在最近举办的GSA存储大会上,芯片制造业的四大联盟组织-IMEC, ITRI, Sematech以及SEMI都展示了他们各自在基于TSV的3D芯片技术方面的最新进展
2011-04-14 18:38:31 7492
7492 
据IC Insights发布的最新2020 McClean报告显示,半导体行业研发的投入将在2024年出现明显成效包括转向EUV光刻,低于3纳米制程技术,3D芯片堆叠技术和先进封装在内的技术挑战有望
2020-01-31 09:20:347042 3D堆叠、多芯片封装大家想必都不陌生了,这年头制造工艺已经没有太多噱头,有时甚至性能提升也有限,厂商只好从架构上入手。像苹果的Ultra Fusion拼接、Graphcore的3D WoW,都是在
2022-04-13 01:06:007527 多芯片封装在现代半导体领域至关重要,主要分为平面多芯片封装和多芯片堆叠封装。多芯片堆叠封装又细分为多芯片3D堆叠引线键合封装、3D堆叠引线键合和倒装异质封装、3DTSV堆叠倒装封装等。
2025-05-14 10:39:541847 
7月24日国外消息:SanDisk在3D NAND方面正在走自己的技术路线-- 在同一个区域记录层的堆叠在一个闪存芯片放到另一个提供更多的容量之内。
2013-07-25 10:24:231558 半导体协会理事长卢超群指出,未来半导体将要做3D垂直堆叠,全球半导体产业未来会朝向类摩尔定律成长。
2016-06-10 00:14:002696 据外媒报道,东芝今天宣布正式出货BiCS FLASH 3D闪存,采用64层堆叠,单晶粒容量512Gb(64GB,TLC),相对于上一代48层256Gb,容量密度提升了65%,这样封装闪存芯片的最高容量将达到960GB。
2017-02-23 08:33:401752 通过3D堆叠技术将存储层层堆叠起来,促成了NAND 技术进一步成熟。
2018-04-16 08:59:5213248 
台积电(中国)有限公司技术总监陈敏表示,TSMC 3D Fabric先进封装技术涵盖 2.5D 和垂直芯片堆叠产,是台积电过去10年以来对于3D IC的不断完善和开发。客户采用台积3D Fabric所生产的产品取得的整个系统效能的提升,都有非常良好的表现。
2022-09-20 10:35:472930 
先进封装从MCM发展到2.5D/3D堆叠封装,目前发展最快的制造商是TSMC。TSMC从Foundry端延伸入2.5D/3D先进封装,称为3D Fabric。近十年来TSMC的2.5D先进封装技术
2022-10-26 10:21:375940 3D堆叠像素探测器芯片技术详解
2024-11-01 11:08:074435 
3D堆叠将不断发展,以实现更复杂和集成的设备——从平面到立方体
2024-09-19 18:27:412348 
近日,3D AI芯片系统公司埃瓦科技宣布已完成亿元级A轮融资,由中科创星领投,拓金资本、瀚漾投资跟投,老股东鼎青投资继续追投。本轮融资将主要用于加速基于埃瓦自研3D AI视觉芯片追萤系列视觉模组研发
2021-07-17 07:45:004893 求大神赐个全面的3D PCB封装库(PCB封装附带3D模型)!!!~
2015-08-06 19:08:43
这段时间以来,最热的话题莫过于iPhone X的Face ID,关于用它刷脸的段子更是满天飞。其实iPhone X 实现3D视觉刷脸是采用了深度机器视觉技术(亦称3D机器视觉)。由于iPhone X的推动,3D视觉市场或许将被彻底的激活。
2019-07-25 07:05:48
什么是3D图形芯片?3D图像生成算法的原理是什么?
2021-06-04 06:29:06
3D打印将精准的数字技术、工厂的可重复性和工匠的设计自由结合在一起,解放了人类创造东西的能力。本文是对当下3D打印技术带来便利的总结,节选自中信出版社《3D打印:从想象到现实》一书。虎嗅会继续摘编该书精华。
2019-07-09 07:02:03
`LABVIEW的3D控件是如何创建的,请各位大侠帮忙一下`
2013-06-25 15:35:01
3D显示技术的原理是什么?3D显示技术有哪些应用?3D拍好了到底怎么样传输?
2021-05-31 06:53:03
3D模型基础
2021-01-28 07:50:30
环节。下面,小编将通过绘制生活中常见的风扇叶模型,展示如何通过浩辰3D设计软件高效地完成日常的创新设计需求。1、叶毂绘制在浩辰3D设计软件的草图选项卡中,点选「草图绘制」,绘制出叶毂的外形轮廓草图,并
2021-06-04 14:11:29
`在日常设计过程中,设计工程师总会遇到需要在各种塑料、铸造或锻造零件的模型上,标注企业标准化标签或零件号的情况。浩辰3D软件除了能够快速且高效地完成3D模型的设计与装配,还能在各种3D模型上实现文本
2021-04-22 17:28:02
我公司专业从事3D全息风扇研发生产,主要生产供应3D全息风扇PCBA,也可出售整机,其他配件可免费提供供应商信息或者代购,欢迎咨询 刘先生:*** 微信同号3d全息风扇灯条3d全息风扇PCBA3D全息风扇方案本广告长期有效
2019-08-02 09:50:26
,并将带宽密度提高10倍。在CES 2019展会上,Intel也正式公布了Foveros 3D立体封装技术,Foveros 3D可以把逻辑芯片模块一层一层地堆叠起来,而且可以做到2D变3D后,性能
2020-03-19 14:04:57
`AD16的3D封装库问题以前采用封装库向导生成的3D元件库,都有芯片管脚的,如下图:可是现在什么设置都没有改变,怎么生成的3D库就没有管脚了呢?请问是什么原因?需要怎么处理,才能和原来一样?谢谢!没管脚的就是下面的样子:`
2019-09-26 21:28:33
完成后,2D图如下: 2D图 我们按下键盘上的数字3,即可查看绘制的3D模型了,如图(4)。 图(4)0805电阻3D图像 0805的3D绘制起来比较简单,使用AD绘制的3D模型也不是
2021-01-14 16:48:53
Altium designer summer 09 怎么建立3D库,及PCB怎么导出3D图,请教各位前辈们
2016-11-23 19:48:22
DAD1000驱动芯片有3D功能吗
2025-02-21 13:59:21
` 3D视觉数据与我们的生活已经密不可分,在无人机测绘、实时摄影测量、AR/VR等领域有许多应用。视频的实时处理需要大量的计算,而无人机等移动应用需要低功耗便携式设备。PYNQ平台提供了正确的工具
2021-01-07 17:25:42
利用低温制造存储电路完成。在同一个3D芯片的不同层放上逻辑和存储电路,BeSang的工艺中每个晶圆包含了更多的裸片,这使得单位裸片的成本也降低了。 BeSang CEO Sang-YunLee说
2008-08-18 16:37:37
第一幅图是加了.step文件后的样子。第二幅图是加载这个自建库后的pcb预览。在没加3D元件时。自定义库是可以用,可预览的。加了3D元件后,工程文件使用了后预览并没有显示出3D的形式。这是怎么回事
2019-09-04 04:36:03
当3D电影已成为影院观影的首选,当3D打印已普及到双耳无线蓝牙耳机,一种叫“3D微波”的技术也悄然而生。初次听到“3D微波”,你可能会一脸茫然,这个3D微波是应用在哪个场景?是不是用这种技术的微波炉1秒钟就能把饭煮熟?O M G!我觉得很有必要给大家科普一下!
2019-07-02 06:30:41
如何使用新款TI DLP Pico芯片组实现高精度台式3D打印和便携式3D扫描?
2021-06-02 06:34:48
怎么创建3D模型
2019-09-17 05:35:50
AD 在3D显示下,怎么去除3D封装的显示,我只看焊盘,有时候封装会遮掩底部的焊盘
2019-09-23 00:42:42
`如何把3D文件(STEP)添加到3D库?复制到3D库不能用.`
2013-08-21 12:42:02
、空隙填充若3D模型存在空隙,浩辰3D能自动识别3D模型上的空隙,并以红X的形式标出,点击确认后,即可直接填满这个空隙,完成填补,从而便于打印设备的工作机制。3、定位零件步骤一:首先,定义打印机设置,在
2021-05-27 19:05:15
即可。选择的模型都将在预览区进行显示,如下图所示。步骤二:开始比较选择完成后,点击左下方的「浏览」按钮进行比较。在此期间,不可进行设计编辑,如需同时完成其它设计工作,可以添加一个新的浩辰3D进程。步骤三
2020-12-15 13:45:18
`华尔街日报发布文章称,科技产品下一个重大突破将在芯片堆叠领域出现。Apple Watch采用了先进的的3D芯片堆叠封装技术作为几乎所有日常电子产品最基础的一个组件,微芯片正出现一种很有意思的现象
2017-11-23 08:51:12
在3D模式下能不能隐藏元件的3D,就是3D模式下只能看见PCB板
2019-04-18 05:51:13
2010年3D大热,蓝光3D产品成焦点
3D电影阿凡达(Avatar)靠着栩栩如生的3D特效成功掳获全球影迷,挟着电影热卖气势, 3D影像显示技术顺势跃居3D技术的主流发展方向,国际
2010-01-22 09:03:481056 单片型3D技术实现的关键在于如何将各层功能单元转换到单片3D堆叠结构之中去,其采用的方法非常类似于Soitec在制作SOI晶圆时所采用的SMARTCUT技术
2011-05-04 11:27:212198 
据台湾对外贸易发展协会(TAITRA)透露,芯片代工巨头台积电(TSMC)有望超过intel,在2011年底推出业内首款采用3-D芯片堆叠技术的半导体芯片产品。
2011-07-07 09:19:071168 台积电将尝试在未来独力为客户提供整合3D晶片堆叠技术。这种做法对台积而言相当合理,但部份无晶圆晶片设计厂商表示,这种方法缺乏技术优势,而且会限制他们的选择。
2011-12-16 08:57:591004 主动快门式3D技术和偏光式3D技术应为看3D显示设备还需要佩戴3D眼镜,这让不少用户感觉到麻烦。裸眼3D让用户不用带3D眼镜即可看到3D画面。
2012-02-28 09:45:177387 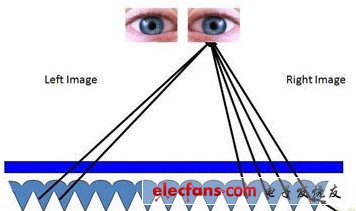
2012年4月27日讯 - GLOBALFOUNDRIES今天宣布,在为新一代移动和消费电子应用实现3D芯片堆叠的道路上,公司达到了一个重要的里程碑。在其位于美国纽约萨拉托加郡的Fab 8,GLOBALFOUNDRIES已开始
2012-04-28 09:15:031772 3D电视和我们很熟悉的3D电影有什么差别呢,它的未来会怎样,大范围普及还有多远?
2012-07-17 16:17:284191 通过裸眼3D技术,你就能看到本来要借助特殊眼镜才能观看到的3D立体影像。很好奇吧,就让《最新裸眼3D技术揭秘》技术专题带你一起揭秘裸眼3D,一起了解裸眼3D技术、裸眼3D产品(含裸眼3D手机、裸眼3D显示器、裸眼3D电视...)、裸眼3D技术特点、裸眼3D技术应用等知识吧!
2012-08-17 12:21:52

9月25日——全球电子设计创新领先企业Cadence设计系统公司(NASDAQ:CDNS)今天宣布,台积电与Cadence合作开发出了3D-IC参考流程,该流程带有创新的真正3D堆叠。该流程通过
2013-09-26 09:49:201717 3D模型, 淘宝网上买的3D元器件库需要的自行下载
2015-11-04 15:36:04 0
0 3D元件封装库3D元件封装库3D元件封装库3D元件封装库
2016-03-21 17:16:570 芯片晶粒在未来搭载愈来愈多晶体管可望成为趋势,让芯片运算能力达到人脑水平也可望有朝一日达成,对于这类新技术的发展,在芯片上以及在多层堆叠芯片之间打造先进3D结构成为一大主要驱动力,在2017年
2017-12-20 08:45:505710 3D投影机主要采用TI的DLP Link技术,其原理是通过DMD芯片输出120Hz刷新率的画面,左右眼交替使用,使人眼形成3D的“错觉”。其优点是简便易行,对硬件的要求比较低,但是在3D游戏的配合方面,NVIDIA的 3D Vision技术和3D套件支持的游戏会更广泛一些。
2018-01-10 16:48:4010328 在Dell EMC World 2017大会上,东芝美国电子元件公司TAEC展示了采用64层BiCS 3D堆叠技术的SSD产品,归属于XG3系列,也就是OCZ RD400的OEM版。
2018-07-30 16:25:352131 紫光集团旗下长江存储发展储存型快闪存储器(NAND Flash)报捷,已自主开发完成最先进的64层3D NAND芯片专利,预计明年完成生产线建置、2020年量产,震撼业界。
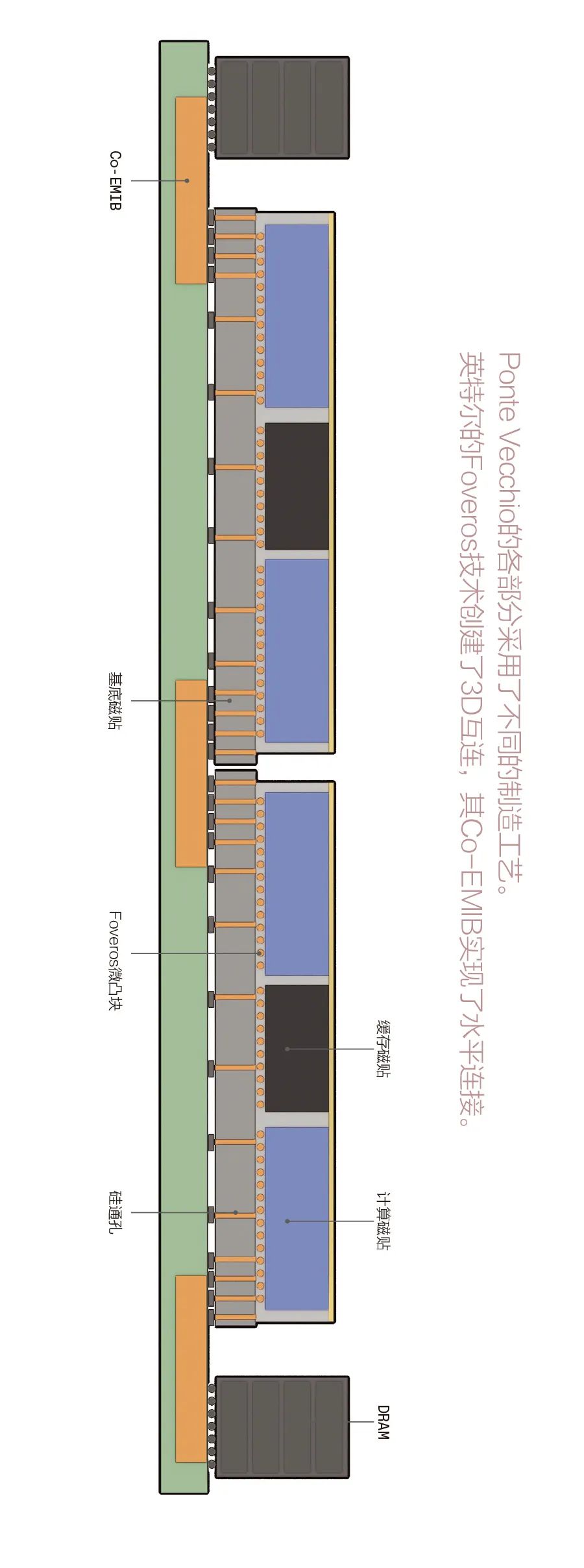
2018-08-13 09:45:002770 在近日举行的英特尔“架构日”活动中,英特尔不仅展示了基于10纳米的PC、数据中心和网络系统,支持人工智能和加密加速功能的下一代“Sunny Cove”架构,还推出了业界首创的3D逻辑芯片封装技术——Foveros。这一全新的3D封装技术首次引入了3D堆叠的优势,可实现在逻辑芯片上堆叠逻辑芯片。
2018-12-14 16:03:409951 在近日举行的英特尔“架构日”活动中,英特尔不仅展示了基于10纳米的PC、数据中心和网络系统,支持人工智能和加密加速功能的下一代“Sunny Cove”架构,还推出了业界首创的3D逻辑芯片封装技术——Foveros。这一全新的3D封装技术首次引入了3D堆叠的优势,可实现在逻辑芯片上堆叠逻辑芯片。
2018-12-14 15:35:328854 英特尔近日向业界推出了首款3D逻辑芯片封装技术“Foveros”,据悉这是在原来的3D封装技术第一次利用3D堆叠的优点在逻辑芯片上进行逻辑芯片堆叠。也是继多芯片互连桥接2D封装技术之后的又一个颠覆技术。
2018-12-14 16:16:453316 温度与打印时速度,都是影响3D打印的重要参数。3D打印的原理是透过加热原料将其高温软化,再透过喷嘴挤压,以逐层堆叠的方式「印」出立体的物品。
2018-12-22 15:55:311964 近日,武汉新芯研发成功的三片晶圆堆叠技术备受关注。有人说,该技术在国际上都处于先进水平,还有人说能够“延续”摩尔定律。既然3D芯片堆叠技术有如此大的作用,那今天芯师爷就跟大家一起揭开它的面纱。
2018-12-31 09:14:0034067 对于目前的高端市场,市场上最流行的2.5D和3D集成技术为3D堆叠存储TSV,以及异构堆叠TSV中介层。Chip-on-Wafer-on-Substrate(CoWos)技术已经广泛用于高性能计算
2019-02-15 10:42:198043 
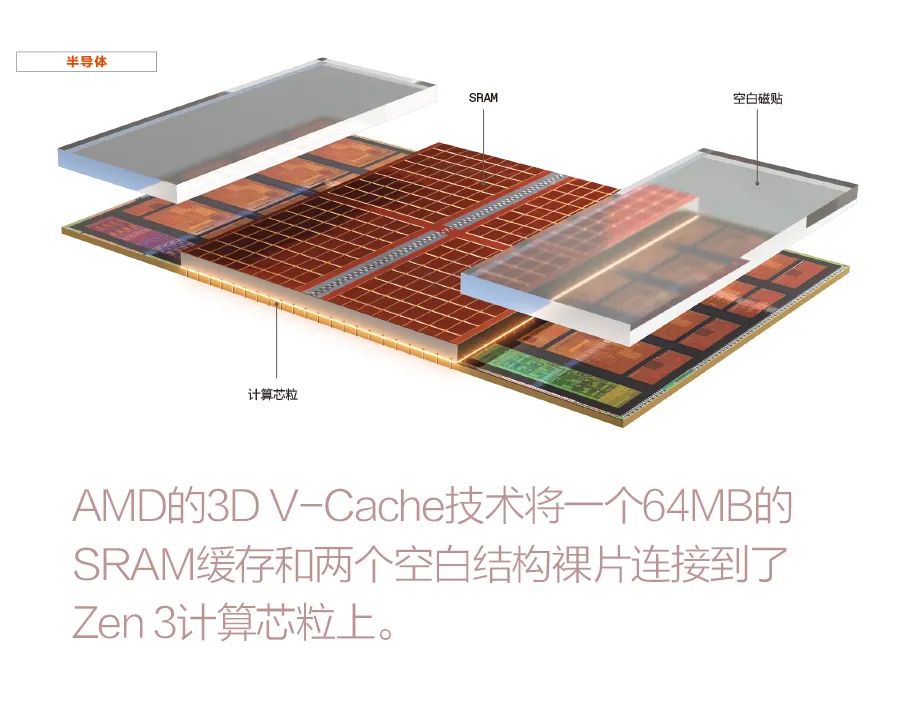
对于3D封装技术,英特尔去年宣布了其对3D芯片堆叠的研究,AMD也谈到了在其芯片上叠加3D DRAM和SRAM的方案。
2019-08-13 10:27:533414 根据台积电在第二十四届年度技术研讨会中的说明,SoIC是一种创新的多芯片堆叠技术,是一种晶圆对晶圆(Wafer-on-wafer)的键合(Bonding)技术,这是一种3D IC制程技术,可以让台积电具备直接为客户生产3D IC的能力。
2019-08-14 11:21:064993 
类比积体电路设计也将进入三维晶片(3D IC)时代。在数位晶片开发商成功量产3D IC方案后,类比晶片公司也积极建置类比3D IC生产线,期透过矽穿孔(TSV)与立体堆叠技术,在单一封装内整合采用不同制程生产的异质类比元件,以提升包括电源晶片、感测器与无线射频(RF)等各种类比方案效能。
2019-10-14 14:18:131071 困于10nm的Intel也在这方面寻找新的机会,其在去年年底的“架构日”活动中,推出其业界首创的3D逻辑芯片封装技术——Foveros,Foveros首次引入3D堆叠的优势,可实现在逻辑芯片上堆叠
2020-01-28 16:10:004118 本题目是简单讲解3D打印件中人体植入物和航空航天的打印完成后续的处理。
2020-01-01 16:06:004237 SIP有多种定义和解释,其中一说是多芯片堆叠的3D封装内系统集成,在芯片的正方向堆叠2片以上互连的裸芯片的封装。SIP是强调封装内包含了某种系统的功能封装,3D封装仅强调在芯片方向上的多芯片堆叠
2020-05-28 14:51:447076 科研人员将这台我国自主研制的“复合材料空间3D打印系统”安装在试验船返回舱中。飞行期间,该系统自主完成了连续纤维增强复合材料的样件打印,并验证了微重力环境下复合材料3D打印的科学实验目标。
2020-06-10 15:44:392836 目前现有的芯片都是 2D 平面堆叠的,随着芯片数量的增多,占用的面积越来越大,不利于提高集成度。关于 3D 芯片封装,就是将芯片从平面堆叠变成了垂直堆叠,类似搭积木那样一层层叠加,减少了芯片面积,提高了集成度。
2020-08-26 14:07:181795 计算机视觉爆炸式发展的背后是3D成像领域的巨大发展。今天的3D成像是什么状态,我们的发展方向是什么?
2020-10-09 14:25:389820 在Intel、台积电各自推出自家的3D芯片封装技术之后,三星也宣布新一代3D芯片技术——X-Cube,基于TSV硅穿孔技术,可以将不同芯片搭积木一样堆叠起来,目前已经可以用于7nm及5nm工艺。
2020-10-10 15:22:582004 发展至今,NAND Flash已呈现白热化阶段。就在前不久,存储厂商们还在128层“闪存高台上观景”,2019年6月SK海力士发布128层TLC 3D NAND;美光于2019年10月流片出样128
2020-12-09 14:55:374583 电子发烧友网为你提供3D堆叠技术的诱因资料下载的电子资料下载,更有其他相关的电路图、源代码、课件教程、中文资料、英文资料、参考设计、用户指南、解决方案等资料,希望可以帮助到广大的电子工程师们。
2021-03-31 08:50:5812 stm32开发3D打印机(零)——打印板配置(未完成)
2021-12-07 14:06:1224 在一起。每完成一层,喷头上移继续下一层的打印,反复堆叠直至完成整个模型。 FDM是当前全世界应用最为广泛的3D打印技术,目前桌面式3D打印机多采用此技术,n那FDM3D打印技术 FDM 3D技术之所以能受到广大3D打印爱好者的青睐自然有它的优点。首先是成型原理简单,机器价格相对便宜
2022-04-29 09:51:3311719 2.5D/3D 芯片包含 Interposer/ 硅穿孔 (Through Silicon Via, TSV) 等复杂结构,通过多物理场
仿真可以提前对 2.5D/3D 芯片的设计进行信号完整性
2022-05-06 15:20:4219 堆叠技术也可以叫做3D堆叠技术,是利用堆叠技术或通过互连和其他微加工技术在芯片或结构的Z轴方向上形成三维集成,信号连接以及晶圆级,芯片级和硅盖封装具有不同的功能,针对包装和可靠性技术的三维堆叠处理技术。
2022-05-10 15:58:134946 
一批高性能处理器表明,延续摩尔定律的新方向是向上发展。每一代处理器都要比上一代性能更好,究其根本,这意味着要在硅片上集成更多的逻辑。
2022-08-31 10:46:057366 目前有多种基于 3D 堆叠方法, 主要包括: 芯片与芯片的堆叠( D2D) 、芯片与圆片的堆叠( D2W ) 以及圆片与圆片的堆叠( W2W) 。
2022-11-01 09:52:512488 当裸片尺寸无法继续扩大时,开发者开始考虑投入对 3D 堆叠裸片方法的研究。考虑用于 3D 封装的高端器件已经将当前的可测试性设计 (DFT) 解决方案推向了极限。
2023-02-28 11:39:262362 然已经有很多关于 3D 设计的讨论,但对于 3D 的含义有多种解释。然而,这不仅仅是语义,因为每个封装选项都需要不同的设计方法和技术。
2023-03-27 13:01:381147 我们之前见过的闪存多属于Planar NAND平面闪存,也叫有2D NAND或者直接不提2D的,而3D 闪存,顾名思义,就是它是立体堆叠的,Intel之前用盖楼为例介绍了3D NAND,普通NAND是平房,那么3D NAND就是高楼大厦,建筑面积一下子就多起来了,理论上可以无线堆叠。
2023-03-30 14:02:394222 3D NAND闪存是一种把内存颗粒堆叠在一起解决2D或平面NAND闪存限制的技术。这种技术垂直堆叠了多层数据存储单元,具备卓越的精度,可支持在更小的空间内,容纳更高的存储容量,从而有效节约成本、降低能耗,以及大幅度地提升性能。
2023-06-15 09:37:563209 
有许多外行人认为3D打印就是从热喷嘴中挤出材料并堆叠成形状,但其实3D打印远不止于此!今天南极熊将介绍七大类3D打印工艺,即使是3D打印小白也能清晰地区分不同的3D打印工艺。 事实上,3D 打印也
2023-06-29 15:36:274381 3D打印是一种数字制造技术,也被称为增材制造(Additive Manufacturing),它可以将数字三维模型逐层地转化为实体物体。与传统的减材制造方式(如切削加工)不同,3D打印是一种将物体逐层堆叠构建的技术。
2023-08-28 16:11:062529 随着摩尔定律接近物理界限,在3纳米以下的先进工艺中,能够负担较高费用的顾客受到限制,晶片sip和逻辑芯片的3D堆叠概念正在成为重要的新一代趋势。
2023-09-11 11:09:582010 Cadence员工MohamedNaeim博士曾在CadenceLIVE欧洲用户大会上做过一场题为《2D/3D热分析和三裸片堆叠设计实现》的演讲,本文将详细讲述该演讲内容。实验:两个裸片是否优于一个
2023-09-16 08:28:052057 
1.3D芯片栈的动机、口味和示例
2.经典挑战-加重但可解决
3.新的设计挑战和新出现的解决方案
2023-10-24 09:59:211331 
当芯片变身 3D 系统,3D 异构集成面临哪些挑战
2023-11-24 17:51:071969 
在3D实现方面,存储器比逻辑更早进入实用阶段。NAND闪存率先迈向3D 。随着目前量产的20-15nm工艺,所有公司都放弃了小型化,转而转向存储单元的三维堆叠,以提高每芯片面积的位密度。它被称为“ 3D(三维)NAND ” 。
2023-12-02 16:38:402967 
三星将在IEEE国际固态电路研讨会上展示其GDDR7产品以及280层堆叠的3D QLC NAND技术。
2024-02-01 10:35:311299 在全球半导体技术的激烈竞争中,SK海力士再次展示了其卓越的研发实力与创新能力。近日,在美国夏威夷举行的VLSI 2024峰会上,SK海力士宣布了其在3D DRAM技术领域的最新研究成果,其中5层堆叠的3D DRAM良品率已高达56.1%,这一突破性的进展引起了业界的广泛关注。
2024-06-27 10:50:221473 在半导体行业的快速发展历程中,芯片封装技术始终扮演着至关重要的角色。随着集成电路设计复杂度的不断提升和终端应用对性能、功耗、尺寸等多方面要求的日益严苛,传统的2D封装技术已经难以满足市场的需求。在此背景下,芯片3D堆叠封装技术应运而生,成为半导体技术发展的新里程碑。
2025-02-11 10:53:452819 
随着现代科技的迅猛发展,芯片设计面临着前所未有的挑战。特别是在集成电路(IC)领域,随着设计复杂性的增加,传统的光罩尺寸已经成为制约芯片性能和功能扩展的瓶颈。为了解决这一问题,3D堆叠技术应运而生
2025-03-07 11:11:53984 
在摩尔定律逼近物理极限的当下,先进封装技术正成为半导体行业突破性能瓶颈的关键路径。以系统级封装(SiP)、晶圆级封装(WLP)、3D堆叠、Chiplet异构集成为代表的颠覆性方案,正重新定义芯片性能
2025-04-10 14:36:311189 
、3D及5.5D的先进封装技术组合与强大的SoC设计能力,Socionext将提供高性能、高品质的解决方案,助力客户实现创新并推动其业务增长。
2025-09-24 11:09:542350 
在半导体技术迈向“后摩尔时代”的进程中,3D集成电路(3D IC)凭借垂直堆叠架构突破平面缩放限制,成为提升性能与功能密度的核心路径。
2025-12-26 15:22:38195 
 电子发烧友App
电子发烧友App













 工商网监
工商网监
评论