 电子发烧友App
电子发烧友App


作者 李安
安思疆科技CEO,硕士毕业于浙江大学光电系,曾就职于华为2012实验室,独立设计了3D结构光系统,主导潜望式镜头光学设计,大规模应用在华为旗舰机,多项核心技术专利(包括美国专利)第一发明人,发表多篇论文,精通几何光学、衍射光学,激光,复杂光电系统设计,熟悉微纳光学、图像处理、3D视觉算法、光电芯片等领域,拥有完整的产品及产业经验和深厚的理论及技术背景。安思疆也是继苹果之后,第2家发布消费级面阵dToF激光雷达的公司。
2022年9月,苹果发布了全新的iPhone 14系列手机,其中Pro和Pro Max均延续了前代配置中的后置dToF激光雷达模组,用于手机AR、3D扫描建模、辅助对焦等功能,大幅提升智能手机3D视觉体验。
实际上,早在2020年3月苹果发布新款iPad Pro,其后置相机模块中就进行了大幅革新,首次搭载了自研的基于dToF技术的Lidar模块( Light detection and range,激光雷达);随后仅隔半年,在10月份发布iPhone 12系列中,也搭载了这一技术;是苹果继2017年发布3D结构光后,迎来的又一重大技术里程碑,同时也是大面阵3D Lidar首次在消费电子产品中的大规模应用。

图1. iPhone后置激光雷达
3D传感技术作为苹果公司近年来重点布局的方向,已应用在生物识别、拍照、游戏、建模、虚拟现实、增强现实等领域,进一步强化了其在3D视觉技术领域的护城河。从其技术布局的规划来看,我们完全有理由相信,在很快到来的Apple Glass中,3D传感器是不可或缺的。
3D传感技术主流包括结构光技术(Structure Light)和光飞行时间测量技术(ToF, Time of Flight), 后者又分为间接飞行时间测量(iToF, indirect Time of Flight)和直接飞行时间测量(dToF, direct Time of Flight)。苹果在技术路径上最终选择了结构光技术和dToF技术分别应用在前置相机和后置相机上,形成互补,兼顾前置和后置的各种3D视觉应用。
3D结构光经过几年的发展,大家已经比较熟悉,除了手机,iPad之外,也已应用在了许多地方,例如微信与支付宝的3D刷脸支付、3D人脸门锁、各种各样的机器人、3D 视频和体感游戏等场景中。而dToF技术对于消费电子产品的爱好者来讲虽然是比较前沿的技术,但其实也已经应用好几年了,例如:听筒附近的接近传感器,用来探测耳朵是否靠近以此控制屏幕亮灭;某些手机的后置相机模块中配备的距离传感器,用来辅助拍照对焦。虽然这些传感器使用了dToF的原理,但都是单点或者少点的探测,只能做一些简单的功能,无法实现大视场范围、高分辨的3D面阵成像,因而不能用来做视觉上复杂的多功能应用。在苹果的激光雷达发布之前,面阵的dToF技术主要应用在车载激光雷达,目前成熟的方案采用是机械式扫描和半机械式扫描来实现线阵向面阵的转化。而苹果的激光雷达则是大面阵dToF技术第一次在消费电子场景中使用,并且采用了基于可寻址VCSEL的全固态方案,真正做到了“出道即巅峰”。
秉承好技术就要用起来的理念,苹果为这套3D Lidar系统也是“操碎了心”,将众多复杂学科和前沿技术深度交叉,这也是作者从业这么长时间以来,所遇到的最精密、最复杂,也是融合性最高的光电视觉传感器,为了能让大家能由浅及深全面了解,作者将从器件到系统设计进行全方位的解析。
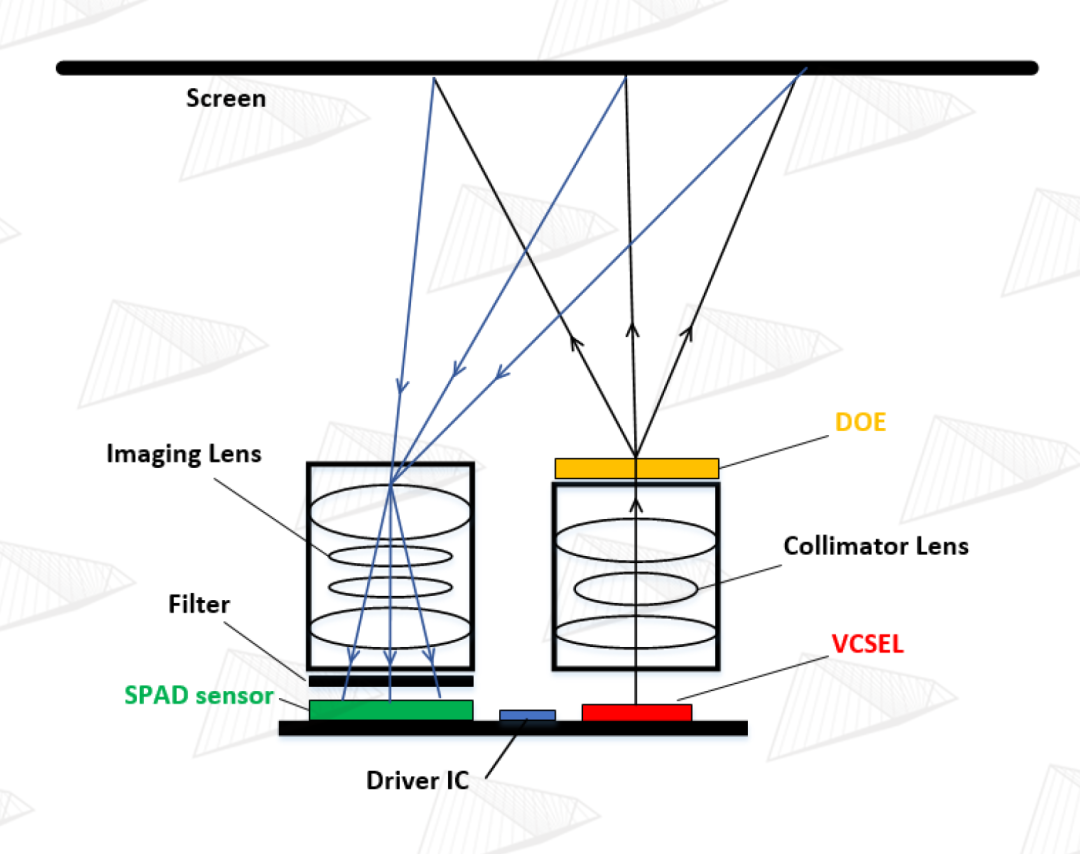
图2. 3D Lidar核心器件组成及工作原理示意图

图3. 苹果 3D Lidar 电路板实物图
如图2和图3,苹果3D Lidar的核心部件为VCSEL+ Collimator +DOE(组成发射端)、Imaging Lens +Narrow-band Filter +SPAD (组成接收端)、高速高功率激光驱动电路。我们先对各个核心器件做一个基本了解。
核心器件篇 CORE COMPONENTS
VCSEL
Collimator
DOE
Imaging Lens
Narrow-band Filter
SPAD
高速高功率激光驱动电路
VCSEL垂直腔面发射激光器 Vertical-Cavity Surface-Emitting Laser 激光是爱因斯坦在研究粒子的受激辐射时演变而来的技术,是使光波在含有增益介质的光学腔(谐振腔)里产生稳定的驻波震荡,以此实现光能量放大。第1台激光器由美国科学家在1960年利用红宝石制成,激光的中文名是由钱学森先生翻译的。我们可以按光束出射的方式,将激光分为2种类型,即EEL(Edge-Emitting Laser 边发射激光)和VCSEL(Vertical-Cavity Surface-Emitting Laser 垂直腔面发射激光),如图4。 制作激光器的材料可以是固体、气体、染料和半导体。目前用于消费电子和汽车电子等领域的主要是半导体激光器和光纤激光器(属于固体激光器),也开始在车载有应用,不过本文讨论的是半导体激光器范畴。 那么,EEL和VCSEL的区别是什么?顾名思义,EEL的光束是从器件的侧边发射出来,由于激光芯片可以在水平方向做得比较长,因此激光可以获得充分的能量增益,功率可以做得很大,目前绝大部分激光器都是EEL。VCSEL则是垂直于激光芯片表面(即厚度方向)发光。
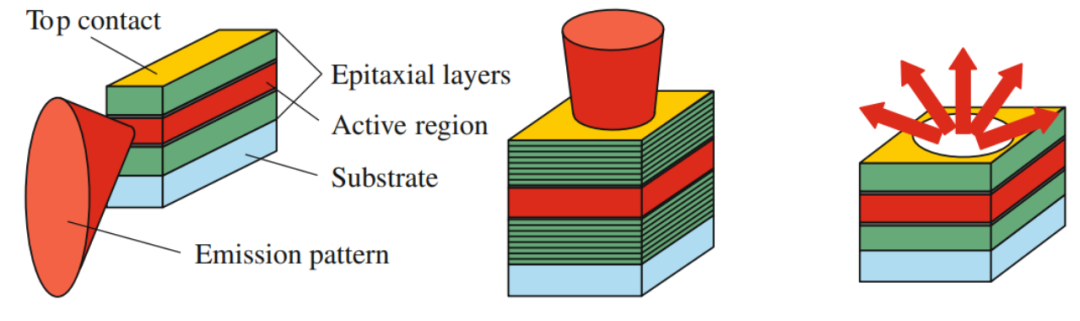
图4. 左:边发射激光,光从芯片侧边发出;中:VCSEL,光从芯片表面发出;右:LED,光从各个方向发出.
众所周知,芯片的厚度一般都非常薄,因此激光获得的能量增益有限,VCSEL中的增益腔长一般只有纳米、微米量级,跟EEL差几个数量级,因此VCSEL的功率很难做大。不过,可以实现级联放大的多结VCSEL也已经开始成熟应用,但目前还与EEL有较大差距。VCSEL是在1979年,也就是激光发明近20年后,才由日本科学家发明,其难点之一就是增益腔太短,导致损耗大于增益,很难稳定发光;经过不断的改善,直到上世纪90年代才开始在通信领域上逐渐应用。虽然存在这些缺点,但是VCSEL同样有EEL无法比拟的几大优势:
1 多点阵&紧凑封装
VCSEL可以很轻松做到将几十甚至上千个激光发射单元集成在小于数平方毫米的面积上,相邻的两个激光器单元之间的间隔甚至可短至~10um,这是EEL几乎不可能做到的,因此也非常便于封装集成,可以完全复用目前摄像头的COB(Chip on Board)工艺,对比之下EEL的封装则稍显笨拙。
2 图案化&分区照明
VCSEL还可以将众多激光点源按特殊设计排布,形成任意的图案,例如iPhone前置3D结构光中使用的伪随机散斑编码VCSEL,如果同时采用特殊的制程,可以将这些激光点阵按组别进行物理隔离,分时、分区点亮,进而可以进行更精细更复杂的设计,提升系统性能,这也是EEL无法独立实现的。
3 规模化量产&成本
由于是垂直晶圆表面发光,VCSEL在工艺制程上有巨大的优势,在晶圆制作完成之后,可以直接利用探针技术进行在线的晶圆级测试。而EEL则不行,因为边发射的激光一般需要在谐振腔的两侧,也即晶圆的水平方向进行解理镀反射膜,才能形成激光谐振腔,因此切割后还要继续进行加工和测试,这就大大降低了生产效率,增加很多成本。对于工业、车载等领域,尚可接受,但对于手机等量级的消费电子领域显然是无法接受的。
4 发散角圆对称
由于VCSEL束缚电流的孔径形状一般是圆形或接近圆形,所以其发散角在各个方向都相等,是圆对称的,因此光斑也是圆形,有利于后续光学整形系统的设计。EEL的孔径一般是横纵比较大的矩形,所以EEL的发散角是椭圆状,而且水平和垂直的发散角相差比较大,光斑是一个比较扁的椭圆形,这对后续的光束整形是比较不友好的。
综上,在消费电子领域,对激光功率、光束质量以及可靠性等要求相对较低,这就在很大程度上屏蔽了VCSEL的弱点,而其优势则完全发挥。因此,消费电子过去、现在和未来的趋势也必然是以VCSEL这种垂直表面发光形式的器件为主,这也是为什么苹果对此进行了大规模的投资。未来HCSEL水平腔表面发射激光(Horizontal V-Cavity Surface-Emitting Laser)也将逐步应用起来,这是一种结合了EEL和VCSEL优点的激光器,在此不展开详述。总之,在消费电子领域采用表面发射形式的激光拥有巨大优势。
准直镜头&接收镜头 Collimator & Imaging Lens
这两个器件是成像光学镜头,属于比较传统的几何光学领域,只不过前者用于投影,后者用于摄影。 Collimator,业界一般称为准直镜头,在苹果的结构光和dToF Lidar上都有应用,但其实除苹果之外,一般的ToF技术都不使用准直镜,原因在后面会讲到。准直镜头由多个光学镜片组合而成,用来将激光光源投射到场景中。本质上作用有二,其一是将激光的发散角整形至接近0度,其二是将仅约1mm2、由多个激光点阵形成的微小图案投射出去并放大,放大倍率通常在数百倍至数千倍。这也是为什么1mm2大小的VCSEL所投射出来的点阵却能最终覆盖前方大视场范围场景的原因之一,原因之二则是后面要讲的DOE所起的作用。 Imaging Lens,业界一般称为接收镜头,是所有2D、3D视觉中必不可少的器件,包括单反相机、手机相机、安防监控、工业检测、机器视觉等。在dToF Lidar的系统应用中,与Collimator一样,一般也是由多个光学镜片组成,其作用是成像接收TX端所投射出来的放大散斑,并在焦面上重新缩小至数平方毫米,以便微小尺寸的光电传感器接收。
评价光学成像镜头的性能指标叫像差,包含了畸变、色差、场曲、球差以及比较综合的评价参数MTF等。像差的意思是成像的差别,也即实际的成像与完美成像的差别,因此通常用于摄影的光学镜头肯定是要求各种像差,例如畸变,越小越好,越接近于0越好;但是,苹果却反其道而行之,故意把Imaging Lens的畸变设计得特别大,这非常独特,几乎没有先例,这一点我们将在后面系统篇中进行解析。
DOE 衍射光学元件 Diffraction Optical Element
DOE衍射光学元件,属于物理光学范畴,我们都知道光具有波粒二象性,光电效应证明其粒子的特性,光的衍射现象则证明了其波动的特性,其实二者本质上也是自洽的。一般来讲,在几何成像光学领域用的是光线光学的理论,即偏粒子性,而在光的衍射干涉等领域则采用波动光学理论,即偏波动性。实际上,波动光学的理论可以完全适用于几何成像光学,只是这样会让问题解析变得更繁琐复杂,所以才不这样用。那么,我们通常所说的几何光学、衍射光学以及最近比较热门的超表面光学(Meta Surface)的区别是什么呢? 让我们来做一个更本质的区分,假设光波的波长为λ(可见光波长为380nm~760nm),器件的特征尺寸(feature size 可以理解为最小结构)为d, 一般来讲可以这样分 d<0.1λ~λ,这时特征尺寸已经非常小,不仅衍射现象很明显,对光波的电磁特性也会产生不可忽略的影响,这时候光的偏振等特性必须要纳入考虑的范围,但正因为对偏振有影响,所以可在极短的光程中对光波进行非常精细的操控,超表面光学(Meta Surface)就属于这一范畴,要用严格耦合波理论才能精确描述。

图5. (a)安思疆自研的DOE设计软件GratingMaster (b)DOE的GDS加工设计文件 (c)安思疆自研的DOE实物图 (d)扫描电子显微镜下的微纳结构 (e)苹果激光雷达的DOE显微镜图像
λ
回到DOE,经过上述的了解,我们对DOE有了基本认识。DOE在苹果的3D结构光和3D Lidar中都有使用,其功能是比较容易理解的,本质上是把一束光分裂成若干份,再通俗一点讲就是把一束光复制多份,起到复制的作用。因此DOE可以把上述Collimator放大的散斑图案进行复制,相当于对散斑的投射范围进行了二次放大,苹果的3D结构光视野范围~90°,因此即使被摄人脸的位置偏离较大时也能同样解锁。苹果的3D Lidar视野范围也达到了~70°。角度越大,系统设计和DOE设计难度都急剧增大,不过目前已经有超过100°的超广角3D结构光产品,例如安思疆的Nuwa系列产品已经可以达到110°。
窄带滤光片 Narrow-band Filter
该器件属于薄膜光学领域,是比较传统的领域。3D Lidar中使用的是940nm近红外VCSEL激光器,窄带滤光片的作用是滤除掉940nm之外的环境光,最大程度减少干扰,大大提高信噪比,但因为制造工艺的原因会比普通的截止滤光片贵不少。这一器件相对常见就不再展开讨论。
SPAD 单光子雪崩二极管 Single Photon Avalanche Diode
前述的VCSEL属于光源器件,是将电能转化为光能;光学镜头、DOE和滤光片则属于无源被动器件,即不用消耗电能;现在要讲的SPAD芯片则是将光能转化为电能,并且还能通过模拟-数字转换,将探测到的光信号最终转换成数字形式向外输出,是一颗集成了光电探测模块、模拟电路模块、数字电路模块的高度集成化的芯片,是相对比较新兴的领域,而且苹果还把它做成了大面阵的阵列,这也是阵列SPAD第一次在消费电子领域应用。乘着苹果的东风,第一次出场就是上亿数量级的超大规模量产,这与几年前VCSEL和DOE的消费级大规模应用几乎如出一辙,苹果也将SPAD sensor订单交与了最亲密的合作伙伴——日本索尼公司。 采用定制化工艺制造的固态SPAD尽管已经发明了几十年,但是之前一直存在两个问题: 一是器件体积大,价格昂贵; 二是器件与集成电路难以兼容。近几年来,基于CMOS工艺的SPAD阵列的成功设计和制造很好地解决了这两方面的问题,从远红外到深紫外频段SPAD都能实现单光子级别的探测灵敏度,与光电倍增管、APD等相比较,其具有更高的量子效率、更小的尺寸、更低的击穿电压,能识别单光子,可数字化成像,抗环境光干扰等特点,其最大的优势在于能够实现远距离测距,且具备较高精准度,因此在激光雷达、核医学设备、生物诊断、高能物理、射线探测、分析仪器等多个领域已有广泛应用。
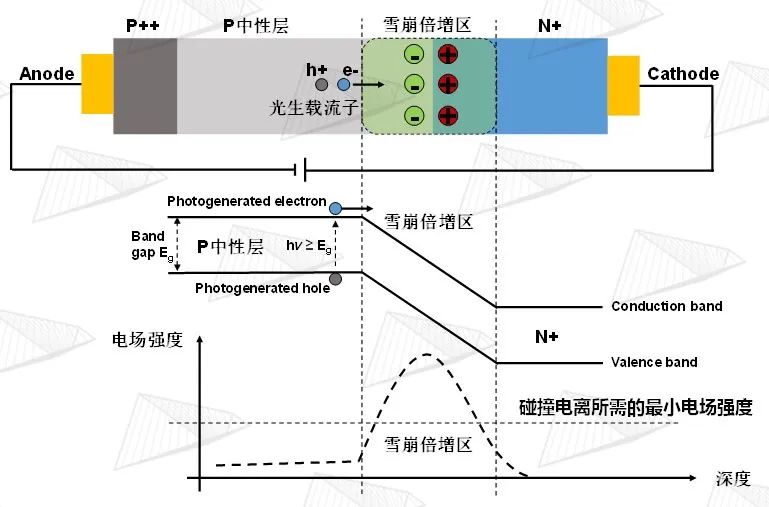
图6. SPAD工作原理
如图6所示,SPAD是一种基于内光电效应的光电探测器件,当在PN结两端施加足够的反向偏置电压时,光子被中性层吸收后将所携带的能量传递给价带上的电子使其跃迁至导带,从而产生光生载流子,在内部电势的作用下向雪崩倍增区漂移,当雪崩倍增区的内建电场大于碰撞电离所需的最小电场强度时,光生载流子获得更高的能量后被加速,与雪崩倍增区的晶格原子发生多次碰撞产生更多的电子-空穴对。这种雪崩倍增效应使器件内部的电子-空穴对呈现指数倍的增长,从而产生极高的光生电流。
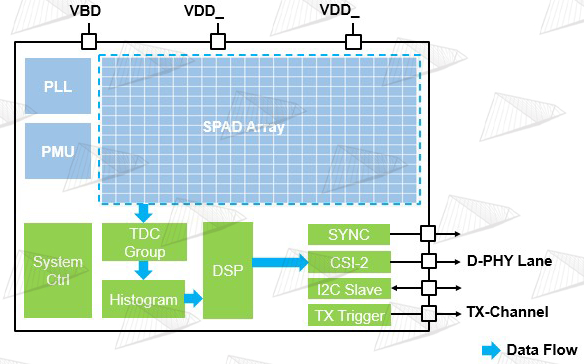
图7. 典型的SPAD sensor架构 图7展示了典型的SPAD sensor架构,可以看出是这是一种非常综合型的芯片,包含SPAD光电二极管、模拟电路、模数混合电路、数字电路等。
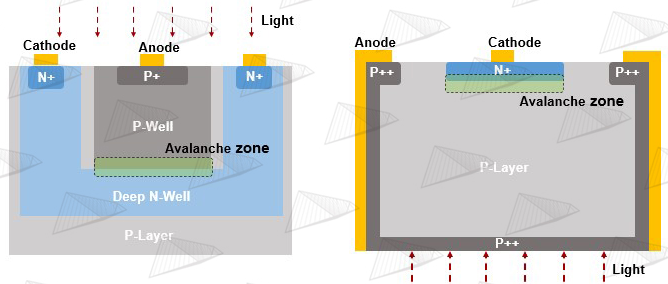
图8. 左右分别为典型的共阴极(Common Cathode)FSI和共阳极(Common Anode)BSI像素结构 如图8,与传统图像传感器类似,从制造工艺来分,SPAD sensor可以分为FSI(前照式)和BSI(背照式)两种类型。这两种结构在制造上的差异要远大于传统图像传感器,原因就在于每个像素都需要与TDC相连接,导致采用BSI的工艺会大大增加复杂度。
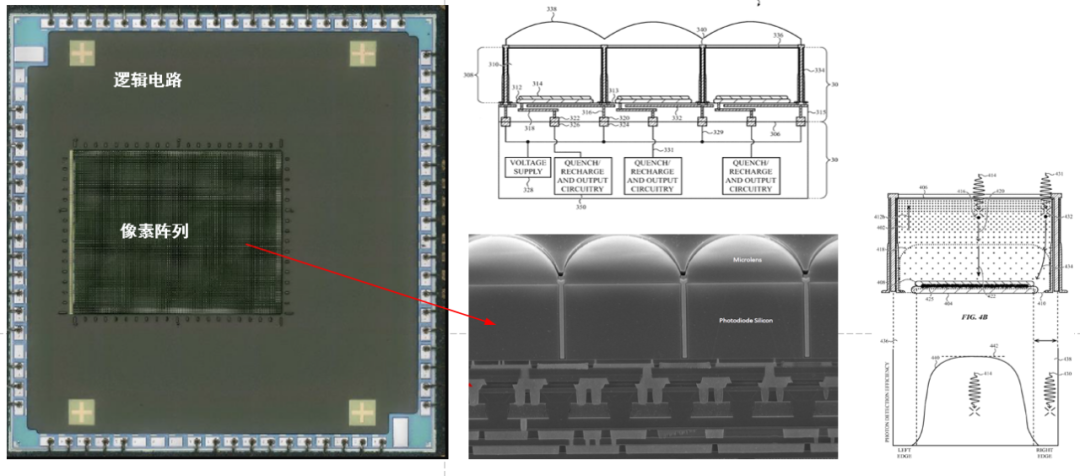
图9. 苹果采用BSI工艺的SPAD sensor实物图和像素剖面图 如图9,苹果采用的是BSI工艺,将SPAD层与逻辑电路层通过一种先进的低温铜-铜键合工艺连接起来,这样可以把逻辑电路完全掩藏在底部,从而使SPAD的受光面积达到接近100%,最大限度的提升感光效率,苹果在其专利中对此进行了详述。  高速高功率激光驱动电路 High Speed & High Power Laser Driver Circuit
高速高功率激光驱动电路 High Speed & High Power Laser Driver Circuit
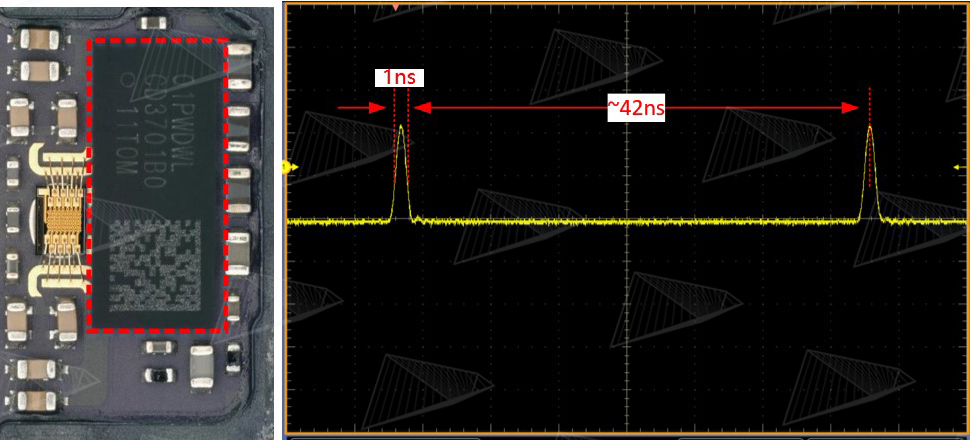
图10. iPhone激光雷达的驱动芯片和光脉冲,每秒发射约2400万个光脉冲
dToF的测量原理中要用到超短脉冲激光,因此也对激光的驱动电路提出了要求:1.脉冲宽度~1ns;2.瞬时电流在某些应用中最高要达到~20A。单看脉冲宽度,这不能算是很高的要求,但是要同时满足大电流就变得非常困难,由于大部分驱动芯片还是硅基形式,无法承载这么大的高速电流,因此不仅在消费电子领域几乎没有过类似的需求,即使在车载领域也很难找到一颗集成的驱动芯片来同时满足这两个要求。目前主要的解决方式是:短脉冲驱动芯片+GaN开关,未来将这二者集成在一起是趋势。无论如何,为了产生超短+高功率的激光脉冲,并且保持脉冲不变形,对激光器以及其驱动电路都提出了极高的要求。
系统篇
SYSTEM
前面我们对苹果Lidar中使用的各种器件做了逐一介绍,从中我们可以看到这些器件之间几乎没有相通之处,每一个器件都是一个独立的领域,集结了几何光学、衍射光学、光电子学、激光、半导体物理、模拟电路、数字电路等领域最前沿的技术,而且对于最终的产品系统来讲,这还只包含了一半的东西,剩下一半是算法软件。
3D视觉和2D视觉的一大区别就是3D视觉的软硬件具有非常强的耦合性,这会在下面讲到。 如此多前沿学科的交叉必然使得系统设计异常复杂,但是学科交叉又是最容易产生创新的地方,那么这么多的交叉会产生怎样的效果呢?接下来我们一起看看苹果到底是如何设计这套Lidar系统,根据公开专利显示在2014年左右,也就是苹果花了将近4亿美金收购PrimeSense(3D结构光公司)之后,就开始同步研究这一技术了。
我们首先从应用场景出发对产品规格提出需求,主要针对手机和Pad用户。因为是在后置模块,需要做3D建模、SLAM、AR渲染等应用,所以距离不能太近,但人是习惯于握着设备移动扫描的,使用距离肯定也不用像车载那么远,那么5米就是一个适中的范围;对于分辨率和视场角,Lidar的应用不需要像结构光一样多达数百万的分辨率,也不需要用来做Face ID等高精度应用,而是用于平面检测、空间定位、物体测量、虚拟场景和现实场景的1:1融合等等;结合对后续算法的综合平衡,起码要达到HQVGA分辨率,而视场角则与后置主摄像头匹配,可以略小一点;对于体积尺寸,毫无疑问,手机上最大的限制就是空间,可谓寸土寸金,而Lidar包含接收和发射两个模块,如何能够做得比一个普通的摄像头更小,而且还要小很多,这是极具挑战的,但这也是必须要满足的;对于功耗,Lidar使用起来时会持续工作,因此必须在300mw~500mw范围上下不能太大;对于使用环境,必须适用室内、室外、强光和弱光,全场景下都有同样的性能,这样才能让普通用户感受不到差别,但这其实是很困难的一项要求,一般来说在其他应用领域可以做取舍但对于手机用户而言是断然不行的;对于成本,当然是越低越好,考虑到是革命性产品,可以接受一定的溢价,从拆解情况来估算,苹果的Lidar物料成本大概在$10~$12之间,是完全可接受的。归纳如下:
使用距离:~5m
分辨率, 视场角:~HQVGA;~70°
尺寸:不能大于普通2D摄像头,越小越好
功耗:300mw~500mw, 越小越好
使用场景:全光照场景,24小时全天候
成本:$10~$12
需要注意是,以上需求必须同时满足。
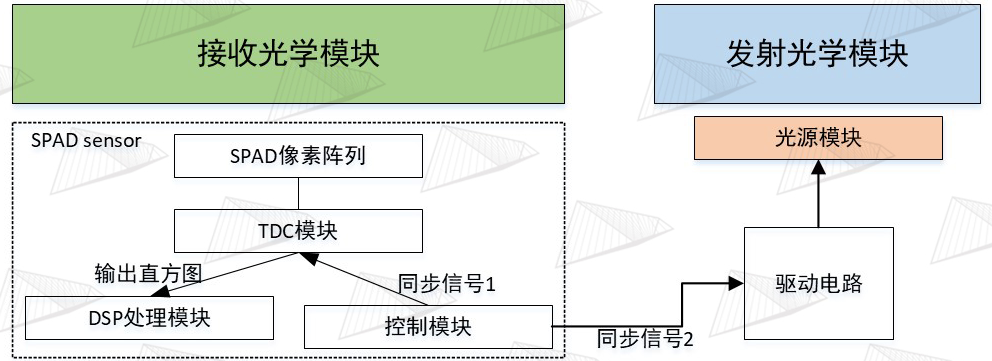
图11. dToF测量原理 在设计解决方案之前,我们先了解一下系统工作的基本逻辑和原理。典型的dToF系统的测量原理是:以单次测量周期为例,如图11,SPAD芯片内部的控制电路会发出“开始”信号,这一信号一方面会让内部的TDC计时器开始计时,另一方面会传送出去给到外部的激光驱动芯片作为同步触发信号,驱动芯片接收到触发信号后,会产生一个~1ns的超窄脉冲电流,触发脉冲信号和输出脉冲电流之间由于经过了Driver IC会有时延,这种时延一般是ns级,所以一般在其他的应用中都不太需要考虑,但在dToF测量系统中是不行的,这一时延需要在模组生产的过程中进行测量并且补偿,而且它还与温度相关,这会使得精准补偿的难度增加,在此不展开讨论。
VCSEL接收到电流脉冲之后开始发光(这里也会有时延产生,需要补偿),光束由准直镜放大准直后投射到DOE上,DOE经过复制扩散形成更大的投射范围,再经过场景中的物体反射回接收镜头,经过接收镜头的缩小成像后照射在SPAD阵列上, 雪崩二极管接收到光脉冲后会产生雪崩电流,致使TDC的计时中断,从而得到一次飞行时间t1,同时淬灭复位电路会将测量电路快速复位,等待下一个测量周期的光脉冲到来,这样经过多次重复该过程就算是一次完整的测量。假设测量N次,其中n次有效(n
根据以上原理,在不同领域正在量产和即将量产的Lidar解决方案主要分为:旋转式扫描方案、以MEMS Mirror(微振镜)为代表的半固态扫描方案、以面阵Flash照明为代表的全固态方案这3种形式。但是苹果的方案却异常独特,为了满足上述所有系统规格要求,苹果采用了一种基于可寻址VCSEL点阵扫描的全固态方案,如图12所示,我们可以把它称之为Spot dToF。
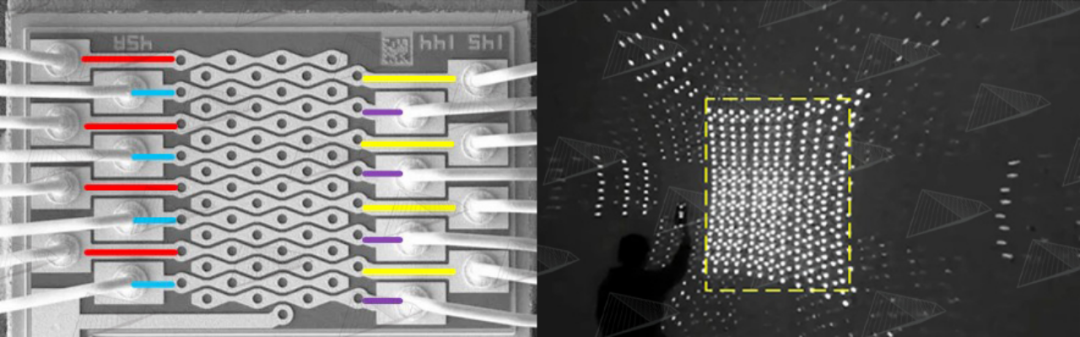
图12. 苹果激光雷达使用的VCSEL,总共64点。其中红、黄、蓝、紫每4行为同一组,这4组点阵是并联关系,分时点亮,配合光学系统投射出激光散斑,达到扫描目的,如右图所示。图中黄色虚线框之外的点阵是由DOE的高阶衍射造成的,不影响效果。 与一般的均匀分布的面阵Flash照明不同,苹果这种方案采用了与3D结构光类似的点阵激光,但不同于结构光超过3万个激光点阵,Spot dToF仅仅只有576个激光点阵,相差50倍,不过其单点功率要远高于结构光。之所以采用点阵是因为在相同电功率下,其出射的光能量密度要远远高于面阵方案,按照估算,差别甚至可以达到15~30倍,这样可以解决两个非常棘手的大难题:
1 在户外使用时阳光干扰的问题,光功率密度的大幅度提升能够使得即使在阳光干扰的状态下,仍然可以保持足够的信噪比,所以大家会看到苹果的Lidar即使在盛夏最强的阳光下效果依然不下降。 2 由于点数少,光功率密度大,因此VCSEL不需要很大的瞬时电流,也就不需要引入大功率器件,极大地缓解了手机硬件电路的设计压力,可以完全与当前的设计兼容。 采用这种点阵方案不仅能够维持户外使用的效果,而且由于能量集中,其抗干扰能力也会得到极大的加强。总而言之,在手机这种限制极多的情况下,Spot dToF是手机后置3D视觉的最优解。 不过,在获得最佳效果的同时,同样也带来了两大挑战:
1 这种全固态的点阵扫描对光学系统设计提出了极高的要求;
2 由于只有576个点(24*24),获得的有效分辨率太低,与系统规格中要求的HQVGA差了70倍~80倍。
如果能克服这两大问题,那么就不会再存在技术瓶颈了,这两个问题正是苹果dToF Lidar真正的核心所在。
我们先来看怎么解决第一个问题。前述的SPAD芯片中的TDC计时器是一种非常消耗硬件资源的模块,如果要一次全部同时曝光则需要576个TDC,这样会大大增加芯片面积,进而增加芯片成本、模组体积和功耗。因此可以采用144个TDC进行时分复用,每次只采集144个激光点阵的飞行时间,分4次采集,这样就可以减少TDC数量,降低成本、体积和功耗,并且由于dToF的单次测量时间是ns级的,所以不用担心由于时分复用导致最终系统帧率不足。同时,为了完美配合TDC的工作,实现能量零浪费,VCSEL上的激光点也被相应地分成了独立的4组,我们可以称之为“可寻址阵列”,每组16个点,经过DOE复制变成144个点,对应144个TDC。
如此,虽然VCSEL有64个点,但实际上同一时间工作的只有16个点,那么VCSEL的驱动电流只需要能够同时点亮16个点即可,大大减轻了Driver IC的负担,按估算只需要~2A电流即可,这样用一般的硅基芯片就能实现。由于这4组点阵是完全独立的,因此Driver IC也要有4路独立的驱动,不过对于Driver IC来说,除了增加一些设计难度,硬件上的资源增加是完全可控的。根据拆解情况,是德州仪器TI为苹果定制了这颗比较独特的Driver IC,并且其中应该还集成了用于检测ITO电路状态的功能。ITO是一种透明的导电玻璃,嵌入在DOE里用于实时监测DOE的状态是否正常,DOE的状态正常与否会影响出射激光的功率密度,引发人眼安全问题。 上面我们讲到TDC时分复用,并且每个TDC同时只对应测量一个激光点斑,这是比较好理解的。
那么问题在于用来接收的sensor是一个像素阵列,每一个像素都是一个独立的SPAD,分辨率大概是200*150=30000,我们知道TDC是要与SPAD连接在一起工作的,那么144个TDC如何能与30000个TDC相连接呢,就算时分复用的话,那么每个TDC要与3000/144≈200个SPAD连接,然后分时工作200次,这显然与上述的分4次工作相去甚远。
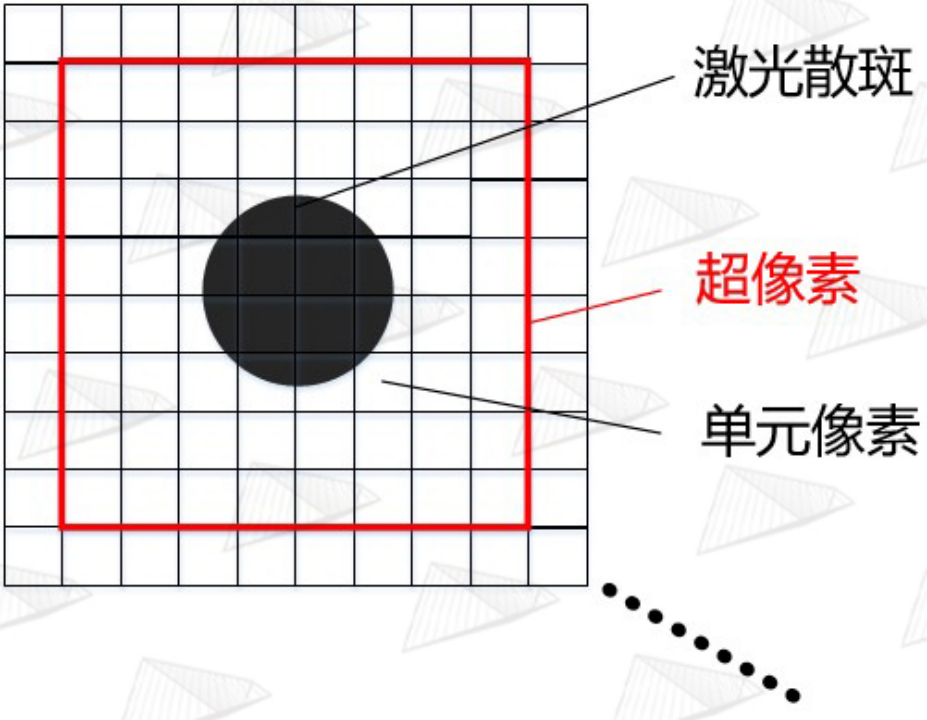
图13. 超像素结构示意图
我们在这里引入苹果称之为超像素(Super pixel)的概念,如图13,其实就是把m*n个单元像素通过类似在CIS中常用的Binning方式来合并,变成1个像素,这个像素就称为超像素,而TDC连接的就是这个超像素。每个超像素就是一个小区域,其中包含了数十个单元像素,在这个超像素工作的时候,对应的激光斑点就落在这个超像素内,从而进行感光测量。知道这个概念之后,既然有576个点,那就应该对应有576个超像素,每个超像素由约50个SPAD单元像素组成。这576个超像素也分成4组,又因为只有144个TDC,所以每个TDC连接4个超像素,然后分时复用,144*4=576,这样就与前述问题符合了。
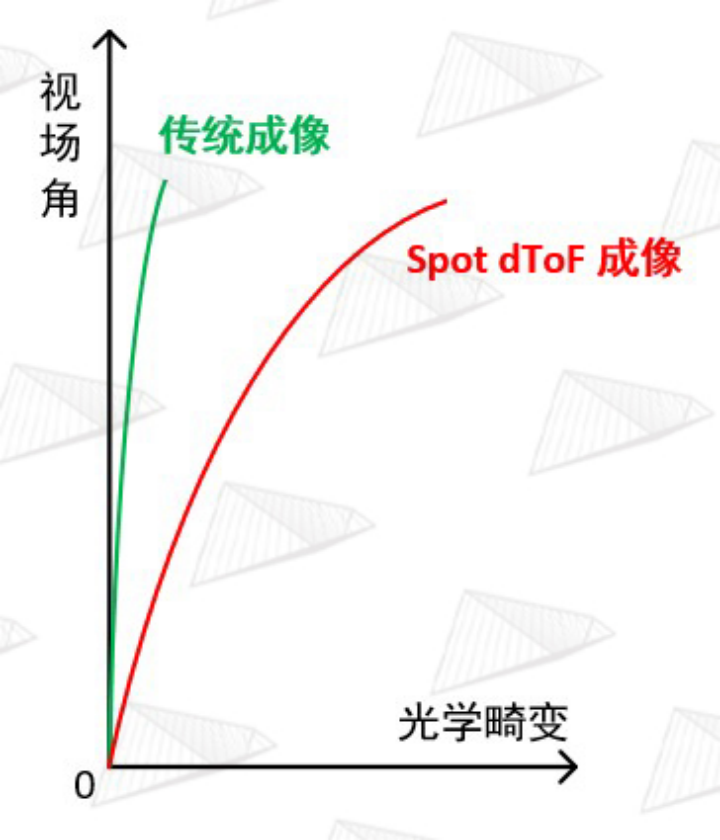
图14. Spot dToF 成像镜头的畸变要远大于传统镜头以补偿DOE的投影光学畸变
图15. (a)实拍iPhone激光雷达散斑 (b)安思疆自研SimuLight 2.0仿真引擎设计结果 (c)SimuLight 2.0仿真引擎光学畸变校正后的结果,其中第1、5、9、……、41、45行1组,第2、6、……、42、46行1组,第3、7、……、43、47行1组,第4、8、……、44、48行1组,四组分时点亮形成扫描。
以上讨论了SPAD芯片是如何配合测量系统工作的,总结一下就是144个TDC能同时对应144个超像素,144个超像素对应144个激光散斑,分4次扫描,就可以得到144*4=576个激光散斑对应的距离。那么问题又来了,由于同一时间只会有144个超像素在工作,剩余的432个超像素是不工作的,如果这时候激光散斑没有落入正在工作的超像素上,那就无法测量,因此必须要为此设计一套精密的光学投影及成像系统,保证VCSEL发射的激光散斑能准确的落入正在工作中的超像素内。
苹果采用了与结构光类似的发射和接收方案设计,在发射端采用了可寻址的VCSEL,分成4组,每组16个激光点会同时亮,然后通过Collimator准直和放大,接着经过DOE 3x3复制再扩大后,投射出144个激光散斑,经过场景的反射之后由接收端的imaging lens精准地成像在对应的超像素之内,以便完成测量。但此处有个非常棘手的问题,DOE的衍射由于满足的是正弦方程,当投影角度变大时会导致散斑发生显著畸变,这在3D结构光中是允许存在的,可以通过算法校正,但是在spot dToF Lidar中是不可行的,因为sensor上超像素的排列必须是规则的,如果散斑的排布发生畸变,则会导致视野边缘的散斑落入非工作的超像素内,进而测量无效,这是绝对不允许的。
为了解决DOE带来的光学畸变问题,苹果将imaging lens的光学畸变也设计得非常大,如图14和15所示,做了很大的反畸变来补偿DOE的正畸变以达到校正畸变的目的,并且由于引入如此大的光学畸变,还必须要在后处理的算法中对得到的三维点云再次进行校正以消除imaging lens的畸变。这一设计是非常罕见的做法,因为降低并消除光学畸变是几乎所有成像镜头设计的基本追求,但在苹果的lidar系统中不这样做又不行,实际上这种“反其道而行之”的设计是该光学系统中最难设计的一部分。这样的复杂系统也导致了各器件之间的耦合度到达了前所未有的程度,任何一个器件的某一参数改变,都会带来其他器件的随之更改,否则将会直接导致整个系统不工作。
在系统设计上还剩下最后一个关于超像素的问题,实际是两个,一方面由于发射和接收采用的是非同轴设计,会产生视差,因此必须要综合考虑使用距离、模组尺寸、单元像素大小、组装误差等众多因素,才能最终确定超像素的子单元像素的数量,在苹果方案中此数量大概是50个。另一方面,散斑在SPAD阵列上成像的大小一般只占据超像素其中的几个单元像素,例如9个,但如果把整个超像素的探测深度都定义为同一个深度的话,就会大大降低其空间的横向分辨率,即XY方向的分辨率(假设深度是Z方向)。
举个简单例子,这可能会导致最终完全分辨不清手指和整个手,如此低的分辨率是不能接受的,为了解决这一问题,苹果在每个超像素中还划分了更细的像素组合,我们可以把它叫做超细像素,这些超细像素会在测量周期的前段进行扫描,从而准确定位散斑在超像素中的位置,接着再进行全面的测量。这一过程也是十分复杂的,又大大增加了SPAD阵列的设计难度,此处不再赘述。
到此为止,还差最后一个问题就能说完了,虽然这个问题只占一个环节,但却占一半的重要性,那就是配套这个系统的算法。按照上述的方案,如果所有器件都完美地协同工作,我们就能得到576=24*24分辨率的精确深度图,但相信大家都能看出问题,那就是分辨率太稀疏,完全没有发挥SPAD阵列30000=150*200分辨率的能力。这就需要通过软件来补齐最后的这一短板,苹果应用了当前AI&机器视觉领域最前沿的研究成果,利用主摄单目RGB生成稠密但不准确的深度,利用Spot dToF生成稀疏但准确的深度,最后利用神经网络引擎将两者进行算法融合,得到一幅既稠密又准确的深度图,也就是我们在手机上最终看到的效果。当然这一过程并不像此处所讲的这么简单,也需要庞大的工程量,安思疆也是经过了2年的研究才有成果。
图16. (a)主摄2D彩色图像 (b)Lidar正常工作时生成的深度图,不同颜色代表不同的距离 (c)只遮挡Lidar Scanner (d)只遮挡主摄像头
如图16所示,iPhone的Lidar Scanner实际上还结合了它左边的主摄像头,两者正常协同工作时,才能得到深度准确且轮廓清晰的深度图,如(b)所示;当单独遮住Lidar Scanner时,如图(c)所示轮廓依然清晰,但此时颜色发生很大变化,说明深度不准确;当单独遮挡主摄像头时,如图(d)所示颜色虽然准确,也即深度虽然准确,但是轮廓细节已经丢失,即当Lidar单独工作时就会出现前面所述的深度太稀疏的缺陷。以上情况充分说明,只有当主摄像头、Lidar scanner、AI深度融合算法同时工作时,才能得到理想的结果。苹果在这里使用的算法叫“Sparse-to-Dense”,稀疏转稠密算法,这是当前AI视觉领域最前沿的课题之一。安思疆对此也进行了深入研究,同样取得了理想结果。
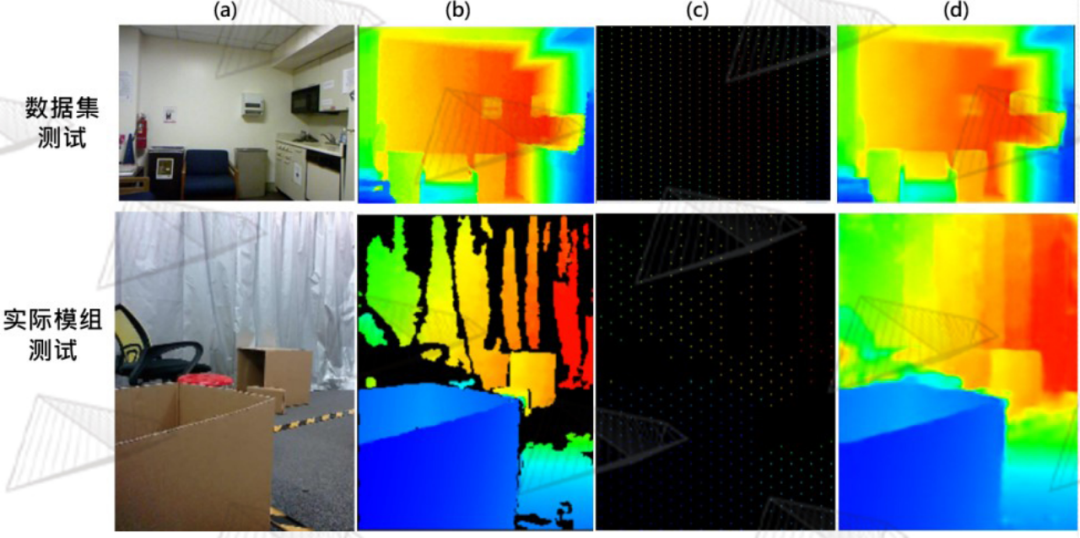
图17. (a)2D彩色图像 (b)Ground truth (c)稀疏深度 (d)融合后的深度
通过安思疆现有的高精度模组可获取大量高质量的3D数据,带来了极大便利,在此基础上采用了一种有监督的深度学习算法,得到高质量的深度融合模型。如图17所示,我们分别在公开数据集和实际模组中对自研的融合算法进行了测试,可以看到很理想的效果呈现。 苹果Spot dToF激光雷达的解析到这里就基本结束了,因为采用了如此复杂的设计,这颗激光雷达的生产组装也异常复杂,由韩国LG最先进的工厂为其代工。
一颗小小的激光雷达,其中蕴含了如此多的黑科技,即便复制都很难,其背后的研发投入必定是巨大的,这也是其产品定价的底气所在。难,才是价值所在,安思疆立志与产业界一道攻坚克难。
编辑:黄飞
















 工商网监
工商网监
评论