 电子发烧友App
电子发烧友App


毛 军,付 浩,褚超群,何晓峰,陈昶昊
摘 要:同时定位与建图(SLAM)技术已广泛应用于各类自主移动平台中,其中视觉SLAM和激光雷达SLAM是两种主要的SLAM技术方案。然而,视觉SLAM系统易受视觉环境变化的影响,而激光雷达SLAM系统则在结构单一等环境中会出现精度退化甚至失效的情况。随着智能移动平台应用场景的不断拓展,对SLAM系统的精度和鲁棒性等提出了更高要求,将多种具有互补性的传感器进行融合是提升SLAM系统性能的有效途径。据此,聚焦惯性/视觉/激光雷达多传感器融合SLAM技术,从多传感器标定和多源数据融合两个主要方面进行综述,最后对多传感器融合SLAM技术的发展趋势进行了展望。
作者简介:毛军(1989-),男,博士,讲师,主要从事视觉导航、组合导航、仿生导航方面的研究。
通信作者:付浩(1986-),男,博士,副研究员,主要从事地面无人平台环境感知方面的研究。
0 引言
同时定位与建图(Simultaneous Localization and Mapping,SLAM)技术是指移动机器人利用自身搭载的传感器构建环境地图,同时利用环境信息进行自主定位。SLAM因具有较好的自主性和精度而广泛应用于各类移动平台中。
SLAM最早于20世纪80年代被提出,早期的SLAM系统主要是基于单线激光雷达传感器构建的,且仅适用于在二维平面中运动的载体。随着激光雷达技术的发展,基于激光雷达的3D SLAM系统得到迅速发展。目前,性能较好的激光雷达可以实现百米外厘米级的测距精度,支撑了一系列高精度SLAM应用场景。然而,激光雷达SLAM仍面临众多难题,例如在自运动较快时雷达数据会发生畸变,导致SLAM精度下降;此外,在隧道、高速路等结构特征不明显的区域,雷达帧间数据难以配准,会造成SLAM系统退化甚至失效。
相较于激光雷达SLAM系统,视觉SLAM系统具有不主动发出信号的优点。此外,视觉是对环境的稠密感知,可以利用视觉特征构建出更符合人类感知的环境地图。然而,视觉传感器本质上是一种角度测量传感器,不能直接测量距离信息,因此需要从多视图中重构出特征的距离。而且,复杂变化和特征匮乏的视觉环境也会对视觉SLAM系统造成影响甚至使得系统失效。
激光雷达、相机和惯性测量单元(Inertial Meas-urement Unit, IMU)三者之间具有较好的互补性。IMU测量不受环境特征的影响,惯性导航系统仅基于载体运动产生的惯性信息就可以对速度、位置和姿态进行全参数估计。惯性导航估计的运动参数可用于校正雷达数据的畸变、补偿单目视觉缺失的尺度信息等;而激光雷达SLAM和视觉SLAM测量的载体运动则可以校正惯性导航系统的累积误差。近年来,惯性/视觉SLAM、惯性/激光雷达SLAM、视觉/激光雷达SLAM等基于多传感器融合的SLAM系统发展迅速,并且展现出比基于单一传感器更高的精度和更强的环境适应性。
经过30多年的发展,SLAM框架已日趋成熟。T.Bailey等[1]对SLAM算法框架进行了介绍;J.Fu-entes-Pacheco等[2]则对视觉SLAM技术的主要方法进行了综述。2015年,C.Cadena等[3]在Robotics: Science and System (RSS)会议上对SLAM技术的发展进行了综述,并对其未来发展趋势进行了展望,认为鲁棒的感知端是未来SLAM技术发展的重要方向。将IMU、相机和激光雷达进行组合是提升SLAM系统精度和鲁棒性的重要方式,相较于视觉SLAM和激光雷达SLAM算法,多传感器SLAM技术涉及信息融合技术,因此有必要进行详细的分析。本文首先从SLAM的基本原理出发,分析其对多传感器融合的需求;然后从多传感器时空配准和多传感器信息融合两方面对惯性/激光/视觉组合SLAM技术进行介绍,并对基于多传感器融合的SLAM技术进行展望。
1 SLAM简述
移动机器人在未知环境中运动时,可以通过SLAM系统构建环境地图,同时利用构建的地图进行自主定位,如图1所示。本节首先介绍了SLAM的数学模型,然后简要分析SLAM系统对多传感器融合的需求。
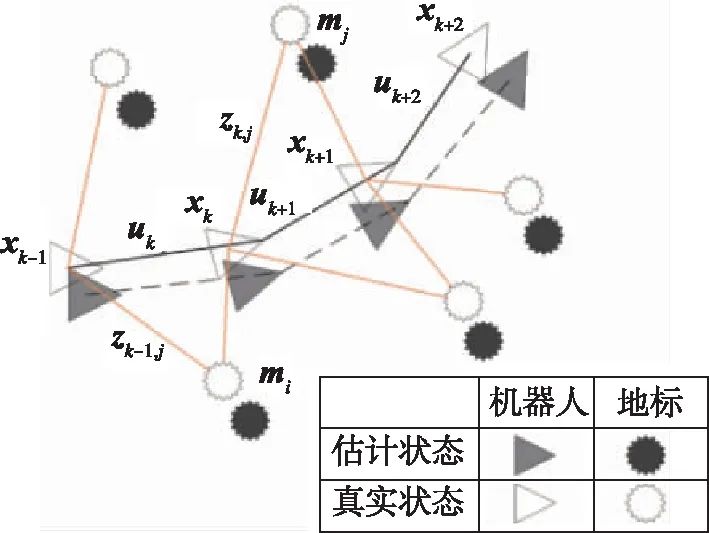
图1 SLAM原理示意图[4]
Fig.1 Schematic diagram of SLAM
1.1 SLAM模型简介
设SLAM问题中待估计的机器人运动参数为X0:k={x0,x1,…,xk},其中xk表示k时刻载体的位姿参数;设SLAM构建的地图可表示为一组地标的集合M={m1,m2,…,mn},其中mn表示第n个地标在地图中的位置。机器人在移动过程中可以通过传感器对地标进行观测,这些观测的集合表示为Z0:k={z0,z1,…,zk};而驱使机器人从xk-1到xk转移的控制量为uk,在移动过程中所有控制量的集合表示为U0:k={u0,u1,…,uk}。
SLAM就是根据观测Z0:k和控制输入U0:k,估计运动轨迹X0:k和地标位置M的过程。在SLAM算法框架中,对观测Z0:k的提取部分通常被称为SLAM的前端(front-end);而利用Z0:k和U0:k对运动轨迹和地标位置进行估计的部分被称为SLAM的后端(back-end),如图2所示。
前端算法一方面要从每一帧的传感器数据中提取出地标观测信息,另一方面利用数据关联方法判断新一帧数据中的观测地标是首次观测到的新地标还是某一已经被观测到的旧地标。由于不同的SLAM系统使用的传感器不同,因而观测信息的提取方式也有较大差异。例如,在激光雷达SLAM中,通常直接采用三维点云描述环境;在视觉SLAM中,则可以采用像素的光度或视觉特征描述地标。建立帧间观测的关联也是前端算法的重要组成部分,数据关联算法与地标描述方法紧密联系。在激光雷达SLAM系统中,广泛使用迭代最近点(Iterative Closest Point, ICP)[5]、正态分布变换(Normal Distributions Trans-form, NDT)[6]等方法进行帧间点云配准[7]。在视觉SLAM系统中,则主要采用光流跟踪[8]、特征匹配[9]等方式建立帧间观测关联。
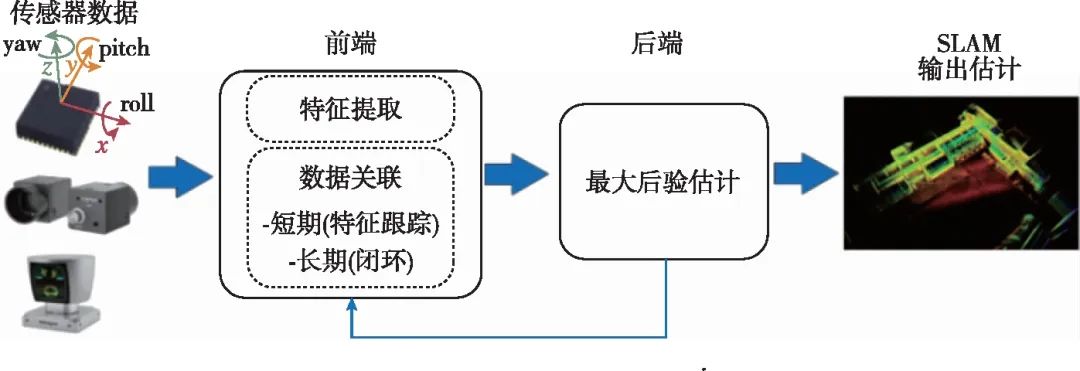
图2 SLAM算法架构图[3]
Fig.2 Scheme of the SLAM algorithm
经过30多年的发展,SLAM后端算法模型已日趋成熟,大致分为基于最大后验概率(Maximum A Posteriori, MAP)优化、拓展卡尔曼滤波(Extended Kalman Filter, EKF)和粒子滤波等三类后端处理算法[4]。由于粒子滤波算法也可以被认为是一种MAP问题的求解方式,因此本文主要介绍MAP和EKF两种后端处理算法。MAP和EKF算法可以概括为两个主要步骤:第一步是根据uk和xk-1对xk进行预测;第二步是根据观测zk对X0:k和M进行估计。MAP模型可以用式(1)表示
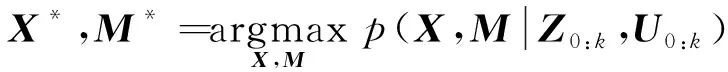
(1)
在多数SLAM系统中,采用高斯误差模型和一阶马尔可夫模型近似后,式(1)的求解可以转化为一个非线性最小二乘求解问题,即
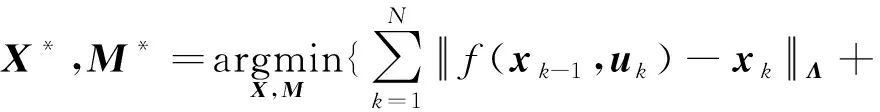
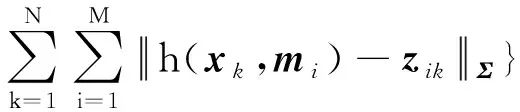
(2)
其中,mi表示第i个地标;zik表示k时刻对mi地标的观测;f(·)和h(·)分别表示运动模型和观测模型,Λ和Σ则表示相应模型的信息矩阵。在EKF方法中,f(·)和h(·)分别表示状态转移函数和观测函数。当载体运动时间长、观测特征多时,SLAM中待估计的参数量也会增大。但通常情况下,某一个地标点仅在少数几个位置能被机器人观测到,这在数学上就表现为f(·)和h(·)具有明显的稀疏性,利用这种稀疏性可显著提升SLAM的后端算法效率。目前,常用的MAP优化工具箱有g2o[10]、GTSAM[11]和ceres[12]等,而EKF后端算法中常用的有多状态约束卡尔曼滤波(Multi-State Constraint Kalman Filter,MSCKF)[13]方法。
1.2 多传感器融合SLAM系统需求
由于传感器的限制,激光雷达和视觉SLAM在载体动态性较强、环境复杂条件下都面临诸多问题。将多种具有互补性的传感器进行融合是构建高精度、高鲁棒SLAM系统的重要途径。
惯性导航信息可用于提升视觉和激光雷达SLAM的前端和后端算法性能[14-15]。如图3所示,由于激光雷达在扫描过程中载体是运动的,当动态性较强时,常用的匀速补偿模型难以校正帧内点云的畸变;而惯性导航系统能以较高的频率测量激光雷达一个扫描周期内的运动信息,这些运动信息可有效地校准雷达点云数据。惯性导航的输出结果对于帧间数据匹配也具有重要辅助作用,其可以作为帧间匹配算法的初值,而相对准确的初值可以有效提升配准算法的精度和收敛速度。惯性导航输出信息还可用于补偿运动造成的图像模糊,从而提升视觉SLAM的前端鲁棒性。
在SLAM后端算法中,融合IMU信息对提升SLAM精度和鲁棒性也具有重要意义。基于激光雷达和视觉的SLAM系统通常采用匀速模型来近似运动模型f(·),而在动态性较强时,该近似方法会导致模型精度下降。惯性传感器能以较高的频率输出载体的运动信息,利用惯性导航输出可构建更为准确的SLAM模型。在单目视觉SLAM系统中,惯性信息还可用于补偿缺失的尺度因子。另一方面,视觉和激光雷达对地标的观测信息则可用于校正惯性导航的累积误差,从而实现组合增强。
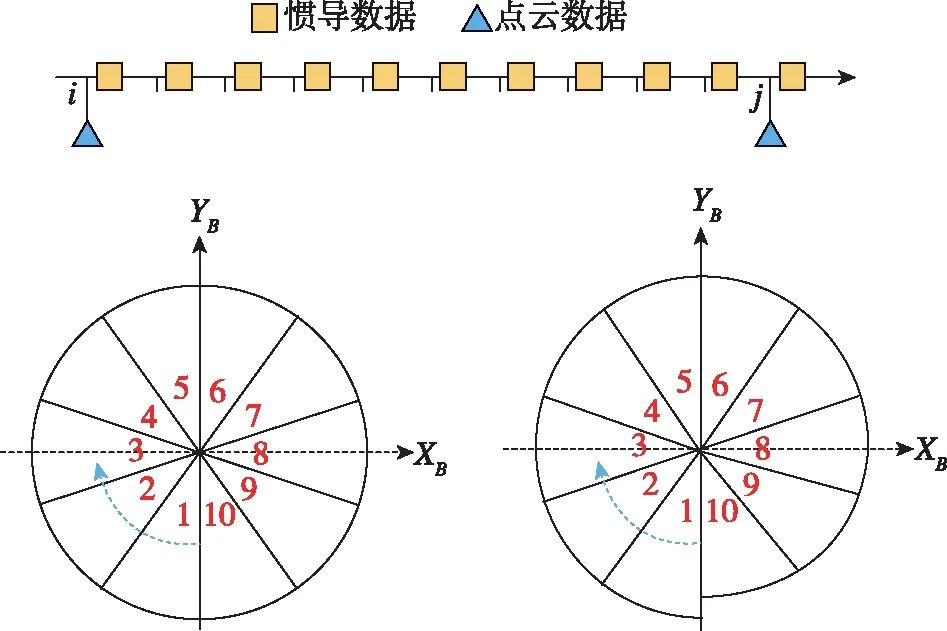
图3 利用惯导校正激光雷达帧内畸变的示意图
(当车体静止时,雷达在地面上扫描的数据为一个圆形
(如左图所示);当车体向前运动时,这个圆形会产生一定的
畸变(如右图所示);在雷达采样周期内(通常为100ms),
可以接收到多个惯导数据,利用这些惯导数据可以对雷达
数据进行帧内校正)
Fig.3 Illustration of undistorting a Lidar scan
with the aid of an inertial navigation system
(Illustration of the lidar scans captured in a sampling
duration. Left: when the agent is static and the scans form a
circle. Right: when the agent is not static, the sampled data
contains distortions. By using the motion parameters estimated
by the inertial system, the lidar data distortion can be fixed)
相机与激光雷达之间具有显著的互补性。激光雷达仅能测量地标的距离信息,当地标特征受运动物体遮挡时,仅利用点云的几何信息难以与地图进行配准。将相机与激光雷达配准后,可以将相机感知的视觉特征信息赋予雷达点云,然后利用特征的相似性辅助点云配准。相机本质上是一种角度测量传感器,在成像过程中地标特征的距离信息丢失,因此在视觉SLAM系统中需要根据多帧或多目的观测重构地标的三维位置信息,这给SLAM算法带来了负担。在光照、视角等发生强烈变化时,视觉SLAM前端也面临失效风险。将激光雷达测量的距离信息赋予视觉特征可实现三维视觉功能,同时在视觉环境发生变化时,激光雷达测量的三维结构仍能保证SLAM前端的正常运行。
综上所述,IMU、相机和激光雷达之间具有较强的互补性,将惯性/视觉/激光雷达进行融合是提升SLAM系统精度和鲁棒性的重要途径。然而,将这三种不同的传感器进行融合首先需要对传感器进行标定,然后还需要对SLAM算法进行设计,以有效融合三种异源信息。
2 惯性/视觉/激光雷达标定方法
对异源传感器的精确标定是有效使用传感器测量信息的前提条件。通常,对单个传感器的标定称为内参标定,而对不同传感器之间的相互关系的标定则称为外参标定。外参标定一般包括时间同步和空间标定两个部分。本文主要关注IMU、相机和激光雷达之间的外参标定方法,对于传感器内参标定,读者可查阅相关文献。
2.1 时间同步
时间同步的含义是使不同传感器数据具有统一的时间基准,以方便后续的数据融合。为了实现相机图像数据与激光雷达数据具有较小的采集时间间隔,文献[16]在旋转的激光雷达下方安装了一个簧片探针,当激光雷达旋转至车体正前方时,簧片探针产生一个外触发信号,控制前视相机开始产生一帧图像。
影响相机成像时间的因素还包括相机曝光时间和快门方式。目前,大多数相机都采用自动曝光时间方法,其优点是能够产生当前场景下尽可能清晰的图像,但缺点是曝光时间变得不可控。相机的快门方式分为全局快门(global shutter)和卷帘式快门(rolling shutter)。全局快门是指图像的所有行同时进行曝光,而卷帘式快门则是逐行进行曝光,图像顶部和底部的曝光时间差异可能高达几十毫秒,若是不考虑这种时间上的差异,则会降低图像帧间匹配的性能,从而影响融合定位结果。为了克服卷帘快门效应,文献[17]提出了采用B样条插值方法拟合出任意时刻的相机位姿,从而实现对场景更精确的建模和位姿估计。
待融合的多源传感器信息可能会由连在同一局域网上的多台计算机并行处理,为了保证不同信息源的时间一致,需要将不同计算机的系统时间设为一致。此时,既可以采用网络时间协议(Network Time Protocol,NTP)进行软件上的时间同步,也可以安装卫星导航授时设备等对多系统时间基准进行标校。
对于激光雷达来说,其数据通常都是通过用户数据包协议(User Datagram Protocol,UDP)进行广播。每个数据包都包含一个时间戳,该时间戳通常来自于激光雷达的内部时钟,可以通过外接卫星导航接收机对内部时钟进行校准。
2.2 相机/激光雷达标定
相机和激光雷达都是直接对环境中的地标进行测量,其中激光雷达测量的是地标距离传感器的距离,而相机可以感知地标的视觉纹理和相对相机坐标系的角度,二者间的标定是一个典型的手眼标定问题,如图4所示。
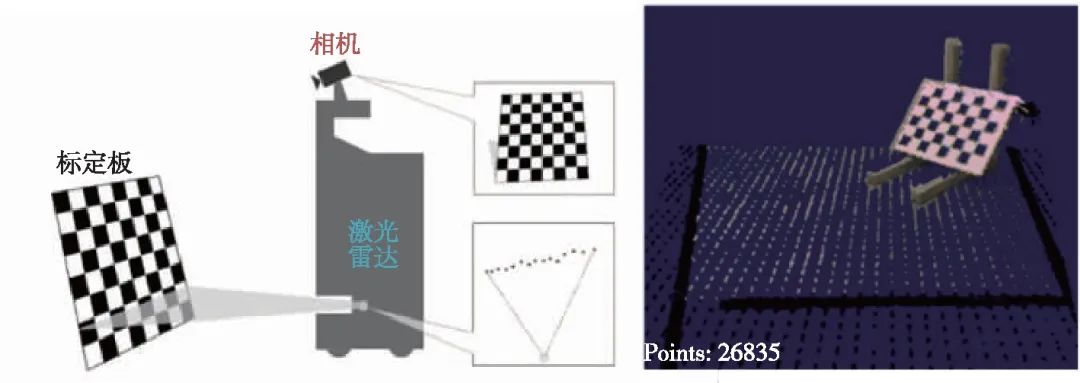
图4 相机/激光雷达标定示意图[18-19]
Fig.4 Illustration of camera-lidar calibration[18-19]
记视觉传感器为c,其内参标定矩阵为K;激光雷达传感器为l,二者刚性固联于平台载体上。手眼标定问题的实质就是求解两个传感器坐标系间的相对位姿变换Trc_l=[Rc_l,tc_l],该变换关系可以将雷达坐标系l中的一点lPi变换至相机像素坐标系cpi
cpi=π(K*Trc_l*lPi)
(3)
其中,π表示相机投影映射。因此,相机-雷达的手眼标定问题可以被数学描述为最小化式(4)中的残差问题
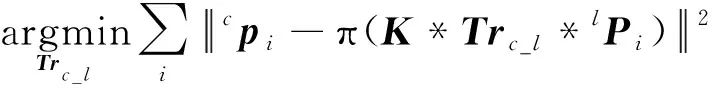
(4)
求解以上问题的关键就是要获得对应点对{lPi,cpi}。为了获得精确的对应点对,很多算法都采取在场景中放置特定标定物的形式来辅助寻找对应点对。文献[18]是最早进行相机-雷达标定的工作之一,该文尝试将相机与单线雷达进行标定,通过在场景中放置棋盘格,提取棋盘格在雷达数据中形成的线状特征,进而求解相机-雷达外参;文献[19]提出了一个包含人机交互界面的相机-雷达标定软件,可以在少量人工参与的情况下快速完成标定工作;文献[20]综合利用棋盘格的边缘信息和平面信息,仅需要将棋盘格放在某一固定位置处即可实现标定;文献[21]利用棋盘格的尺寸信息克服雷达数据的固有噪声和多帧数据拼接时产生的误差,通过对棋盘格进行更精确的位置估计,从而得到更精确的标定结果;文献[22]设计了一种包含4个棋盘格和4个圆孔的标定板,能够标定多种不同线束的雷达。
除了采用特点标志物来辅助计算对应点对外,近年来研究人员也提出了一些在自然场景中无需辅助标定物的标定方法。例如文献[23]提出了一种利用图像中的灰度边缘信息和雷达点云中的深度边缘信息进行匹配标定的方法,作者认为深度边缘往往对应的就是图像灰度边缘。因此,可以先在雷达点云中计算出深度边缘点,进而将这些深度边缘点投影至图像中,计算这些投影点与最近图像边缘线的距离,优化的目标就是使得这些投影点到图像边缘线间的距离最短。类似的想法也出现在文献[24]中,作者将雷达投影点到图像边缘线间的距离看成一种标定性能评价指标,利用该指标可以判断在某一时刻图像和雷达是否因网络阻塞或其他原因导致二者无法实现较好的匹配对应。
从标定精度来看,相机-激光雷达外参标定本质上还是一个最小二乘问题,因此如果能获得更多更精确的匹配对应关系,则标定精度就会更高。相较于无需辅助标定物的标定方法而言,借助棋盘格等辅助标定物的标定方法由于可以对棋盘格的尺寸进行精确测量,因此可能会得到更高的标定精度。但无需辅助标定物的标定方法由于其标定过程更加方便,因此更受研究人员青睐,也是目前的一个研究热点。
2.3 惯性/相机标定
相较于相机与激光雷达都是对地标特征的测量,IMU和相机的测量信息之间差异较大。为标定IMU/相机之间的外参,J.Alves等[25]提出了将固联的IMU和相机固定于一个单摆上,然后以测量得到的单摆运动作为参考进行标定。然而,该方法需要借助外部设备,对标定设备具有一定的要求,且标定效率不高。仅利用IMU/相机自身的测量信息进行外参标定,则摆脱了对外部测量设备的需求。F.M.Mirzaei等[26]和M.Fleps等[27]分别提出了一种基于EKF和非线性优化的自标定方法。这种方法仅使用了一个棋盘格标定板,然后通过采集相机面对标定板运动的图像和惯性信息就可以对外参进行准确估计,如图5所示。使用标定板的标定算法原理与1.1节所述的SLAM原理相似,视觉标定板提供的已知地标位置信息为IMU/相机外参联合标定提供了参考。通过对标定算法的可观性进行分析还发现,采集的数据中需要包含足够的旋转运动激励才能保障算法的收敛性。先治文[28]提出了一种多位置静态标定方法,不需要采集运动信息就能对IMU和相机的外参进行标定,但这种标定方法需要将视觉标定板放置于高精度水平台上。
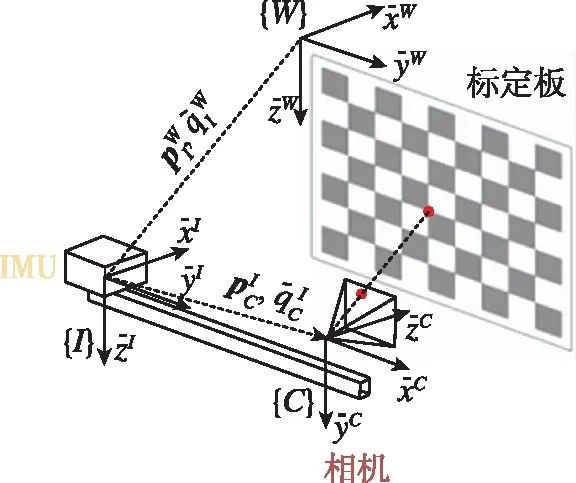
图5 惯性/视觉标定示意图[29]
Fig.5 Illustration of visual-inertial calibration[29]
在以上介绍的标定算法中,通常认为IMU和相机之间的数据是时间对齐的。然而,不同的传感器时间响应不同,对IMU和相机数据之间的时间差异进行标定,对于SLAM算法的状态估计一致性具有重要意义。相较于设计高精度的同步硬件[30],利用软件算法标定时间差异具有不需要额外硬件开销的优点。P.Furgale等[31]提出了一种时空联合标定算法,可实现对相机/IMU外参和传感器时间差异进行联合标定,相关算法已形成开源工具箱,被SLAM研究者和工程师广泛使用[32]。
借助标定板对IMU/相机时空参数进行离线标定的方法,难以应对安装基座形变等情况,并且一旦离线标定参数精度不高,则将影响到多传感器SLAM系统的融合效果。因此,研究利用自然特征的在线标定方法具有重要的应用价值。J.Kelly等[33]提出的标定算法既可以使用标定板,也可以使用未知的地标特征点进行IMU/相机外参标定。沈劭劼等[28]将外参和时间参数加入到惯性/视觉组合SLAM系统中,实现了对运动参数和标定参数的在线联合估计。
2.4 惯性/激光雷达标定
相较于视觉-IMU 标定方法,关于激光雷达-IMU 标定方法的研究相对较少[34]。目前,主要采用分步标定策略。首先在惯性/视觉/激光雷达系统中标定IMU/相机、激光雷达/相机之间的外参,然后再利用传递性获得IMU与激光雷达之间的相互安装关系[35]。
借助高精度导航设备可以为IMU/激光雷达标定提供参考信息,例如以GNSS/IMU组合导航系统输出的运动信息与激光雷达SLAM测量的运动信息进行配准,从而标定IMU与激光雷达的安装关系[36]。在进行雷达标定的过程中,一个不容忽视的因素就是雷达由于自身运动所引起的帧内畸变。虽然可利用GNSS/IMU组合导航系统输出对帧内运动进行插值拟合,得到连续的激光雷达SLAM输出;然而,利用GNSS/IMU组合导航系统对激光雷达SLAM进行插值的前提是需要已知标定关系。为了解决上述问题,可以采用反复迭代优化[34]的方法或者限制雷达采集时刻车体是静止的,这样就避免了帧内补偿。
目前,市场上一些新型号激光雷达已集成了IMU,如大疆的Livox雷达[37]等,这类雷达在出厂时就已经标定好了雷达与IMU 间的外参,可供开发人员直接使用。
多传感器标定技术虽然在数学原理上已经基本成熟,但是该技术目前仍然是机器人领域的研究热点,相关论文在每年的顶会顶刊上依然层出不穷。研究标定过程更方便、标定精度更高,甚至是无需人工参与的在线自标定方法始终是学界和工业界共同追求的目标。
3 基于惯性/视觉/激光雷达融合的SLAM技术
本节将介绍基于惯性/视觉/激光雷达融合的SLAM技术。IMU测量的是载体运动的惯性信息,而相机和激光雷达都是对地标的测量。如何将惯性信息与地标信息进行有效融合是组合SLAM系统需要解决的重要问题。本文将组合SLAM系统分为惯性/视觉、惯性/激光雷达和惯性/视觉/激光雷达三类系统。基于惯性/视觉组合的导航技术读者可以参考作者前续发表的综述文献[38],在本文中不再复述。
3.1 惯性/激光雷达组合SLAM
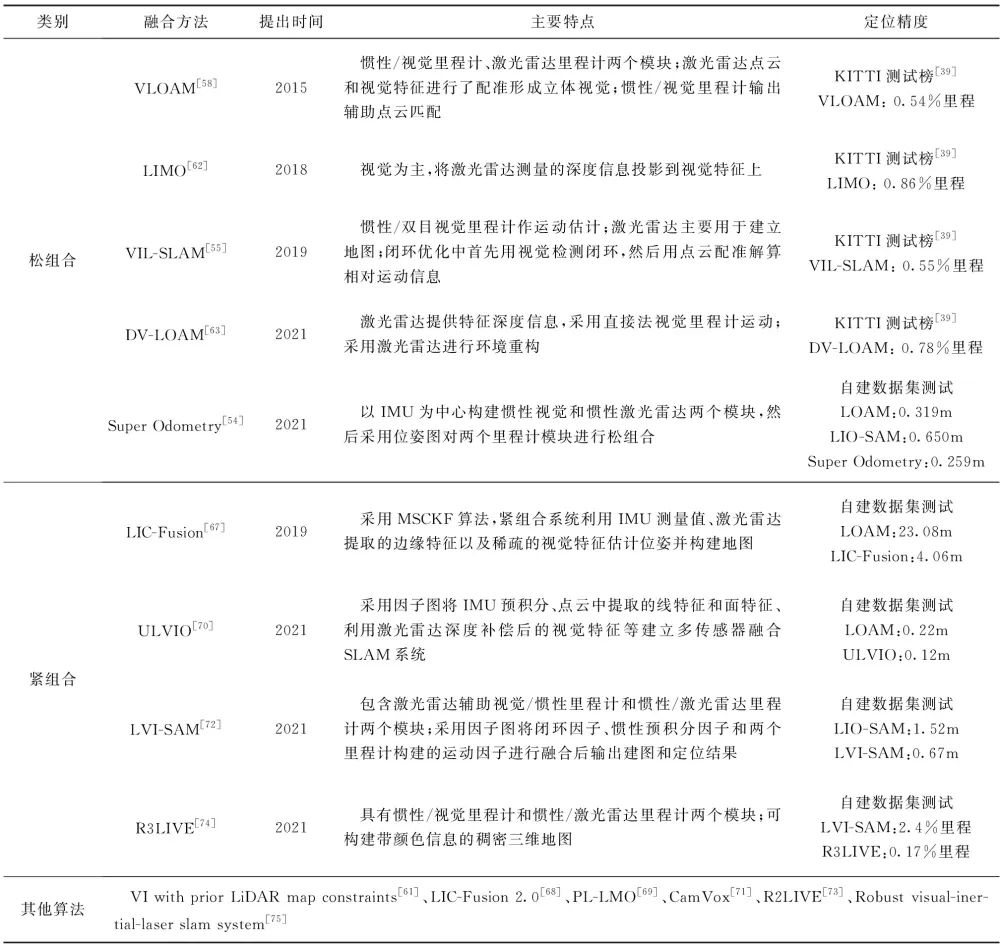
根据组合方式的不同,可将惯性/激光雷达组合SLAM分为松组合和紧组合两大类。在组合SLAM中,根据状态估计算法又可分为基于滤波的状态估计方法和基于非线性优化的参数优化方法,惯性/激光雷达组合SLAM部分文献总结如表1所示。由于各算法的测试条件和评估方法不同,难以对算法精度进行对比,因此表1中仅列出了各算法在特定测试条件下的定位精度指标作为参考。
表1 惯性/激光雷达组合SLAM
Tab.1 Lidar-inertial SLAM systems
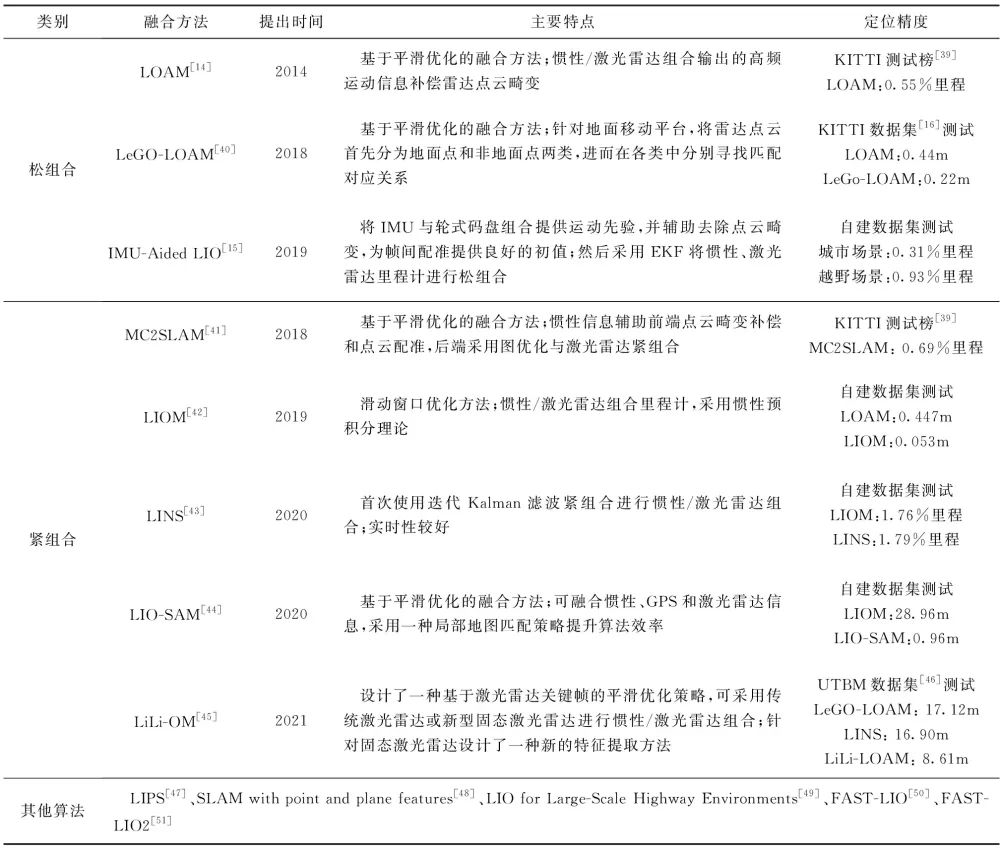
LOAM[14]是可实时化的激光雷达SLAM代表作之一,其在2014年被提出时即在KITTI数据集的精度测试榜上排名第一。相较于纯激光雷达的LOAM算法,采用卡尔曼滤波器将激光雷达与IMU进行松组合,并利用IMU输出的高频运动信息对雷达点云进行校正,可显著提升LOAM算法精度。LeGO-LOAM[40]则以LOAM为基础,针对地面应用对特征提取和状态估计进行了优化,不仅提升了算法精度,还可在Nvidia Jetson TX2 计算模块中实时运行。IMU-Aided LIO算法[15]则将IMU与轮式码盘组合获得高频运动信息,然后将该信息用于补偿激光雷达扫描过程中产生的点云畸变。
相较于松组合系统,惯性/激光雷达紧组合SLAM系统在后端算法中直接利用点云观测信息优化定位与建图结果;同时,在前端点云匹配中也会利用组合系统输出的高频运动信息进行补偿和初始化。MC2SLAM[41]利用惯性信息对运动轨迹进行预测,并构建帧间相对运动因子;在优化过程中则采用因子图对先验残差、雷达里程计残差和帧间相对运动残差进行联合优化,其测试结果在KITTI数据集上展示出比LOAM算法更高的精度。LIOM[42]将定位与建图设置为两个并行的节点,在定位模块中采用基于滑动窗口的因子图优化方法进行信息融合。为提升组合算法运行效率,LIOM还采用了惯性预积分理论[52]以避免对惯性的重复积分运算。LINS[43]采用迭代卡尔曼滤波器对惯性/激光雷达进行紧组合,虽然其精度与LIOM相当,但LINS的运行速度却明显快于LIOM。在同一计算设备中的测试表明,LIOM处理一帧雷达数据的时间大于100ms,而LINS却小于30ms。LIO-SAM[44]利用iSAM[53]平滑优化工具箱,将惯性、激光雷达和全球定位系统(Global Positioning System,GPS)进行融合,并且采用一种局部地图匹配策略替换LOAM和LIOM中的全局地图匹配策略,使得LIO-SAM具有更高的精度和更短的计算耗时。与多数惯性/激光雷达SLAM在前端算法中提取线、面等特征不同,FAST-LIO2[51]直接将激光雷达测得的点与地图进行匹配,并且采用K-D树来保障对地图的快速更新。针对新型的固态激光雷达,LiLi-OM[45]设计了一种从固态激光雷达中提取特征的方法,并设计了一种针对激光雷达的关键帧滑动窗口优化策略。在与LIOM、LINS和LIO-SAM等算法的对比中,LiLi-OM展现出更好的定位精度。
3.2 惯性/视觉/激光雷达组合SLAM技术
虽然相机和激光雷达都可以感知地标信息,但两种传感器测量的信息类型不同。一种简单的融合思路是分别以视觉和激光雷达为基础构建里程计,然后通过松组合的方式将两个模块的输出结果进一步融合[54-57]。SuperOdometry[54]则以IMU为中心构建了惯性/视觉里程计和惯性/激光雷达里程计分别对运动参数进行估计,然后利用位姿图优化方法将两个里程计输出进行融合(如图6所示)。构建两个里程计模块的松组合方法虽然降低了算法设计的复杂度,但未能发挥视觉和雷达在前端感知中的互补性。在VIL-SLAM[55]中,采用一个惯性/双目视觉里程计进行运动估计,并利用里程计输出的运动信息和激光雷达点云信息进行建图;在闭环优化中,首先采用视觉信息检测闭环,然后利用雷达点云配准解算相对运动信息,进而对运动轨迹和环境地图进行优化。在Zhang J.等提出的方法[58-59]中,包含视觉/惯性里程计和激光雷达里程计两个模块,在视觉里程计中激光雷达测量的深度信息和视觉特征进行了配准;而视觉里程计的输出也用于辅助激光雷达点云的帧间匹配。然而,同时运行视觉和激光雷达两个里程计算法模块需要更多的计算资源,算法效率不高。
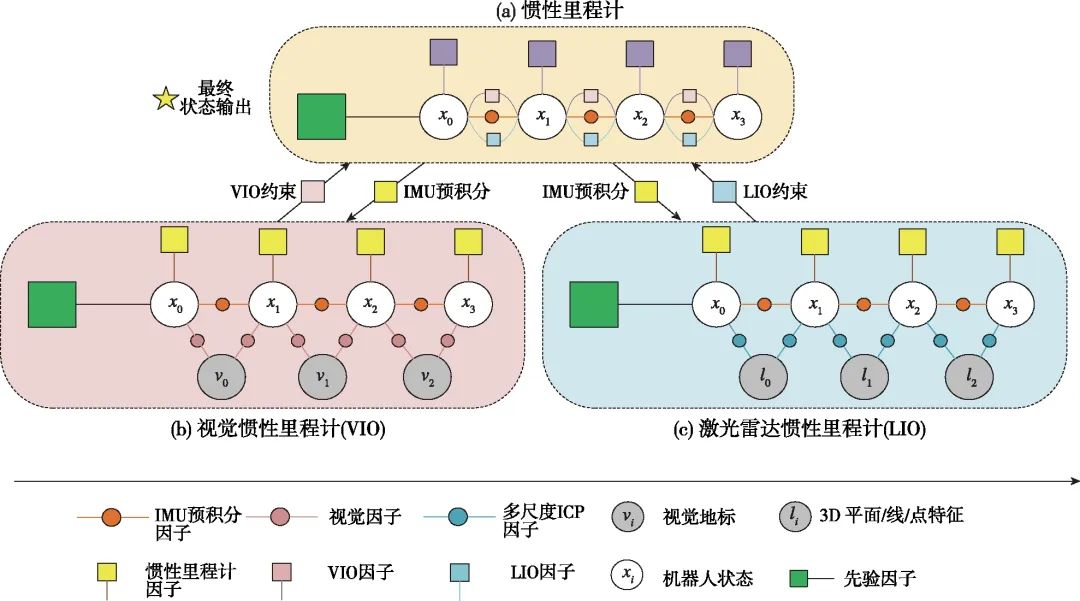
图6 将惯性/视觉与惯性/激光雷达两种里程计进行融合示意图[54]
Fig.6 Schematic diagram of fusing visual-inertial odometry and lidar-inertial odometry[54]
仅在SLAM前端算法中进行融合可以降低后端算法对计算资源的需求。Liang X.等[60]提出的方法就以激光雷达SLAM算法为主,仅在前端算法中采用视觉特征辅助闭环检测。Zuo X.等[61]则利用先验的激光雷达点云地图为惯性/双目视觉里程计提供位置约束信息。LIMO[62]则以视觉里程计为主,通过数据匹配将激光雷达测量的深度信息赋予视觉特征。将视觉图像和雷达点云进行配准后,图像信息中就包含了激光雷达测量的稀疏深度信息,基于融合后的感知数据构建SLAM可以发挥两种感知信息的优势[63-65]。
将多传感器进行紧组合可以更有效地利用测量信息提升系统的鲁棒性和精度,近年来基于紧组合的惯性/视觉/激光雷达系统也受到了研究者的关注。Yang Y.等[66]基于MSCKF将惯性信息、视觉点特征信息和激光雷达中提取的平面特征信息进行融合。同样基于MSCKF框架,LIC-Fusion算法[67]则从激光雷达中提取边缘特征和平面特征进行融合。在后续的LIC2.0算法[68]中,还可以对视觉/惯性和激光雷达/惯性的外参进行在线估计。PL-LOAM算法[69]则以视觉点、线特征为感知特征,构建单目视觉里程计;激光雷达则用于恢复视觉特征的深度信息,以及校正里程计尺度漂移。视觉信息和激光雷达测量的深度信息通过全局的集束优化(Bundle Adjustment)进行融合。D.Wisth等[70]基于因子图融合了惯性信息、视觉特征和激光雷达线特征信息,还使用了预积分、视觉特征深度信息配准和激光雷达数据纠偏等模块,如图7所示。Zhu Y.等[71]基于小型化的Livox固态激光雷达,设计了视觉/激光雷达融合SLAM算法,并实现了室外的高精度定位与建图。Shan T.等[72]提出的LVI-SAM中包括惯性视觉里程计和激光雷达里程计两个模块,并且在前端进行了感知信息的融合,其中激光雷达用于恢复视觉特征深度,而视觉/惯性里程计输出则用于辅助点云特征配准,最后采用因子图对惯性预积分信息和两个里程计模块输出进行了融合。Lin J.等[73]提出的R2LIVE算法则结合EKF和因子图进行多传感器融合,其中EKF将惯性信息、视觉角点特征和激光雷达平面特征点等观测信息进行紧组合,产生高频的运动估计输出;而因子图则以较低的频率对视觉地图进行校正。在后续改进的R3LIVE[74]算法中,融合SLAM系统的实时性进一步提升,并且在构图模块中结合视觉和激光雷达信息,可以实时构建稠密的、带有颜色的三维地图。
从算法实时性来说,目前提出的组合SLAM方法基本都能够达到实时性要求(算法耗时小于激光雷达的数据采集间隔)。一般来说,SLAM算法前端的计算量要小于后端的计算量。因此,目前常见的SLAM系统通常将前端和后端分两个线程实现。前端在负责特征点提取和数据关联的基础上,也会进行雷达帧间的匹配或图像特征点与局部子图的粗匹配,而后端则负责某一时间滑窗内的整体位姿优化和地图优化。前端虽然会产生一定的位姿漂移,但在后端优化线程中则会对漂移进行校正,这样既保证了位姿估计精度,也提升了算法的实时性。部分基于惯性/视觉/激光雷达融合的SLAM算法总结如表2所示。
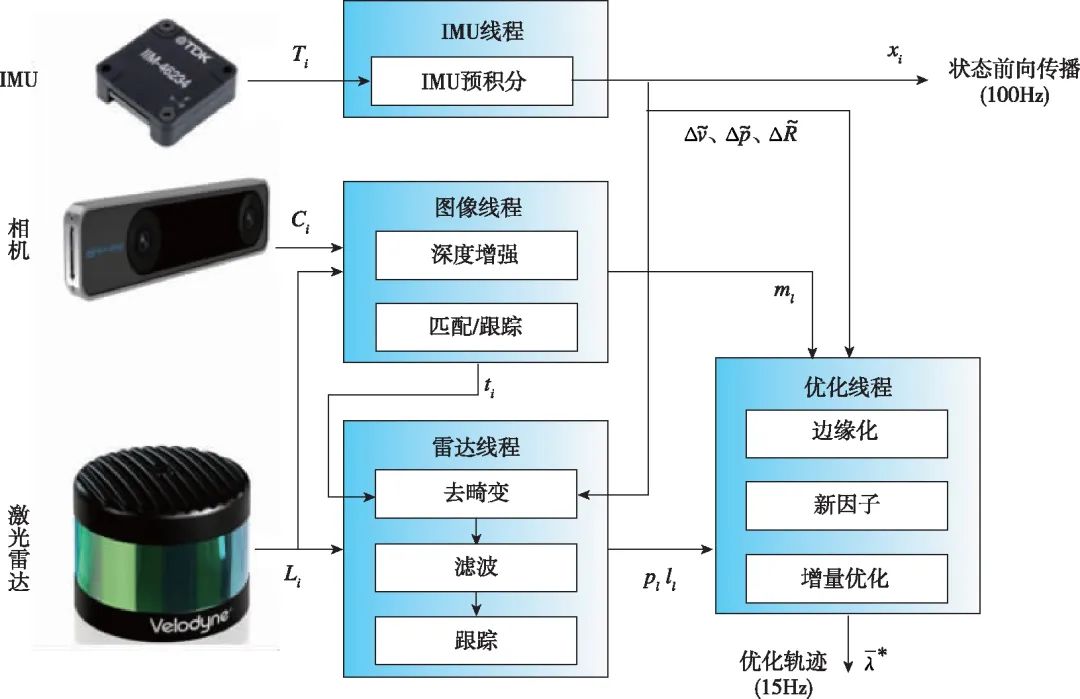
图7 惯性/视觉/激光雷达紧组合示意图[70]
Fig.7 Schematic diagram of a tightly integrated inertial-visual-lidar SLAM system[70]
表2 惯性/视觉/激光雷达组合SLAM
Tab.2 Inertial-visual-lidar SLAM systems
4 基于多传感器融合的SLAM技术发展趋势
基于多源传感器融合的SLAM技术在精度和鲁棒性上都已经表现出比单个传感器SLAM方法更优的性能,但仍有以下重点问题值得关注:
1)对单个导航源置信度的准确估计。多源信息融合的基础是能够对每个导航源的置信度进行准确估计。在复杂场景下,视觉或激光雷达则会因周围环境特征的缺失而变得不可信,如何在线对视觉和激光雷达测量信息的置信度进行准确估计是目前的一个研究热点[76-78]。
2)更加鲁棒的感知前端。SLAM的前端是实现定位与建图的基础。一方面可以通过融合更多互补的传感器,例如事件相机[79]、固态激光雷达及毫米波雷达等,提升前端感知能力;另一方面,可以利用更为鲁棒的特征信息构建SLAM系统,例如基于语义特征的SLAM方法[80-81]近年来就得到了广泛的关注。
3)适应性更强的后端优化方法。现有基于卡尔曼滤波或因子图的后端融合方法对测量信息的噪声特征等都有一定的限定条件。在复杂环境和复杂动态条件下,测量信息中包含未知模型噪声和大量野值点(outlier)时,优化方法如何适应环境和动态性变化,保持系统的有效性和精度是值得关注的问题。目前,基于学习和学习+模型[82]的信息融合与标定方法[83]有望解决这类难题。
4)基于SLAM的无人系统环境感知技术。对于无人系统来说,SLAM是一种技术手段而不是终极目的。如何利用好SLAM提供的帧间相对位姿,实现基于多帧序贯数据融合的环境感知,以及如何从SLAM系统构建出的环境高精度地图中挖掘出物体、语义、关系等高层特征以辅助对场景的实时理解,是无人平台环境感知系统亟需突破的关键核心技术。
编辑:黄飞

















 工商网监
工商网监
评论