 电子发烧友App
电子发烧友App


AI芯片之于人工智能的意义,则可以理解为发动机之于汽车。人工智能这一理论已经提出了多年,但是由于实现它需要的计算量实在太大,这辆“跑车”一直没有配备上合适的“发动机”,只能放在仓库积灰。直到AI算法和大数据时代的到来、以及AI芯片的出现。
第三波AI浪潮的发展主要由深度学习技术的突破引领,而英伟达(Nvidia)凭借其通用的GPU单元,专门的TensorRT加速器,强劲的矩阵运算性能加上对其他算法的兼顾,英伟达不仅能用GPU满足AI构建的训练需求,还能用TeslaRT用来部署,很好实现AI构建,所以英伟达也率先成了这一波AI热潮的最大受益者。
给机器人“造脑”,英伟达发布全新AI芯片Jetson Xavier
近日,英伟达正式发布了一款全新AI芯片—Jetson Xavier,Jetson Xavier作NVIDIA Isaac平台的核心,是全球首款专为机器人设计的计算机。该公司CEO黄仁勋在周一的新闻发布会上表示:“这台小电脑,将成为未来机器人的大脑”。
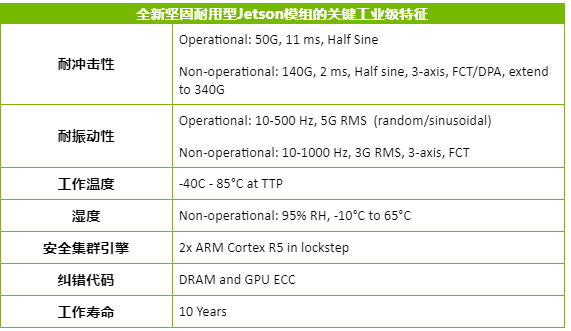
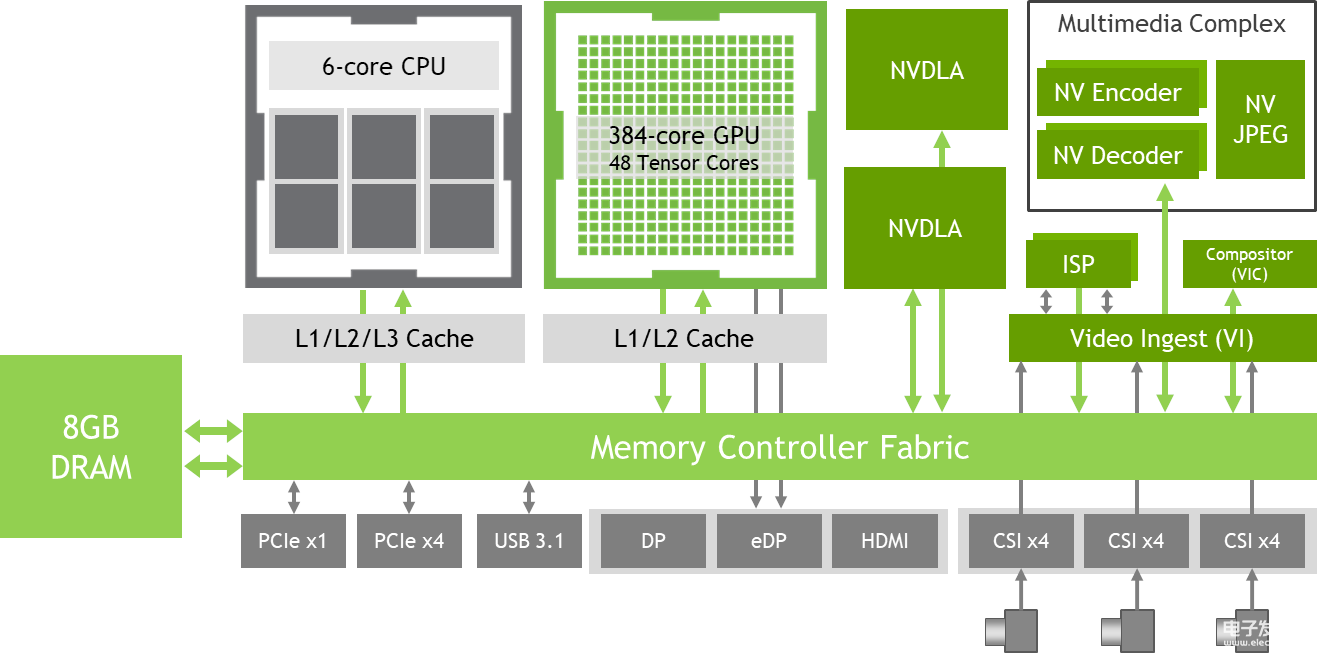
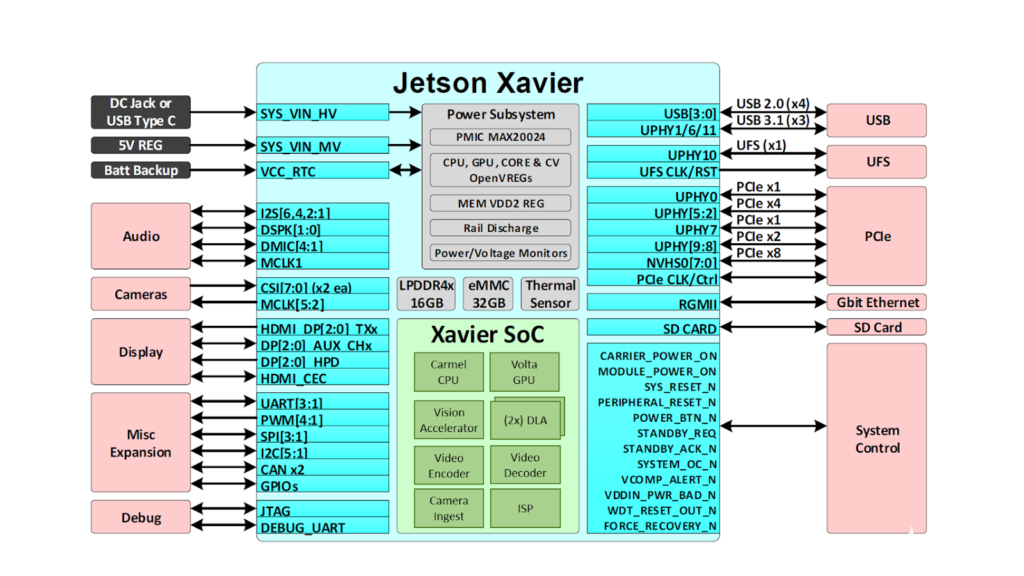
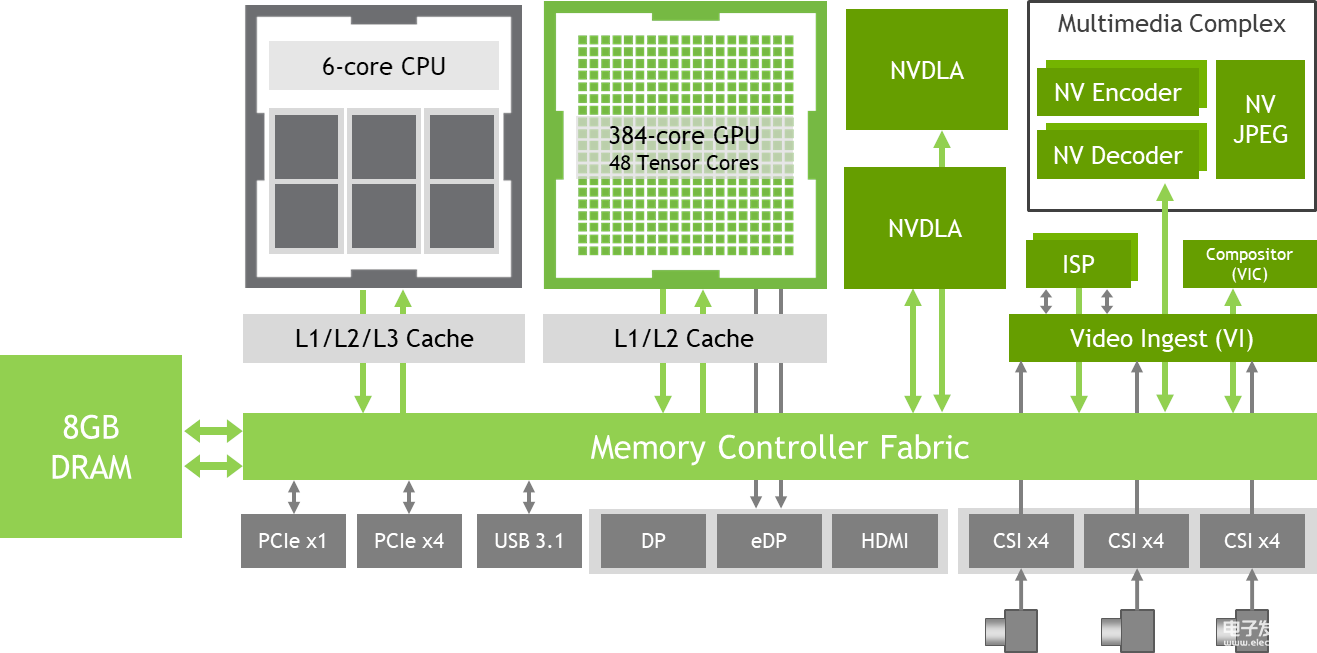
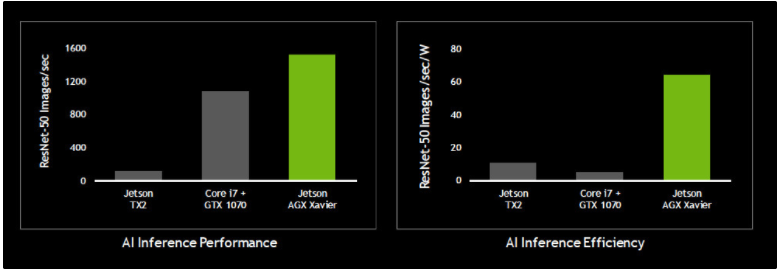
Jetson Xavier包含了六颗处理器,包括1个Volta Tensor Core GPU、1个8核ARM64 CPU、2个NVDLA深度学习加速器、1个图像处理器、1个视觉处理器和1个视频处理器,每秒可执行30万亿次操作。为了打造它,Nvidia足足耗费了五年的时间——三年设计、两年筑造,共有超过8000人参与了设计与开发,可以说这是Nvidia单独做过的最长的一个处理器项目。它的处理能力与配备了10万美元GPU的工作站大致相同,但功率仅为30瓦。
简而言之,就是Nvidia成功地将1000瓦性能的10万美元级工作站,缩小到了30瓦的‘掌中宝’的程度。
NVIDIA为Jetson Xavier的模拟、训练、验证和部署提供了一个工具箱。该机器人软件包含Isaac SDK、Isaac IMX、Isaac Sim三方面内容:
l Isaac SDK:一套API和工具,可借助全面加速的库,开发机器人算法软件及运行时框架。
l Isaac IMX:Isaac智能机器加速应用,是NVIDIA开发的机器人算法软件的集合。
l 当前Nvidia的技术,已经被一些企业用于自主仓库机器人、机器采摘和农业机器人。不过黄仁勋表示,JetsonXavier要比之前的AI芯片要强大20倍。
l Isaac Sim:高度逼真的虚拟仿真环境,可供开发者训练自主机器,并使用Jetson Xavier进行硬件在环测试。
提早转型,英伟达开启人工智能之路
作为一家图像处理芯片公司,Nvidia约在7年前就已经开始转型布局人工智能。当时人工智能概念还未兴起,AI仍是一片蓝海。经过持续多年的研发,公司在近年来陆续推出人工智能芯片、系统、软件和服务,打造世界顶级人工智能公司。
2009年 英伟达Tegra进入奥迪汽车
德国大众为旗下的奥迪汽车引入新式导航系统,并首次采用NVIDIATegra片上系统处理器。相比于2009年初的多媒体交互系统(MMI),新的Tegra核心导航系统自然要更加高级,不但功能上更强大,效果也应该更酷一些。
在后来的GTC 2014大会上,奥迪自动驾驶汽车再次展示了基于Tegra K1开发套件的车载智能系统,可提供自动驾驶、导航、碰撞感应、智能链接等功能。
2013年11月 IBM和英伟达联合开发超级计算机
IBM与芯片厂商英伟达Nvidia达成战略合作,共同设计开发新型超级计算机系统和服务器。英伟达开发的图形处理单元芯片(GPU),很好适用于浮点计算,表现胜于英特尔的传统CPU Xeon和AMD的Opteron。排名第二位的“泰坦”也搭载了GPU。
根据IBM和英伟达合作内容,双方在芯片方面就行合作,通过技术共享,让英伟达的Tesla GPU更好与前者的Power 8芯片协同工作。
早期的Tesla车型曾使用过Tegra 2,但处理能力远远不够,所以后来升级到了Tegra 3。特斯拉Model S电动车的车载娱乐系统也是基于Tegra 3设计。Nvidia基于在图形处理方面长期积累与CUDA架构,和特斯拉建立密切的合作。而特斯拉为Nvidia在高度智能化的汽车上的布局上起到助推作用。
2014年早期特斯拉ModelS搭载英伟达Tegra 3
Nvidia不仅在硬件上有布局,同时已经渗透到了软件层面。Nvidia将一辆Jeep进行深度改装,但改的不是发动机、轮毂或包围,而是中控系统。改装后的Jeep采用3D打印制造出的中控台,搭配一个17英寸的电容屏。屏幕划分为3个区域,上中下分贝显示地图、娱乐信息以及HVAC(比如空调控制)。配合Tegra K1,Nvidia直接切入到了车辆的CAN总线中,实现了对整个车辆的控制。
2014年初,世界上采用NVIDIA处理器的汽车已经超过450万辆,涉及20多个品牌、100多款车型,其中包括奥迪、宝马、大众等车企巨头,也包括特斯拉这种车界新贵。2015年,Tegra芯片在汽车领域发展加快,在道路上跑的汽车有超过800万辆搭载Tegra芯片。2015年第三季度Nvidia在汽车领域的业务销量增长了51%。
2015年12月 Facebook开源BigSur
Facebook研发代号为“BigSur”的新一代硬件的设计目标是训练神经网络。除人工智能外,这一技术还经常被称作机器或深度学习。Facebook与Nvidia进行合作,是第一家采用英伟达TeslaM40GPU加速器的厂商。M40GPU面向深度神经网络,是BigSur平台和OpenRack兼容硬件的关键。
采用M40的BigSur平台的速度是该Facebook上一代产品的2倍,使得训练规模相当于原来2倍的神经网络的速度提高1倍。BigSur是第一款针对机器学习、人工智能研究开发的开放源代码计算系统,Facebook将把设计材料提交给开放计算项目。
2016年 新款特斯拉model S采用Tegrak1
2016年新款状态显示器分辨率升级,从过去的1280x480 升级到1920x720,因此副处理器也从Tegra 2升级为Tegra 3,主处理器从Tegra 3升级到了Tegra k1 从而更好地支持自动辅助驾驶功能。
Tesla P40、Tesla P4高性能计算卡
2016年9月,NVIDIA发布新一代高性能计算卡Tesla P40、Tesla P4,它们俩将取代上代麦克斯韦架构的Tesla M40/M4,进化到最新的帕斯卡架构,拥有16nm工艺。这两款计算卡主要负责图像、文字和语音识别,专为人工智能、深度学习、神经网络推演而生。
Tesla P4及P40特别针对推论设计,使用经训练的深度神经网络识别语音、影像及文字以回应使用者和装置要求。Pascal架构GPU具备以8位(INT8)运算为主的专门推论指令,提供比CPU快45倍的反应速度,与不到一年前推出的GPU解决方案相比则提升了4倍。
深度学习超级计算机NVIDIADGX-1
深度学习最苛刻的部分是训练。NVIDIA专为深度学习设计的PASCAL架构,助推深度学习加速高达65倍,并且能够支持每个主要的深度学习框架。在此架构基础上,NVIDIA创造了专为GPU深度学习所设计的超级计算机DGX1。
NVIDIA的DGX-1基于Tesla P100加速卡(研发费用高达20亿美元)是世界上首款专为深度学习而打造的系统,具备全面集成的硬件和软件,可以轻松快速地完成部署。NVIDIADGX-1革命性的性能可大幅加快训练速度,成为世界上首款体积小性能强(单机箱)的深度学习超级计算机。
协同驾驶AI Co-Pilot
XAVIER已经被英伟达安装在一辆基于林肯MKC所打造的自动驾驶测试车BB8上,另外,英伟达还将在自动驾驶领域同奥迪展开合作,其全自动驾驶汽车预计将在2020年上路。
AI Co-Pilot(人工智能协同驾驶)系统该系统具有人脸识别、头部追踪、视线追踪等功能,能在行车中辅助驾驶者,提高驾驶安全性与便利性。AI Co-Pilot还能在复杂的噪声环境中通过读唇获知驾驶者的需求,准确率已达93.4%。
英伟达的优势真的是无人能挡吗?
英伟达上周发布的第一季财报再次超出业界预期,财报显示这一季度总收入增长了66%,其中数据中心业务营收增长71%达到7.01亿美元。英伟达的数据中心业务包含HPC(高性能计算)、数据中心GPU以及AI加速器即使相比过去几年2-3倍的增长率要少很多,但极具潜力的AI芯片市场空间依旧吸引了众多巨头和创业者的参与。
不过英伟达现在具有优势并不意味着AI市场的蛋糕会被英伟达独吞,无论是科技巨头英特尔、谷歌、IBM、AMD还是OURS、地平线、寒武纪等初创企业都纷纷加入了AI芯片领域的竞争。
英特尔这几年也是卯足了劲入军AI市场,英特尔的All in AI实力也是不容小觑。除了巩固资深的优势产品以外,还进行了一系列的收购以增强自己的能力。英特尔针对已有的优势产品XeonPhi加速计算卡、收购的Altera FPGA、 Nervana System几大产品线进行深度学习的优化,从AI构建的训练和部署都能够看出这均与英伟达形成竞争,在自动驾驶应用场景中也通过收购Mobileye与英伟达形成强竞争关系。同时还基于FPGA打造自己在AI领域的特色,对人工智能初创芯片企业的持续投资也有助于英特尔在AI芯片领域实现后来居上。
除了英特尔All In AI全面叫板英伟达,众多初创公司也会成为挑战英伟达不可忽视的对手。
以2017年由两位华人在美国硅谷创立的OURS为代表,OURS以低功耗端计算AI芯片为核心技术,目标是解决工业/商业、机器人、汽车自动驾驶、安防等领域的3D机器视觉和多传感器融合的问题。OURS的核心技术之一就是硅光技术,这一技术很适合于计算机内部和多核之间的大规模通信,其最大的优势在于拥有相当高的传输速率,可使处理器内核之间的数据传输速度比目前快 100 倍甚至更高。OURS 采用的是以数据为中心的RISC-V 计算机指令集架构,这也是OURS的另一大核心优势。
寒武纪近日也发布了一款云端智能芯片Cambricon MLU100,词云端芯片也延续了寒武纪产品通用性的特点,支持各类深度学习和经典机器学习算法,满足视觉、语音、自然语言处理、经典数据挖掘等领域复杂场景下(如大数据量、多任务、多模态、低延时、高通量)的云端智能处理需求。
不只是硬件,寒武纪还努力实现软硬件的协同工作,寒武纪从 2016 年起逐步推出了寒武纪 NeuWare 软件工具链,该平台终端和云端产品均支持,可以实现对 tensorflow、caffe 和 mxnet 的 API 兼容,同时提供寒武纪专门的高性库,可以方便地进行智能应用的开发,迁移和调优。
小结:
AI芯片全球起步时间几乎同步,此时,人工智能领域尚未出现“独步天下”的国际巨头。但是也要警惕“全民造芯”虚火,目前还没有出现像CPU(中央处理器)一样的AI通用算法芯片,AI的杀手级应用还没出现,未来这个产业还有很长一段路要走。




















 工商网监
工商网监
评论