句子中的位置)
词语具有特定能产度(对应词的个数)的概率
等等
所有这些都是从平行数据中学习。
SMT解码
有了翻译模型和语言模型后,如何计算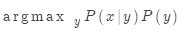 ?
?
一种暴力解法就是枚举每一个可能的y,然后计算概率。很明显,这样做的计算代价非常高。
解决办法:使用启发式搜索算法找到最佳翻译,忽略掉概率非常低的翻译。
这一过程称为解码。
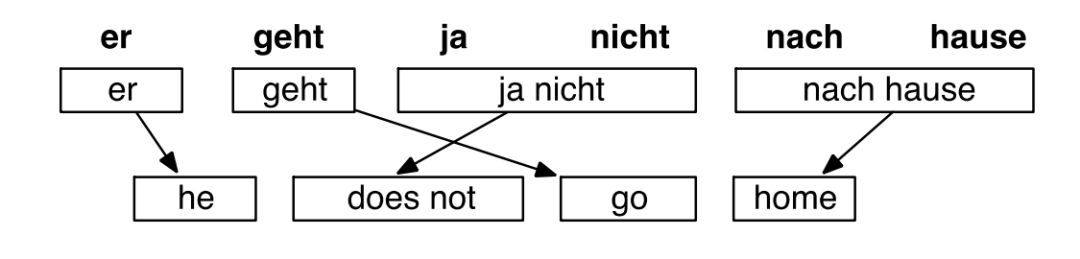
SMT示例
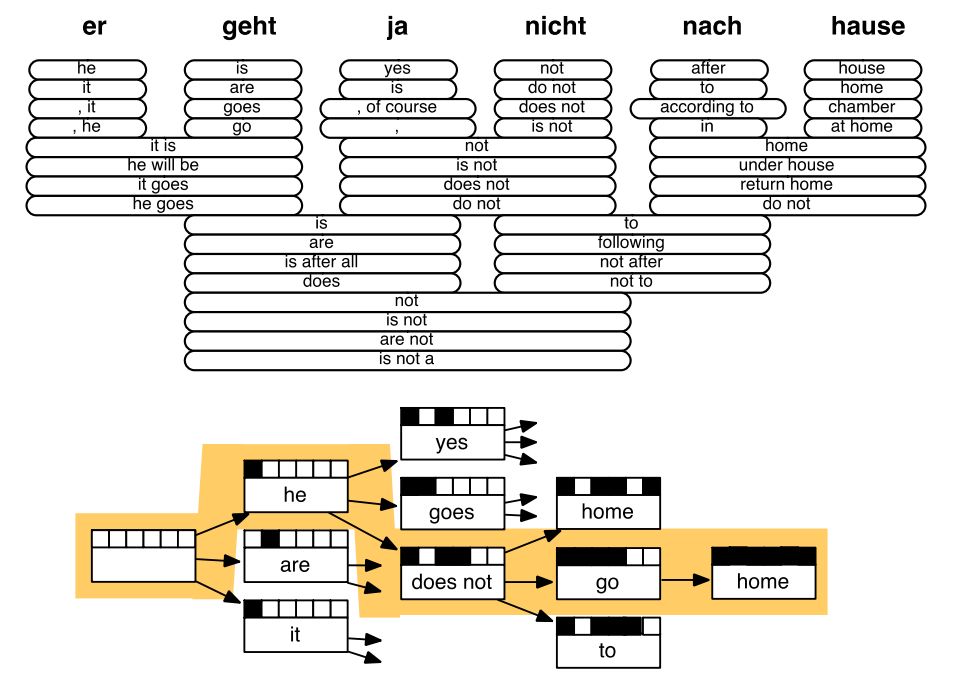
SMT解码示例
SMT特点
曾经是个非常热门的研究领域
最好的系统都极其复杂
有很多单独设计的子系统
大量的特征工程
需要收集和整理大量的外部资源,例如平行短语表
需要大量人力维护
直到2014年,神经机器翻译横空出世!
神经机器翻译
神经机器翻译(NMT)是一种只使用神经网络做机器翻译的方法。
这种神经网络称为序列到序列结构(seq2seq),包括两个RNN。
序列到序列模型
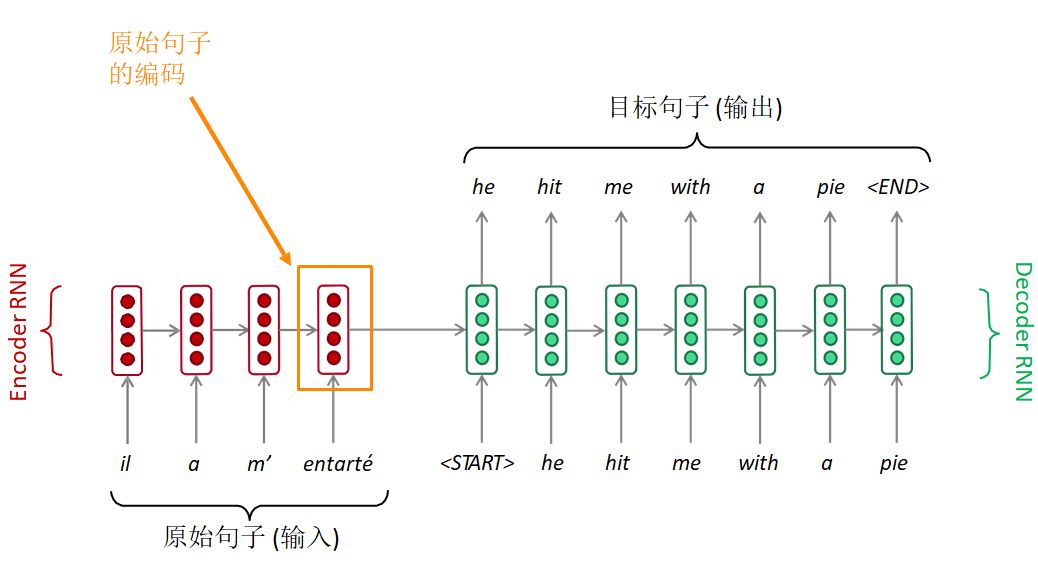
序列到序列模型由两个RNN组成:编码器RNN和解码器RNN。
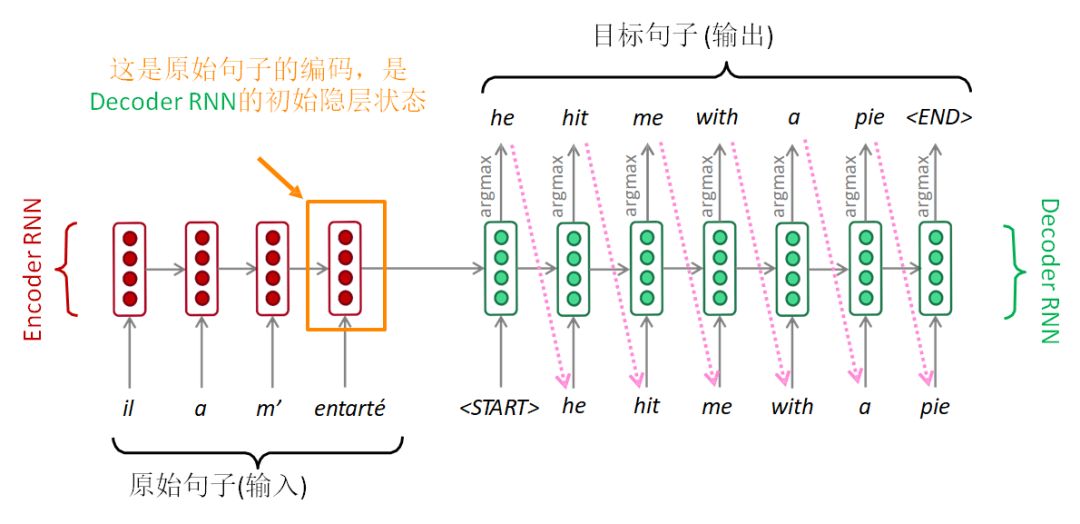
Seq2Seq
编码器RNN通过最后的隐层状态对原始句子进行编码。原始句子的编码就是解码器RNN的初始隐层状态。这相当于将原始句子编码传入解码器RNN。
解码器RNN相当于语言模型,根据前面的编码一步一步来生成目标句子。
注意:上图显示的是测试模型,解码器的输出作为下一步的输入,进而生成文本。
另外,每种语言各有一个单独的词表和词嵌入。
用途广泛
序列到序列模型不仅仅用于机器翻译。很多其他NLP任务本质上也是序列到序列。
摘要生成(长文本-->短文本)
对话(上一句话-->下一句话)
句法分析(输入文本-->输出句法分析序列)
代码生成(自然语言-->Python代码)
条件语言模型
序列到序列模型属于条件语言模型。
说它是语言模型,因为解码器所做的就是预测目标句子y的下一个词
说它是条件的,因为解码器的预测是以原始句子x为条件的
NMT的强大之处在于它直接计算概率P(y|x):
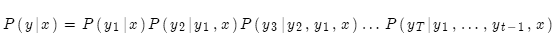
即给定原始句子x和当前所有的目标词语,计算下一个目标词语。
NMT训练
如何训练一个NMT系统?
首先要有一个大的平行语料库。
将原始句子送入编码器RNN,然后将目标句子送入解码器RNN,同时编码器RNN最终隐层状态会传入解码器RNN的初始隐层状态。在解码器RNN的每一步会产生下一个单词的概率分布,进而通过交叉熵计算损失。将每一步损失加总取平均,就得到了整个句子的损失。
如下图所示:
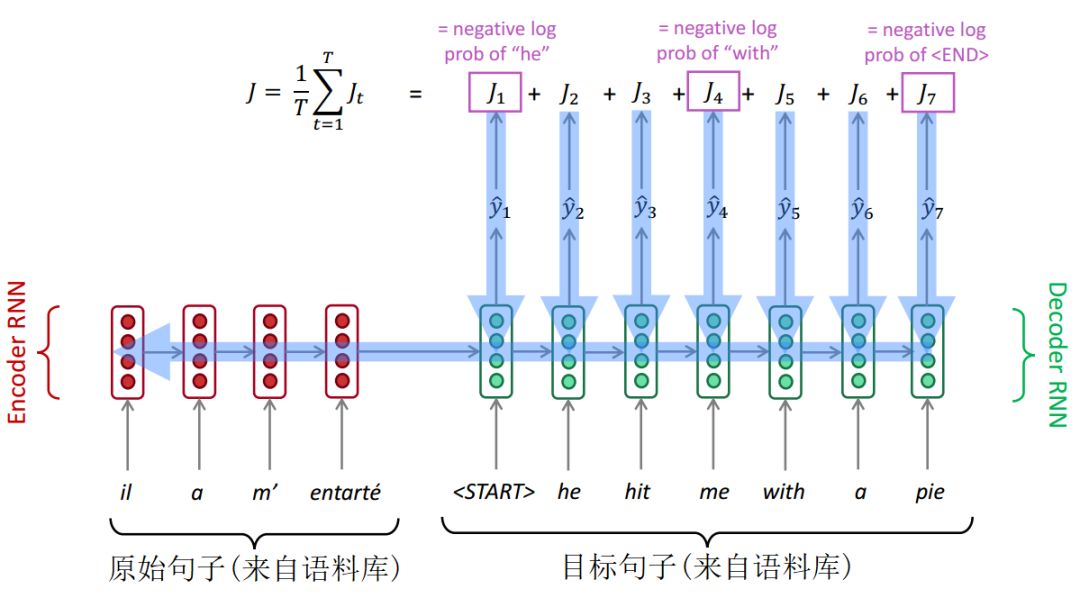
NMT训练
Seq2Seq作为整个系统进行优化。反向传播方式为"端到端",一端连接最终损失,一端连接编码器RNN的开始。反向传播穿过了整个系统。
注意,训练期间,解码器的输入来自语料库。解码器每一步的输出仅仅用于计算损失,不会送入下一步输入。
贪心解码
我们看到,对解码器的每一步输出求argmax,就能生成(或解码)目标句子。
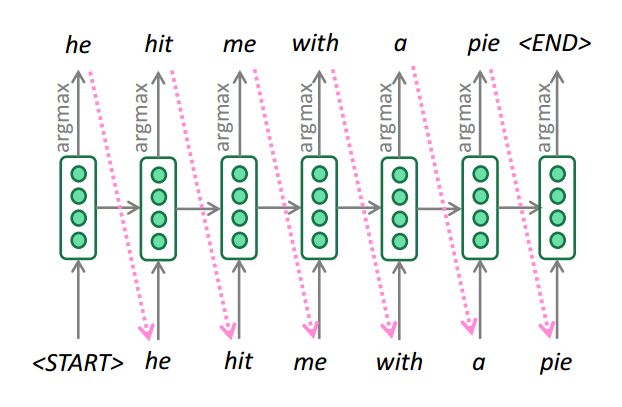
贪心解码
这就是贪心解码(在每一步取概率最高的词)
贪心解码的问题是每一步取概率最高的词并不必然导致整个句子概率最高!
贪心解码无法取消上一步决策。
例如,输入是il a m’entarté (he hit me with a pie )
he_
he hit_
he hit a___
糟糕!解码到第3步时,概率最高的词是a,这不是想要的结果,现在想回到上一步,怎么办?
这就是贪心解码的问题,无法返回上一步。
穷举搜索解码
我们的目标其实是找到使下述概率最大的翻译y(长度T):
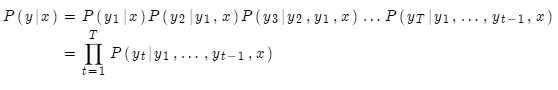
我们可以计算所有可能的序列y,这意味着解码器在每一步t,都要追踪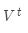 个可能的未完成翻译。计算代价非常高。我们需要高效的搜索算法。
个可能的未完成翻译。计算代价非常高。我们需要高效的搜索算法。
柱搜索解码
核心思想:在解码器的每一步,只追踪k个概率最高的翻译(亦称为假设)。k就是柱搜索的大小(一般是5-10)。
我们使用对数概率作为假设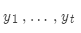 的分值:
的分值:
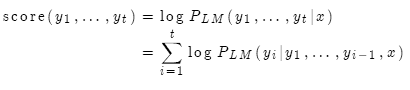
分值都是负数,数值越大越好。我们只搜索分值高的假设,在每一步,只追踪前k个。

柱搜索解码
柱搜索不能保证找到最优解,但效率要远远高于穷举搜索。
终止条件
在贪心搜索中,解码的终止条件是
例如:
在柱搜索中,不同的假设可能会在不同的时间步产生
如果一个假设已经产生
继续通过柱搜索探索其他假设。
通常,柱搜索的终止条件是:
达到时间步T(T是事先预定的数值)
已经得到至少n个完整的假设(n是事先预定的数值)
最终修正
现在我们有了完成的假设列表。如何选择分值最高的一个?
列表中每一个假设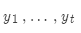 都有一个分值
都有一个分值
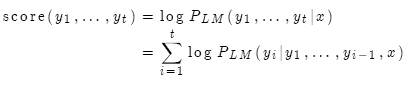
问题在于假设越长,分值越低。
修正:用长度作归一化。
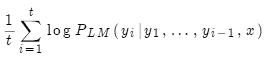
NMT优点
与SMT相比,NMT具有很多优点:
效果更好
更流畅
更充分利用上下文
更充分利用短语相似度
单个神经网络,端到端优化
无须针对子系统进行逐个优化
人工参与更少
无特征工程
适用于所有语言对
NMT缺点
与SMT相比:
NMT可解释性差
难以调试
NMT难以控制
无法指定翻译规则或原则
安全问题
机器翻译评测
目前比较流行的自动评测方法是IBM提出的BLEU(bilingual evaluation understudy)算法。
BLEU的核心思想就是机器翻译的译文越接近人工翻译的结果,它的翻译质量就越高。BLEU如何定义机器翻译与参考译文之间的相似度?
n元文法精度(通常是一、二、三、四元文法)
对过于简短的译文作惩罚
BLEU非常有用,但并非完美无缺
一句话有多种有效的翻译方式
如果与人工翻译的n元文法重叠度低,即使翻译再好,BLEU也会偏低
机器翻译进展
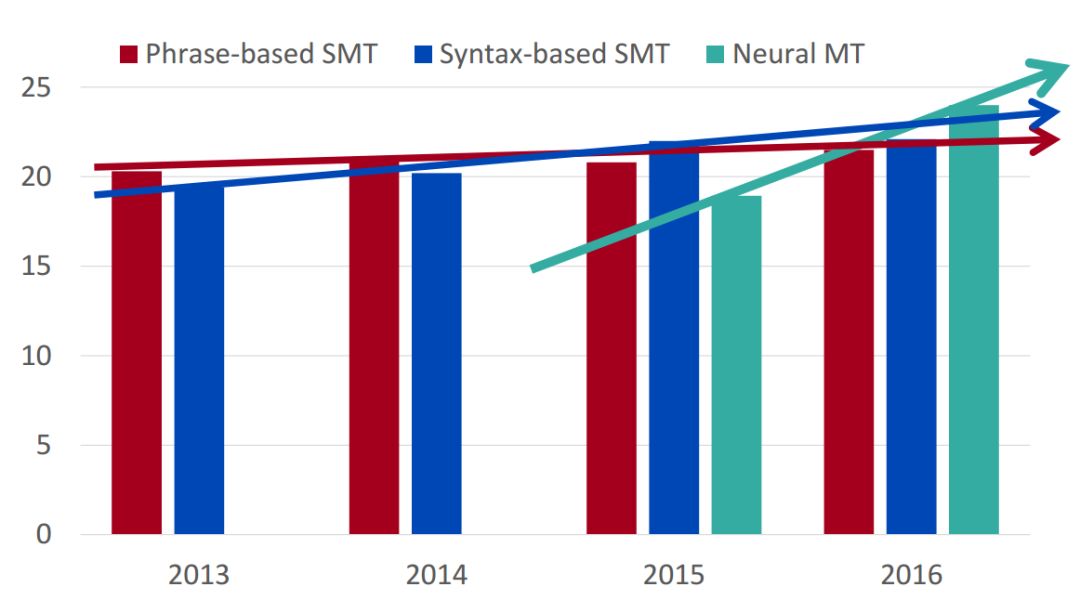
机器翻译进展
2014年,神经机器翻译只是非常边缘的研究范畴;但在2016年,神经机器翻译已经成为主流的标准方法。
2014年,第一篇seq2seq论文发布
2016年,谷歌翻译从SMT切换到NMT
仅仅两年,NMT实现惊人逆袭!
SMT系统,需要数以百计的工程师,经年累月,方能搭建;而NMT系统,只需几个工程师几个月内就能搭建,而且效果反超SMT。
NMT仍然存在问题
NMT虽然大获成功,但仍然存在很多问题:
未登录词
训练数据和测试数据领域不匹配
长文本上下文问题
有些语言对数据量不够
利用常识仍然困难

没有常识
NMT学到了数据中的偏见
数据偏见
不可解释的系统会做一些莫名其妙的事情
不可解释
NMT研究仍在继续
NMT是深度自然语言处理的旗舰任务。
NMT研究引领了NLP深度学习的很多创新
2019年,NMT研究仍在蓬勃发展
研究人员发现了上面标准seq2seq的很多改进方法,其中有一项改进如此不可或缺,已经成为新的标准方法。那就是Attention(注意力)
注意力
序列到序列的瓶颈问题
信息瓶颈问题
在编码器RNN的最后一步,这里的隐层状态需要获得原始句子的所有信息。这就存在信息瓶颈的问题。
注意力
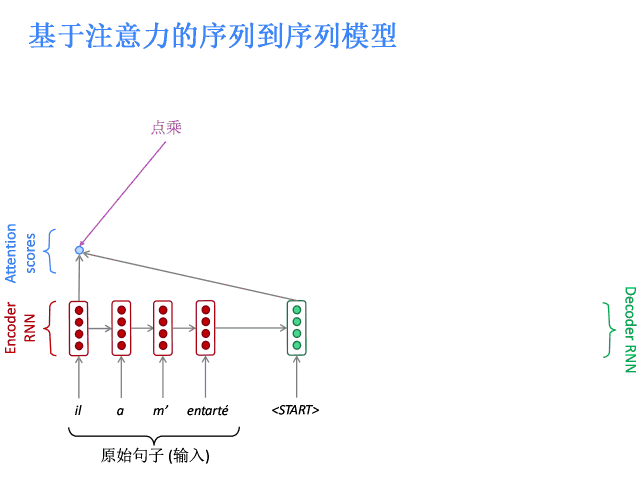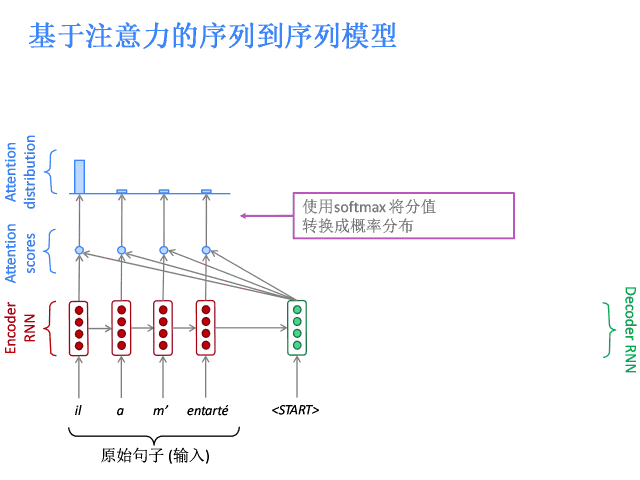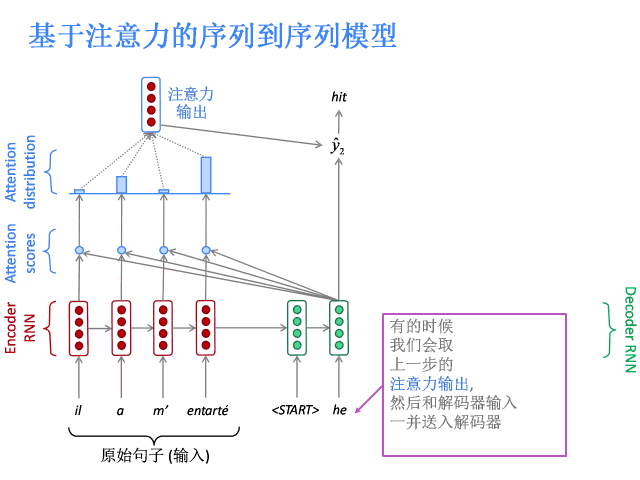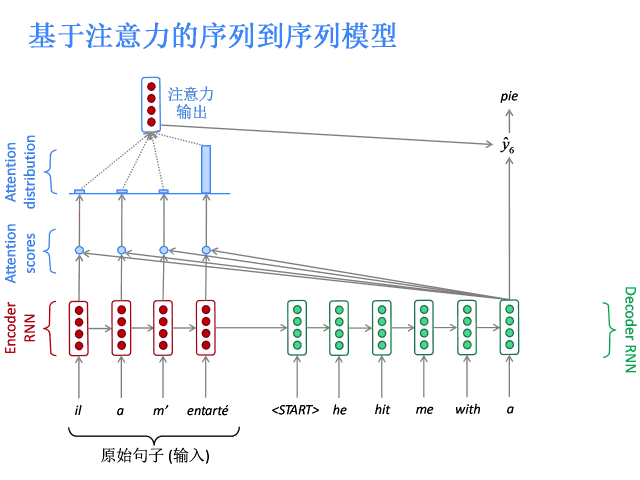
注意力的核心思想是在解码器的每一步,都与编码器直接相连,以便对原始句子的特定部分进行关注。先上图。
基于注意力的序列到序列模型
编码器隐层状态为:
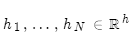
到第t时间步,解码器的隐层状态为:
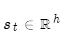
此步的注意力分值为:
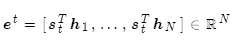
使用softmax获得该步的注意力分布:
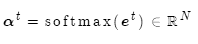
然后使用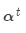 对编码器的隐层状态加权求和,获得注意力输出
对编码器的隐层状态加权求和,获得注意力输出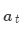 :
:
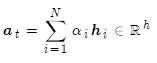
最后,将注意力输出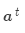 和编码器隐层状态
和编码器隐层状态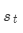 拼接:
拼接:
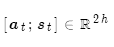
后续过程就与普通Seq2Seq一样了。
注意力很厉害
注意力允许解码器关注原始句子的特定部分,显著提高了NMT效果
注意力允许解码器直接查看原始句子,解决了信息瓶颈的问题
注意力提供了遥远状态的捷径,有助于缓解梯度消失的问题
注意力提供了某种可解释性:
查看注意力分布,可以了解解码器所关注的内容
免费自动实现了软对齐,无需单独训练一套对齐系统
注意力应用广泛
已经看到,注意力可以大大改善机器翻译的效果。
然而不仅于此,注意力同样适用于很多其他神经网络结构和很多其他任务。
注意力的广义定义:
给定一组向量值(value)和一个向量查询(query),注意力就是根据向量查询来计算向量值加权求和。
例如在seq2seq+attention模型中,每个解码器隐层状态就是查询,它会去关注编码器的所有隐层状态(值)。
加权求和就是对数值中的信息进行选择性摘取,查询决定了需要关注哪些数值。
注意力可根据某些表示(查询)将任意一组表示(值)转换为固定大小的表示。
注意力变体
假设有若干值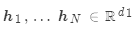 和一个查询
和一个查询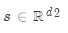 。
。
注意力通常包括:
计算注意力分值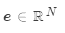
用softmax获得注意力分布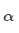 :
:
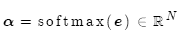
使用注意力分布计算值的加权求和,这就是注意力输出(亦称为语境向量):
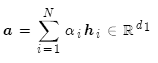
这里注意力分值计算有若干种方法:
基本点乘: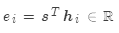
矩阵乘法: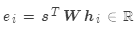 ,其中
,其中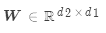 是权重矩阵
是权重矩阵
加法: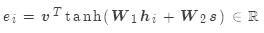
其中:
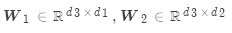 是权重矩阵
是权重矩阵
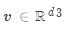 是权重向量
是权重向量
 是注意力的维度,是超参数
是注意力的维度,是超参数
总结一下:我们学习了机器翻译的历史、神经机器翻译的序列到序列模型和注意力机制。
-
机器翻译
+关注
关注
0文章
139浏览量
14860 -
深度学习
+关注
关注
73文章
5457浏览量
120863 -
自然语言处理
+关注
关注
1文章
593浏览量
13475
原文标题:机器翻译、Seq2Seq、注意力(CS224N-2019-8)
文章出处:【微信号:gh_b11486d178ef,微信公众号:语言和智能】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【推荐体验】腾讯云自然语言处理
什么是人工智能、机器学习、深度学习和自然语言处理?
从语言学到深度学习NLP,一文概述自然语言处理
深度学习与自然语言处理的工作概述及未来发展
自然语言处理的优点有哪些_自然语言处理的5大优势
斯坦福AI Lab主任、NLP大师Manning:将深度学习应用于自然语言处理领域的领军者
自然语言处理(NLP)的学习方向
基于深度学习的自然语言处理对抗样本模型





 工商网监
工商网监
评论