 电子发烧友App
电子发烧友App


高速数字记录系统中光纤下载卡的逻辑设计
数据记录及下载系统
如图1所示,雷达信号预处理机将采样到的信号进行一系列处理工作,最后形成一路或多路的光纤数据,送交外面的两个分支。一个分支是送交雷达信号处理机,进行真正的雷达信号实时分析处理。这个分支我们不关心。另一个分支是通过RocketIO传送至一块或多块数据记录板。

图1 数据记录及下载系统框图
数据记录在现场进行,存储到记录设备后,有两个用途,一是回放,即回放到雷达信号处理机中,复现进入时的情景;另一种是下载,即下载到本地微机上,对数据进行检查和处理。下载过程一般在实验室进行,下载方式有两种,一种是网络下载,另一种是光纤下载。
网络下载的缺点是速度慢,受网络带宽和芯片处理能力的限制,其传输速率一般为30~60Mb/s。优点是不需要额外的设备,只要设备支持网络通信即可。本地微机作为主控机,控制下载并存放下载的数据。
光纤下载是将记录设备的光口和专用的光纤下载卡互连,数据传输至光纤下载卡后,然后通过PCI总线转存至主机硬盘上。光纤下载的优点是下载速度快,采用Xilinx FPGA提供的高速串行链路IP核RocketIO,其下载速度可以达到2.5Gb/s,去掉开销也能达到2Gb/s,即250Mb/s,比网络下载提高了近一个数量级。缺点是普通微机没有光口,需要额外的光纤下载设备,插入本地微机,和记录设备对接,完成光纤下载。如图1中的粗黑的光纤和64位/66M的PCI总线就是供光纤下载之用。
光纤下载卡结构
图2为光纤下载卡结构图。如图2所示,光纤下载设备的和核心为一块Xilinx的V2 pro系列FPGA,其外围有两组DDR,用于数据的缓存。为了和外部交换板的光口互连,还有一个光模块。下载设备的另一端通过PCI总线和主机相连,主机可以是X86处理器或PPC处理器。
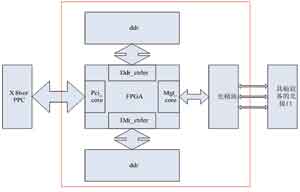
图2 光纤下载卡结构
可见下载设备的硬件结构比较简洁,其复杂之处在于FPGA内部的逻辑的控制。在FPGA设计中,除需要例化MGT核,PCI核外还要设计控制逻辑进行数据传输的控制。
数据传输一般来说有三种方式,包括程序直接控制方式、中断控制方式和DMA方式。
程序直接控制方式就是由用户进程来直接控制内存或CPU和外围设备之间的数据传送。它的优点是控制简单,缺点是CPU和外围设备只能串行工作,CPU的大部分工作时间浪费在对外部数据的读取过程中,其利用率很低。
中断控制方式是外围设备收到数据后,向CPU发送中断。CPU收到中断后,再控制数据在其内存和外围设备之间的传输。它的优点是大大提高了CPU的利用率且能支持多道程序和设备的并行操作。它的缺点是由于数据缓冲寄存器比较小,如果中断次数较多,仍然会占用大量CPU时间。在外围设备较多时,由于中断次数的急剧增加,可能造成CPU无法响应中断而出现中断丢失的现象。如果外围设备速度比较快,可能会出现CPU来不及从数据缓冲寄存器中取走数据而丢失数据的情况。
DMA方式是在外围设备和内存之间开辟直接的数据交换通路进行数据传送。外围设备通过通用总线直接访问内存,将其收到的数据写入内存或将要发送的数据读出内存。上述操作完成后,再通过中断的方式通知CPU,由CPU进行后继的处理。它的优点是除了在数据块传送开始时需要CPU的启动指令,在整个数据块传送结束时需要发中断通知CPU进行中断处理之外,不需要CPU的干涉。
可见,下载设备和微机之间通过主DMA方式进行通信,可以大大的提高数据传输速率。66MHz/64位宽的PCI总线在理想情况下可以提供近500Mb/s的传输速率,可以比较容易的达到250Mb/s的光纤下载速度,所以下载的瓶颈在于硬盘的读写速度。普通硬盘的平均读写速度在60Mb/s,采用4个盘一组的阵列盘,差不多可以达到60×4=240Mb/s的速度。
由上述数据可以看出,采用64位的PCI总线,用主DMA方式进行数据传输,下载的最大速度将大于200Mb/s。
FPGA逻辑内部结构
逻辑总体结构图如图3所示,数据流方向为:串行的光纤数据首先进入ATM(Aurora Transmit Module)模块,由ATM模块内部的Xilinx RocketIo核将串行数据转换成并行32位数据。并行数据经过FIFO进行缓存后,进入PING64模块。Pin64模块内部逻辑产生主DMA时序,并将FIFO数据送上内部总线。Pcim_lc将内部总线信号转换成PCI总线信号并送出去。各个模块的功能具体如下。
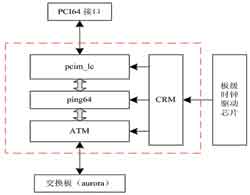
图3 FPGA内部结构图
● Pcim_lc模块为Xilinx提供的PCI64位的软核;
● Ping64模块包括和PCI64软核的接口以及主DMA处理逻辑;
● ATM为和光纤输入的接口模块,采用Xilinx提高的Aurora协议对数据进行控制,ATM只需提高用户逻辑和Aurora的接口即可;
● CRM为时钟和复位信号产生模块。
ATM模块和ping64模块之间接口为标准FIFO接口,设置此FIFO的目的有两个:一是时钟域转换,外部输入的主时钟为125MHz,而RocketIO采用32位模式,在2.5Gb/s的速率下,逻辑的主工作时钟为62.5MHz。而ping64模块采用PCI总线提供的PCI66MHz时钟。两者时钟不在同一个时钟域,所以用异步FIFO将时钟域隔离。二是数据的缓存。根据FIFO的almost full信号产生反压信号,送交RocketIO,使对端收到反压信号后,停止发送数据。
所用Xilinx的RocketIO核其实为aurora 核,这是一个双向串行数据通信链路控制器,能将反压信号随数据一起发往对端。其接口相对简单,有两种模式,一种是帧模式,另一种是流模式,可以根据应用灵活选择。在本项目中采用的是帧模式。
主DMA处理的软硬件流程
在DMA处理中,采用内存乒乓操作来提高系统的吞吐量。软件中的驱动采用Windriver开发,其工作主要分三部分。
1 初始化,包括申请内存,配置DMA列表,配置DMA相关寄存器,启动逻辑开始工作。
2 中断处理函数。在此函数中,屏蔽中断,并启动DPC处理。
3 DPC(延迟过程调用),根据逻辑提供的状态标识,将相应的内存块的数据搬移至硬盘中,然后取消中断屏蔽,复位状态标识,使系统可以接收下一个中断。
数据的搬移不在中断处理函数中完成,是由于中断处理函数具有较高的优先级,如果将耗时的数据搬移放在这里进行,会明显降低系统的响应时间。而DPC的优先级在所有的外部中断之下,不会因此而降低对其他外部中断的响应速度。
主DMA逻辑的主要工作是读取驱动配置的DMA列表,根据列表中的内存地址和长度,对内存进行主DMA写操作。操作完成后,通过置位状态标识,通知驱动来读取数据。状态机转移如图4所示。

图4 DMA主状态机转移图
● IDLE状态:在此状态下,等待软件的使能信号。使能信号有效则进入JUDGE状态,否则等待。
● JUDGE状态:在此状态下,判断乒乓标志。根据乒乓标志决定本次处理应该选择哪一个内存块。
● RD_TBL状态: 发出读DMA列表的地址信息。然后进行GET_TBL状态接收列表数据。
● GET_TBL状态:在此状态下,读取DMA列表数据,并将列表中的内存地址和长度信息写入相应的寄存器中。然后进入REQ状态。
● REQ状态:在此状态下,对异步FIFO的空信号进行判断。如果非空,则进入PROCESS状态,否则在REQ状态等待。
● PROCESS状态:在此状态下,进行数据传输。由于PCI主DMA对burst长度有限制,当传输完预定长度的数据后,首先对本次长度进行判断。如果未完则进入REQ状态等待,否则判断本列表是否最后一个列表。如果是,则进行IDLE状态。否则进入RD_TBL状态读取下一条DMA列表表项的数据,继续处理。





















 工商网监
工商网监
评论