X86主板原理图设计经验分享,根据笔者设计的一些经验,把整个系统原理图的详细设计分成了一下几大模块
2011-11-28 10:47:18 7409
7409 过去业界对X86 CPU的既有印象,就是其架构效能强大,但功耗与发热问题难以解决,但事实上,就英特尔(Intel)先后推出的Medifield与Cloverfield两个架构而言,功耗似乎已不再是问题
2013-03-06 09:09:592468 ARM和X86现在发展如何?关于X86架构和ARM架构这两者谁将统一市场的争执一直都有,但是也有人说这两者根本不具备可比性,X86无法做到ARM的功耗,而ARM也无法做到X86的性能。
2016-05-30 15:20:3819106 X86架构是微处理器执行的计算机语言指令集,指一个intel通用计算机系列的标准编号缩写,也标识一套通用的计算机指令集合。x86是一个intel通用计算机系列的标准编号缩写,也标识一套通用的计算机指令集合,X与处理器没有任何关系
2017-12-15 07:55:0016918 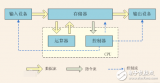
关于X86架构和ARM架构这两者谁将统一市场的争执一直都有,但是也有人说这两者根本不具备可比性,X86无法做到 ARM的功耗,而ARM也无法做到X86的性能。
2016-08-04 10:20:144377 许多专家都在灌水,说PC已死,arm已经做了头把交椅?目前来说我还不怎么赞同,我只能说在手持中,arm占了上风,而在其他行业,仍是X86的天下。
2012-09-11 13:46:21
`资深x86研发团队,10+年研发经验,研发成员来自于一线的PC、服务器、工控厂商,为客户提供专属的X86主板定制服务。平台:Xeon/Core/Pentium/Celeron/ATOMXeon
2019-03-02 11:28:32
论坛有很多嵌入式的技术资料,却几乎没有X86硬件(PC,Server 等等)设计技术资料。本人从事X86硬件及系统设计多年,总结了系列X86平台设计知识,逐步分享出来,期望能够对从事相关设计的朋友
2015-10-17 12:18:45
x86与ARM分别指的是什么呢?指令集与微架构是同一种概念吗?
2021-10-28 06:38:37
ARM指令集架构有什么特点?x86指令体系有什么缺点?
2021-09-23 07:23:58
X86架构是X86指令集,它属于CISC指令集。ARM架构是ARM指令集,属于RISC指令集。X86是冯若依曼结构,ARM是哈弗结构,这个不一定,比如ARM7TDMI用的就是冯若依曼结构。其实都是差不多,X86指令多,应用范围广,但效率就显得低一点,ARM指令少,应用范围小,效率显得高。
2016-09-27 14:40:31
x86系:x86架构的最大特色在于可以兼容Windows操作系统,现已成为了业界的一种标准。芯片巨头美国英特尔(Intel)一家独大。——(北大众志、兆芯、海光)兆芯:上海兆芯集成电路有限公司(以下
2021-07-27 08:14:58
为了减轻多核心处理器的编程工作,AMD已经出版了扩展其x86指令集的若干计划中的第一份计划。通过这个行动,AMD再次把它的规则用在了跟英特尔公司的竞争上,从而在技术上推进其CPU架构领先于它的最大竞争对手。
2019-07-26 07:34:13
可以根据用户的需要来进行灵活配置,比如logo,内存大小,系统驱动程序裁减,周围芯片的裁减,系统软件的加载等等,无论软硬件都是非常灵活这样也会大大降低客户的成本和系统整体的维护成本和性能,而X86却无法
2012-06-15 15:56:45
ARM的架构相较于x86有哪些特点?ARM架构的系统与X86架构系统的特性有什么不同?
2021-06-16 09:05:32
到AE。但是,是有问题的,这个时候应该x86也开始扫描LPC了,导致过不去,USB就不可以使用2:我就讲CPLD的连接LPC的这几个引脚,不管设置为输入,还是输出,,还是输入三态到一个未使用的引脚
2017-05-31 10:11:02
本帖最后由 silverze 于 2017-3-20 16:05 编辑
本文将详细记录使用C语言创建一个dll库文件,然后在Labview中进行调用的过程。一、目标用C语言创建两个函数,分别
2017-03-20 16:05:28
目录1、ARM1.1 ARM历史1.2 ARM内核系列2、MIPS应用范围发展历史3、PowerPC三巨头4、X86架构X86历史5、PowerPC架构相比于ARM的优势6、Powerpc架构
2021-07-26 06:16:55
VxWorks for x86系统中的系统时间VxWorks for x86中系统时间和实时时钟的同步 实时时钟的特定时间怎么设置
2021-04-27 06:19:50
[X86架构和ARM架构,在工业领域的优势争霸]X86与ARM谁更胜一筹? X86作为经典的CISC指令集,其架构的优点在于功能强大,而且通用性、兼容性、与实用性要强。而哈弗结构的ARM架构的优点
2014-08-01 10:45:41
什么叫arm架构?x86架构是由哪些部分组成的?arm架构和x86架构有什么区别?
2021-10-25 08:25:29
,而不是x86处理器几十年来提供的不断增长的时钟和总线速度。这引起了近年来基于Arm的IPC解决方案对原始设备制造商及其客户的兴趣日益增加。尽管与x86相比,Arm处理器以其相对较低的功耗而闻名,但
2019-04-23 15:06:08
为什么x86和arm的架构不同,但是都能装linux呢?他们的编译时如何实现的?
2023-05-16 10:21:22
为什么aarch64和x86不像以前那样支持条件执行了呢?有哪位大神可以解释一下吗
2022-08-01 14:12:39
C:\Program Files (x86)\National Instruments\LabVIEW 8.6\resource缺少这个dll的放在这个文件夹里面
2014-07-15 09:43:59
如果arm CHIP內建 x86 decoder 會能跑 x86?現在一堆X86 cpu 有些都變 micro code ..用 risc 方式 那如果 ARM內建 x86 decoder ..開機選 arm => 省電x86傳統軟體相容
2022-06-14 11:38:05
如题。求助,x86框架下进行VxWorks5.5开发,支持的低功耗CPU有哪些?
2016-08-29 16:28:03
指令集可分为复杂指令集(CISC)和精简指令集(RISC)两部分,代表架构分别是x86、ARM和MIPS。 ARMRISC是为了提高处理器运行速度而设计的芯片体系,它的关键技术在于流水线操作即在一
2017-05-25 16:09:57
各位大侠本人是做触摸显示器的,需要采购大约2k能支持POE供电的x86主板,用于10.1“一体机,有这样资源的欢迎联系我。QQ:469244246
2017-10-26 15:55:36
自己得不到x86架构技术,NVIDIA对其恨之入骨也是情理之中。黄仁勋近日就表示,随着智能手机和平板机冲击传统x86 PC产业
2010-09-29 11:56:07659 X86架构的CPU有分为消费类和嵌入式类的,而CPU的三大厂家INTEL,AMD。
2011-05-11 08:01:002879 ARM架构是一个32位元精简指令集中央处理器架构,x86架构指的是特定微处理器执行的一些计算机语言指令集。X86架构比ARM架构系统在性能方面要快得多、强得多。
2011-11-30 12:48:06

ARM架构SOC片上系统的发展模式取得的突破性成功,已经影响到了X86架构芯片。处理器开始向融合、整合趋势发展。今年X86芯片内整合GPU仅仅是开始。X86阵营下的老大芯片巨头Intel和AMD相继
2011-12-05 09:21:221062 NVIDIA HPC产品部门主管Sumit Gupta在接受媒体采访时表示,HPC的未来方向在于ARM而非x86。
2011-12-14 09:41:09950 微软已明确表示,ARM版和x86版Windows 8体验不同。Windows 8 ARM设备将采用德州仪器、高通和Nvidia的处理器,主流Windows操作系统将首次支持ARM架构芯片。
2012-02-10 11:09:142092 投资银行Pacific Crest今天发表投资报告,讨论了英特尔的X86芯片和ARM架构芯片之间的竞争。Pacific Crest在报告中指出,三星最有可能在笔记本中放弃X86芯片,转用ARM芯片。2011年三星笔记本
2012-04-18 09:35:541535 
ARM与英特尔x86架构之间的战争不断升温,英特尔x86地位难以撼动,但ARM架构有着明显的功耗优势,什么样的CPU最适合未来的需求?
2013-03-14 11:31:372477 
采用 ARM 架构的产品无论在功耗表现、产品多元性方面,都优于对手的 X86 架构。另外,由于超过 60% 的 App 是基于 ARM 架构撰写并优化,因此软体相容性也会优于 X86 产品。整体来说,安谋认为只有 ARM 推出的产品能够满足消费者选择、厂商创新、以及与其他品牌差异化等需求。
2013-06-08 09:08:54978 AMD演示其运行Fedora Linux系统的新一代x86 APU产品,展示服务器创新与业界首创成果,基于开放标准的AMD皓龙处理器生态系统的发展使从x86 CPU到x86 APU的无缝体验成为现实。
2014-04-22 10:30:141104 Windows_Installer(x86/x64)下载
2016-01-15 17:17:42 1
1 用32位x86汇编设计8051模拟器,有兴趣的同学可以下载学习
2016-05-03 16:36:4720 前日,微软和高通宣布,骁龙处理器将全面支持Windows 10桌面操作系统,这意味着ARM架构的芯片可以运行UWP和x86 Win32程序。
2016-12-10 11:31:444404 X86平台嵌入式软件应用
2017-01-14 02:36:100 的应用,尤其是在国防和军事上的一些高精尖技术及实时性要求极高的领域中,就更体现出了其优越的性能。 X86或80X86是Intel公司开发的微处理器体系结构的泛称。采用X86架构的Intel CPU及其兼容CPU都使用X86指令集,作为个人计算机的标准平台,它们构成了当今数量最大的CPU阵营
2017-11-01 10:19:371 1、LabVIEW也可以创建DLL 2、调用规范说明:C调用规范时,调用方负责清空堆栈。使用标准调用规范时,被调用函数负责清空堆栈。 所以要确认您选择了和DLL相同的调用规范 3、调用库函数
2017-12-04 10:52:060 X86属于典型的CISC,指令集丰富,指令不等长,善于执行复杂工作,更强调串行性能;ARM是典型的RISC,指令集精简,但指令等长,这样提高了处理效率,但遇到复杂指令,就需要更多的简单指令来堆砌复杂任务。
2017-12-14 19:00:5910308 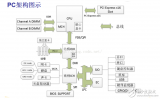
labview软定时dll文件
2018-01-22 13:46:4110 虽然随着CPU技术的不断发展,Intel陆续研制出更新型的i80386、i80486直到今天的Pentium Ⅲ(以下简为PⅢ)系列,但为了保证电脑能继续运行以往开发的各类应用程序以保护和继承丰富的软件资源,所以Intel公司所生产的所有CPU仍然继续使用X86指令集,所以它的CPU仍属于X86系列。
2018-01-31 13:59:164037 本文主要介绍的是arm架构和x86架构的区别,首先介绍了ARM架构图,其次介绍了x86架构图,最后从性能、扩展能力、操作系统的兼容性、软件开发的方便性及可使用工具的多样性及功耗这五个方面详细的对比了arm架构和x86架构的区别,具体的跟随小编一起来了解一下。
2018-05-16 14:19:55315249 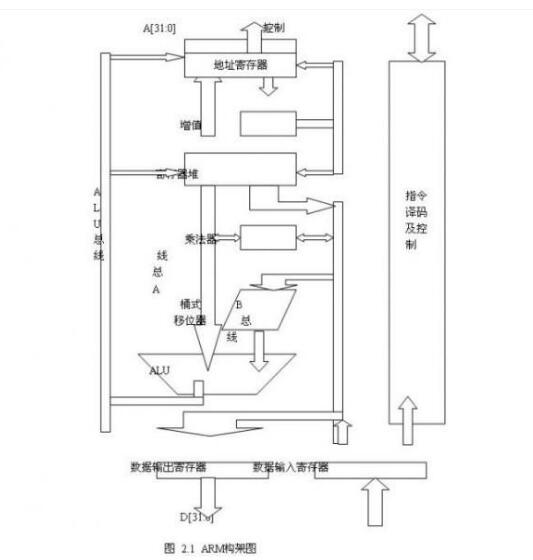
本文首先阐述了x86的概念及ARM架构,其次介绍了X86架构与ARM架构区别,最后分析了医疗设备逐渐从X86转到ARM平台主要原因。
2018-05-25 10:49:054679 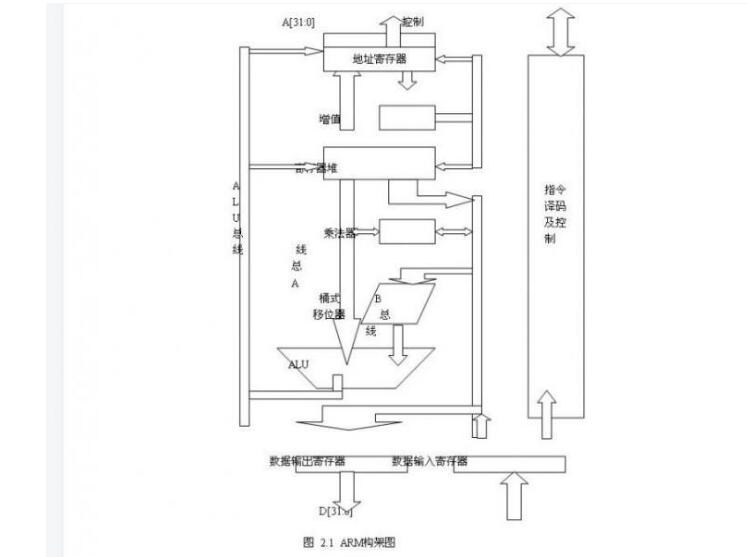
x86架构于1978年推出的Intel 8086中央处理器中首度出现,它是从Intel 8008处理器中发展而来的,而8008则是发展自Intel 4004的。8086在三年后为IBM PC所选用,之后x86便成为了个人计算机的标准平台,成为了历来最成功的CPU架构。
2018-07-02 10:35:007400 
X86主要用于PC领域如笔记本、台式机、小型服务器;ARM主要用于移动领域如手机、平板。
2018-09-01 09:19:007239 Android on x86 Go with Intel for a superior user experience
2018-10-29 06:17:002745 X86架构(The X86 architecture)是微处理器执行的计算机语言指令集,指一个intel通用计算机系列的标准编号缩写,也标识一套通用的计算机指令集合。 X86的发展史 1978年6月
2018-10-18 18:04:012349 本视频重点介绍如何使用Android虚拟设备管理器设置x86仿真器。
了解如何设置不同的参数并配置依赖关系以成功创建x86仿真器。
2018-10-30 06:08:004877 很容易将x86架构的支持添加到现有的原生Android应用程序中。添加支持还有可能提高应用程序性能。
本指南详细介绍了使用Eclipse开发环境的必要步骤
2018-11-06 06:50:003734 从10月份发布的Surface产品线来看,微软未来不仅会携手Intel、AMR两大X86巨头,与高通在ARM上的合作也不会停止,最新传闻称2021 H1版的Windows 10就会大改,支持在ARM处理器上运行64位X86软件。
2019-11-16 10:28:055596 X86架构已经问世41年了,当年它还只是众多CPU架构中的一种,但是被IBM选择为兼容PC的处理器之后,X86这么多年来已经确定了它在业界的地位。现在包括ARM在内的架构都想跟X86搏一搏,但在AMD看来,X86架构是无可取代的。
2019-12-13 10:19:022215 X86架构已经问世41年了,当年它还只是众多CPU架构中的一种,但是被IBM选择为兼容PC的处理器之后,X86这么多年来已经确定了它在业界的地位。现在包括ARM在内的架构都想跟X86搏一搏,但在AMD看来,X86架构是无可取代的。
2019-12-13 10:55:261188 要想支持 X86 要么就是找这三家合作,要么就是用其他方式变通,俄罗斯 MCST 公司研发的 Elbrus 处理器就是用的模拟 X86 处理器的方案。
2020-08-11 11:20:391530 作为英特尔路线图中相当神秘的处理器,Alder Lake承诺将异构多核的概念引入客户端PC的x86处理器。用于台式机的高端版本的Alder Lake CPU预计将具有多达16个内核。早在八月,英特尔确实表示Alder Lake属于CPU的“性能”部分。
2020-10-28 16:46:132884 众所周知,x86主板是PC和企业级处理器市场上毋庸置疑的霸主,ARM则是在移动终端市场发展起来的新兴霸主。X86主板专注高性能,为个人用户、企业用户提供出色的性能支持;而ARM则专注低功耗,为手机
2020-12-09 15:01:092830 什么是x86嵌入式工控主板?x86嵌入式主板就是嵌入式工控机内常用到的主板,它跟嵌入式工控机一样,体积比较小,主板上的CPU、内存都是直接焊在主板上,不像普通工控机主板上的CPU和内存可以随意更换
2020-12-04 13:55:552924 什么是x86嵌入式工控主板?x86嵌入式主板就是嵌入式工控机内常用到的主板,它跟嵌入式工控机一样,体积比较小,主板上的CPU、内存都是直接焊在主板上,不像普通工控机主板上的CPU和内存可以随意更换
2020-12-09 12:50:273823 开源RISC-V正朝着自己的方向越发越强大,它对其他架构的处理器也造成了不少的威胁。RISC-V不仅能实现5GHz的超高频率,而且日前其多核并行能力也已经超过了x86。
2020-12-10 09:21:342498 许多嵌入式系统设计。由于节能的特点,ARM处理器非常适用于移动通讯领域,符合其主要设计目标为低耗电的特性。 x86架构 X86架构(The X86 architecture)是微处理器执行的计算机语言
2021-01-06 10:49:458234 X86嵌入式主板是嵌入式主板的一种,主要特点源于体积小巧、参数稳定,其还能分为多个类型,它们分别对应不同的场景以及功能需求,因而在实际挑选的时候需要我们加以辨别。那么接下来不妨就随小编我一起
2021-04-11 10:15:191440 X86嵌入式主板是嵌入式主板的一类,主要特点取决于容积精巧、主要参数平稳,其还能够分成多个类别,这些各自相匹配不一样的场景以及功能需求,因而在具体挑选的时候需要大家多方面鉴别。那么下面不妨就随我们
2021-04-12 15:49:276417 X86指令集是美国Intel公司为其第一块16位CPU(i8086)专门开发的,美国IBM公司1981年推出的世界第一台PC机中的CPU— i8088(i8086简化版)使用的也是X86指令,同时
2021-04-13 15:49:092228 Tengine 人脸检测X86版本环境System: Ubuntu18.04CMAKE: 3.15.3准备把第0篇-Tengine X86版本编译中编译好的so和头文件复制到项目目录中...
2022-01-26 18:18:040 此类产品用于服务器和客户端环境,通过 PCI Express 接口将多个以太网接口连接到主机 x86 CPU。这些设备无法通过编程来执行复杂的网络任务,例如交换或在线安全。它们无法访问外部存储器,因此无法支持数百万个流。
2022-06-09 15:59:151793 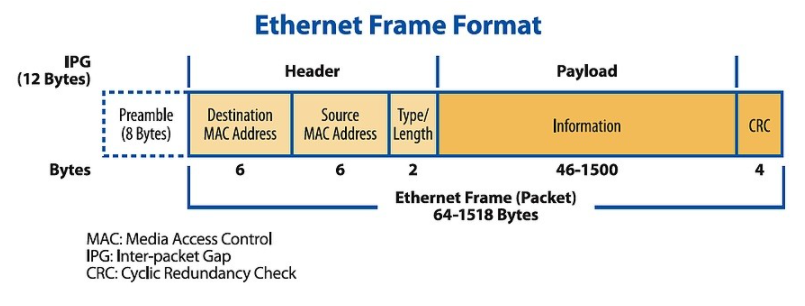
x86进入Arm专长领域,则以2014年华硕ASUS推出ZenPhone手机为指标。ZenPhone使用x86架构的Atom Z系列CPU。
2022-09-28 10:43:092453 过去20年时间,PC CPU市场一直被X86架构主导,英特尔长期占据着这个市场一半以上的份额。 不过近几年来,英特尔在PC处理器市场的王者地位日渐动摇,导致其领先优势被削弱。 当前基于X86
2022-11-15 11:06:042274 X86架构(The X86 architecture)是微处理器执行的计算机语言指令集,指一个intel通用计算机系列的标准编号缩写,也标识一套通用的计算机指令集合。x86泛指一系列基于Intel 8086且向后兼容的中央处理器指令集架构。
2023-02-22 09:37:438181 x86架构工业主板主要用于工业场合,是工业计算机的重要组成部分。由于x86架构工业母板能够适应温度范围大的环境,并且能够长期在高负载环境下工作,因此在工业控制行业得到了广泛的应用。接下来,我们将详细介绍x86架构工业主板解决方案。
2023-03-07 10:26:391983 基于英特尔 x86 和 IOP 的系统互连软件 API
2023-04-26 20:30:070 Blink 是无特权用户空间虚拟机,支持在任何 POSIX 平台上模拟 x86-64-linux 二进制文件,声称是最小的 x86 Linux 模拟器。
2023-06-08 15:55:051580 
X86架构和ARM架构是主流的两种CPU架构,X86架构的CPU是PC服务器行业的老大,ARM架构的CPU则是移动端的老大。X86架构和arm架构实际上就是CISC与RISC之间的区别,很多用户不理解它们两个之间到底有哪些区别,实际就是它们的领域不太相同,然后追求也不相同。
2023-06-16 12:50:2929034 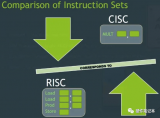
我们主要应用的三大芯片架构:X86、ARM和RISC-V架构
2023-07-25 09:35:2752481 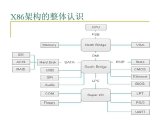
电子发烧友网站提供《MegaRAID SAS驱动器solaris x86(1.23版).zip》资料免费下载
2023-07-27 09:46:082 电子发烧友网站提供《OneConnect Flash ISO映像10.4.255.25 x86版本.iso》资料免费下载
2023-07-26 17:32:340 电子发烧友网站提供《OneCommand企业应用套件Windows x86 (GUI).exe》资料免费下载
2023-08-02 14:26:000 电子发烧友网站提供《Windows 7的x86驱动程序4.6.zip》资料免费下载
2023-08-18 10:09:390 电子发烧友网站提供《OneConnect Flash ISO映像10.2.370.19 x86版本.iso》资料免费下载
2023-08-24 15:09:480 x86和ARM架构是计算机处理器的两种不同体系结构,涉及到CPU和主板两方面的区别。下面将详细介绍它们的特点和区别。 首先,我们需要先了解x86和ARM是什么。x86架构是由英特尔公司和AMD公司
2023-12-21 17:08:424147 ARM架构和x86架构是两种不同的计算机处理器架构,它们在体系结构、指令集、应用领域等方面有着明显的区别。Linux操作系统则具有广泛的适配性,可以运行在各种架构上,包括x86和ARM架构。 一
2024-01-30 13:46:1324257 单板计算机 (SBC) 已成为技术领域的基石,为各种应用提供紧凑、经济高效的解决方案。两种最流行的 SBC 架构是 x86 和 ARM。本文旨在提供 x86 SBC 和 ARM SBC 之间的全面
2024-03-07 13:26:111479 谷歌预计将通过Google Cloud提供Axion AI芯片给客户。谷歌强调这款基于ARM的CPU产品具有优越的性能表现,甚至超越了传统的x86芯片及云端通用ARM芯片。
2024-04-10 16:32:271527 X86工控主板在交互机器人中的应用主要体现在其高可靠性、抗干扰性和稳定性等方面,为交互机器人的正常运行和精确控制提供了有力支持。以下是关于X86工控主板在交互机器人中应用的详细分析:
2024-05-28 15:48:48981 10月16日,英特尔正式公布了一项重大合作计划:与AMD携手成立x86生态系统咨询小组。该计划由英特尔CEO帕特·基辛格亲自宣布。
x86生态系统咨询小组(x86 Ecosystem
2024-10-16 13:49:581503
 电子发烧友App
电子发烧友App











 工商网监
工商网监
评论