 电子发烧友App
电子发烧友App


作者:Mehdi Amine
从硬件到实现计算机视觉的系统,本文的概述侧重于广度而非深度。为了平衡这种方法,本文引导读者阅读具有指导性的参考文献,并提供了随时可以运行的源代码。我们从图像形成的机制开始。我们涵盖针孔、透镜、传感器(CCD和CMOS)、Bayer滤波器和颜色重建。
然后,我们转到计算机视觉的应用上来,检测图像中的车道线。该方法是基于一套常用的计算机视觉算法。
成像历史简介
拍照就是把3D场景投影到2D平面上。暗箱通过一个针孔实现了这种投影。墙上的一个小针孔让光线穿透了黑暗的照相机室。这个简单的机制产生了尖锐的投影,使艺术家能够在场景的细节上画出草图。但是这种方法缺乏亮度,针孔本身不能收集足够的光。
柯歇(Athanasius Kircher) 1645年的著作《大路西与阴影》(Ars Magna Lucis Et Umbrae)中“便携式”暗箱的雕刻
针孔相机即使在今天也吸引了广泛的兴趣,它们能够捕捉到令人惊叹的图像,其特点是在任何地方都能使用。缺点还是一样,图像很暗,需要很长的曝光时间。
用针孔相机拍摄的邓卢斯城堡的日落,曝光时间20分钟,伊万·麦格雷戈
为了解决光线暗淡的问题,引入了透镜。通过在光圈前放置透镜,可以聚集更多的光。透镜还可以修改投影图像的放大倍率。在过去,放大需要艺术家移动整个相机。如今,在不改变场景和像面之间的距离的情况下,可以通过移动镜头的位置来调节放大效果。变焦是移动镜头来改变放大倍率的过程。
即使有了镜头,捕捉图像也需要很长时间依靠艺术家在投影图像上作画。19世纪30年代,路易斯·达盖尔(Louis Daguerre)发明了胶片,这是摄影史上最重要的发明之一。这是第一次有可能在物理层上记录光,不需要依靠艺术家,只需要按下一个按钮,就能记住一个时刻。
胶片上涂上卤化银。一旦暴露在光线下,卤化银就会转化为金属银。转换量取决于胶片上任何特定点的曝光量。为了产生图像,胶片随后要经过化学显影处理。
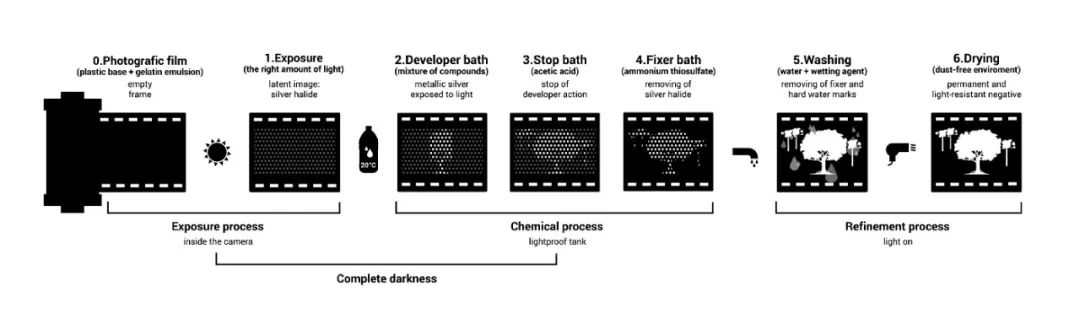
黑白底片处理
硅成像探测器的发明甚至比胶片的影响更大。同样的芯片可以用来捕捉无限多的图片,而不再需要化学照相显影。它是数码相机所使用的技术,也是我们大多数人今天随身携带的手机。
概括地说,拍照就是将3D场景投影到2D平面上。投影是通过光圈来实现的,通过透镜来收集更多的光线并调节放大倍率。2D平面最初是一个简单的平面,艺术家可以在上面作画。后来它变成了卤化银薄膜的表面。最后是硅芯片的表面:图像传感器。
为了将接收到的光转换成数字图像,大多数图像传感器依赖于硅原子的特性。当一个具有足够能量的光子撞击硅原子时,它会释放出电子。在硅晶格(一个像素)上,光子通量暴露产生电子通量。然后电子通量被转换成电压。
电荷耦合装置 CCD
在这种类型的图像传感器中,光子到电子的转换发生在每个像素中。在每个像素下都有一个电容储存释放的电子。一个叫做“垂直CCD移位寄存器”的电路连接每列像素的电容。这个电路可以使电子从一个像素垂直转移到它正下方的像素上,直到它们到达最后一行。最后一行由水平CCD移位寄存器连接,该寄存器将电子送到模数转换器中。
CCD中电子的垂直传递采用bucket-brigade法完成。这意味着每一行在获取其前面一行的电子之前,先将其电子传递给下一行。水平转移保持行顺序,当它们水平移动到ADC时,它们被转换为与它们的电子电荷成比例的电压。
互补金属氧化物半导体 CMOS
CMOS以不同的方式实现图像传感器。它不是将电子从像素转移到ADC,而是集成了像素级的电压转换。
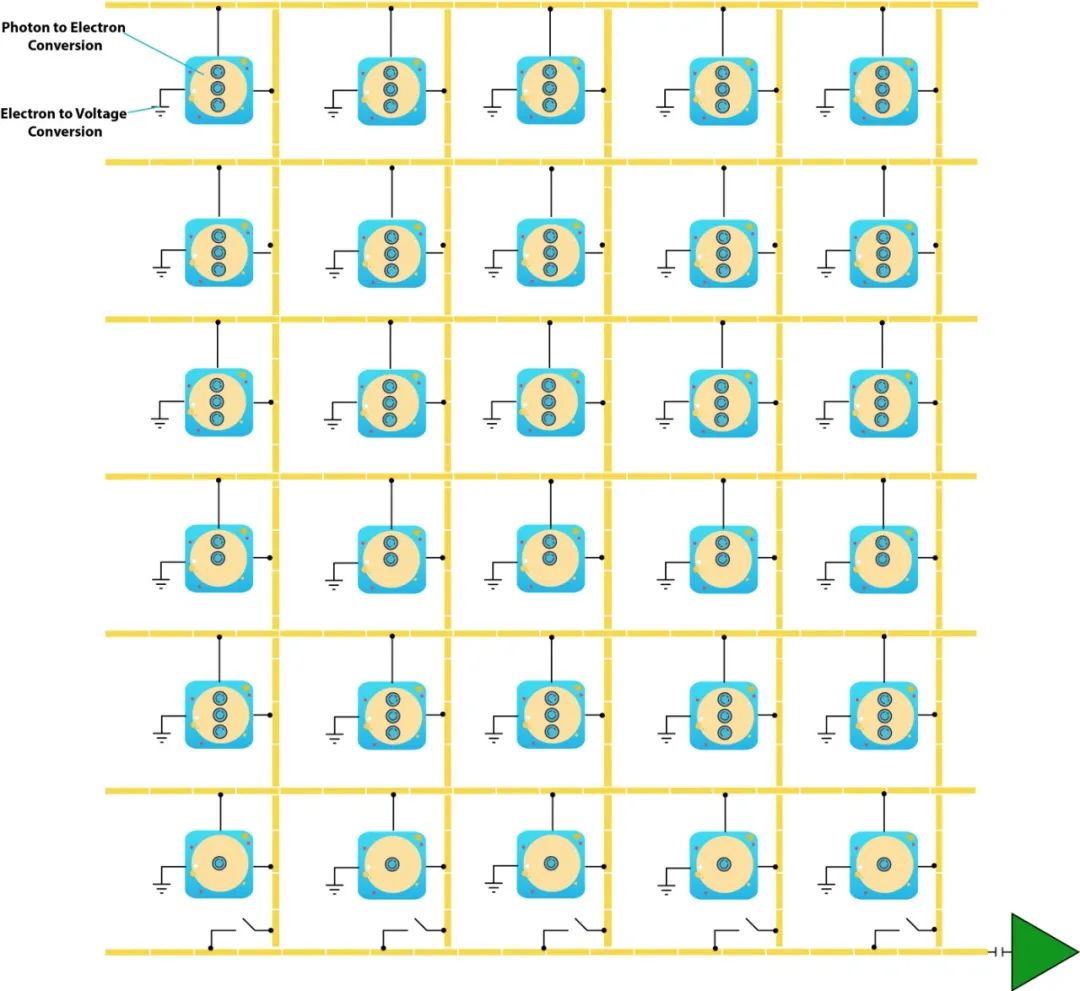
使用CMOS可以单独寻址每个像素以读取其电压。这提供了更多的灵活性,因为它可以加快特定兴趣区域的阅读速度。这种灵活性是以更小的光敏区域为代价的,因为在像素级集成了更多的组件。为了弥补感光区域的减少,微透镜被直接放置在每个像素的上方。这些微透镜将光线聚焦在光敏探测器上。
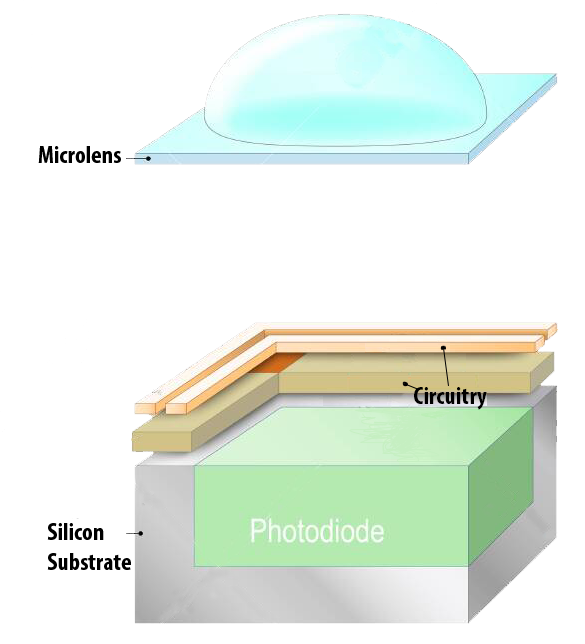
像素结构
获取颜色
像素本身能够捕捉光的强度,但不能捕捉光的波长。为了捕捉颜色(波长),最流行的方法是叠加一个拜耳滤光片阵列。在这种方法中,每个像素都被一个红色、绿色或蓝色的滤光片覆盖。
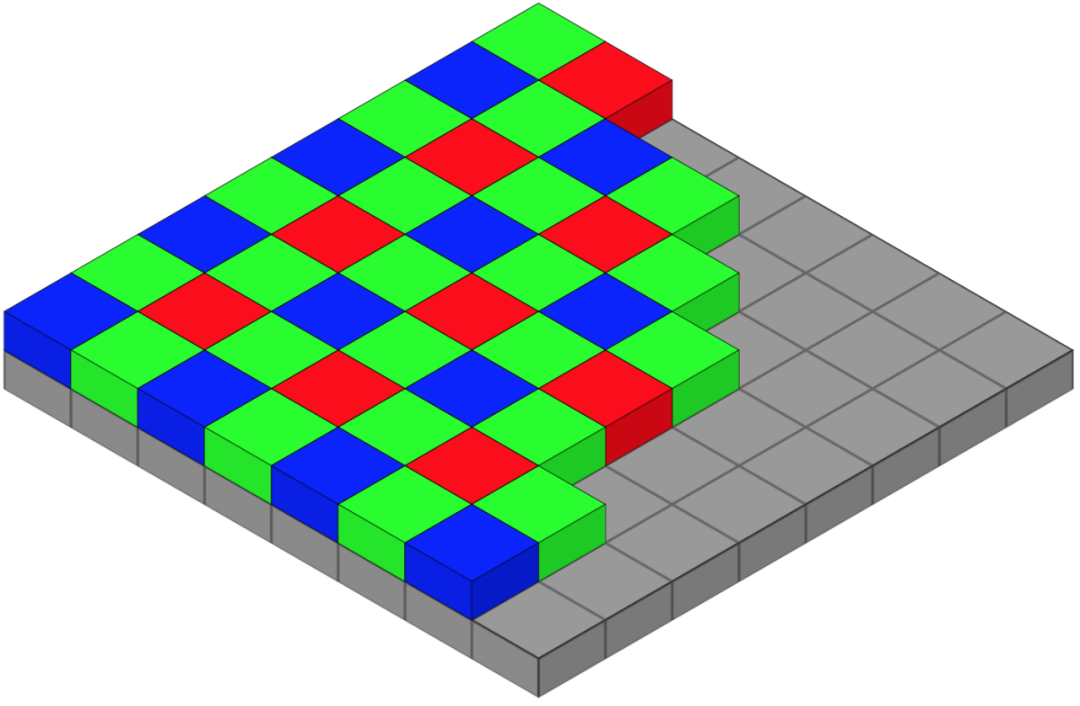
图像传感器的像素阵列上的彩色滤光片的拜耳排列。每个2乘2单元格包含两个绿色,一个蓝色和一个红色的滤光片。
人类对几乎所有颜色的感觉都可以通过3种波长产生。捕捉红色、绿色和蓝色的波长就足以重现拍摄到的场景的实际颜色。但就其本身而言,拜耳模式的叠加是不够的。它产生的图像看起来像左边的:

左边图像的像素要么是红色,要么是绿色,要么是蓝色。注意,图像看起来大部分是绿色的。拜耳模式模拟了人类视网膜在白天对绿光最敏感的事实。因此滤镜是一半绿色,四分之一红色,四分之一蓝色。
为了将左边的图像转换为右边的图像,我们取每个像素的值,并将其与相邻像素的值结合起来。这个过程被称为插值。假设我们从左边的图片中取一个蓝色的像素。插值是将蓝色值与相邻像素的红色和绿色值混合在一起。
计算机视觉
图像传感器的应用已经成为我们生活中的基本组成部分。它们塑造了我们表达自我和交流的方式,它们开辟了科学和艺术的跨学科领域。也许这些领域中最先进的是计算机视觉。
研究计算机视觉必须从欣赏使之成为可能的硬件开始。我们已经简要地了解了硬件的历史、进展和主要组件。让我们来看一个使用它的令人兴奋的实际应用。
自动驾驶中的车道线检测
从2021年5月开始,特斯拉开始交付不再安装雷达的Model 3和Model Y。这些车型依赖基于摄像头的自动驾驶系统,以相同的安全评级提供相同的功能。
特斯拉Vision的主动安全功能之一是车道偏离警告/避免。能够探测道路车道在驾驶中是至关重要的。我们将研究车道检测,并以两种不同的方式实现它。首先使用计算机视觉算法,其次使用空间卷积神经网络。

第一步是检测图像中最显著的边缘。与其相邻像素亮度对比较大的区域被标记为边缘。下面的代码将图像转换为灰度,用高斯滤波器进行模糊以减少噪声,并应用算法Canny边缘检测。
def canny(image): gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) blur = cv2.GaussianBlur(gray, (5, 5), 0) canny = cv2.Canny(blur, 10, 30) return cannyCanny Edge Detection

经过Canny边缘检测后得到的图像
这些图像充满了我们不需要的信息。我们想专注于前方的道路,所以我们将定义一个多边形区域,以裁剪每个图像。定义多边形的点对这两幅图像来说是不同的。为了找到它们,我们可以绘制图像并显示宽度和高度轴。
def region_of_interest(image): height = image.shape[0] width = image.shape[1] polygons = np.array([[(10,height), (width,height), (width,1100), (630, 670), (10, 1070)]]) mask = np.zeros_like(image) cv2.fillPoly(mask, polygons, 255) masked_image = cv2.bitwise_and(image, mask) return masked_image

用于裁剪图像的多边形掩码

感兴趣区域掩码的结果
观察产生的感兴趣区域,人眼可以很容易地感知线条。这些线实际上是一系列像素,它们只是计算机中的点。我们需要追踪两条最能描述点排列的主线。这是使用Hough变换算法完成的。
lines = cv2.HoughLinesP(cropped_image, 2, np.pi/180, 100, np.array([]), minLineLength=40, maxLineGap=5)

在原始图上加上蓝色线条的结果
这种方法似乎产生了很好的结果,但这种实现远非最佳,因为:
我们必须明确定义每个情况的兴趣区域。由于透视的变化,应用相同的多边形掩码来裁剪ROI是不可能的。
计算时间过慢,开车需要较高的处理速度。
转弯包括弯曲的车道,这种方法只包括直线。
审核编辑:黄飞














 工商网监
工商网监
评论