 电子发烧友App
电子发烧友App


随着人工智能(AI)技术的迅猛发展,我们正站在第四次工业革命的风暴中, 这场风暴也将席卷我们整个芯片行业,特别是先进封装领域。Chiplet是实现单个芯片算力提升的重要技术,也是AI网络片内互联的基础。而Chiplet先进封装技术让AI训练/推理芯片的量产成为可能,所以AI网络的物理层底座即芯片先进封装技术。“
AI技术的发展极大地推动了对先进封装技术的需求,在高密度,高速度,高带宽这“三高”方面提出了严苛的要求。
高密度: AI芯片通常包含大量的计算核心,这需要封装技术能够在有限的空间内提供高密度的互联方案,以实现核心间的高效通信。同时,又要保证封装的散热、结构、可靠性和可制造性等诸多方面的苛刻挑战。
高速度:AI处理单元(如GPU、TPU等)之间需要高速的数据交换,这要求封装技术能够支持高速信号传输,并且减少信号通路的衰减和串扰。
高带宽:AI处理单元之间在高速传输的同时,如何保证在有效的面积内有更高的传输带宽,这就需要从封装层面、从接口层面一同来考虑的问题,在有效的面积内增加互联数量,提高带宽。
结合“三高”提出的要求, 封装行业也八仙过海,各尽所能,纷纷开发出不同的Chiplet结构及工艺路线。总体上, 我们从空间维度上划分,分为:2.xD,2.5D和3D三个,也有一说法有3.5D,但在空间维度上最高就是3D。大致上,各个维度分别对应的技术如下图所示,这些技术往往是由某一家FAB或OSAT独家掌握,对应的技术路线网上也有很多资料,在本文就不详细叙述。当然,2D封装可列为是一种传统的封装工艺方式,由于没有用到芯片级别的曝光、显影、电镀等工艺,我们仍然将其划分到传统封装领域,未将其列入 Chiplet层面的封装。
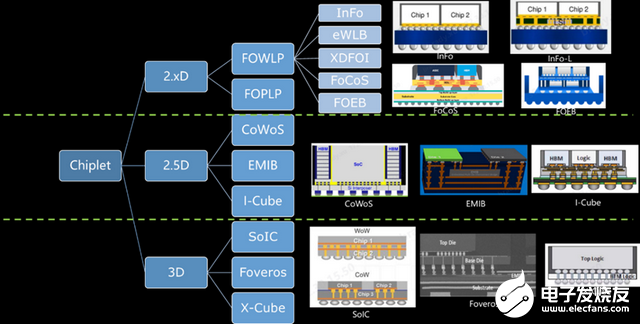
Chiplet的主要优势
Chiplet作为AI技术发展的一种基础应用技术,其主要优势在以下几个方面。
突破摩尔定律,大幅提升系统集成度和性能
传统的SoC芯片,把诸多功能模块都集中在一个芯片体中,所选Fab工艺节点需要向上兼容,比如CPU模块需要7nm, 而Serdes只需要22nm, 为完成整个SOC,不得不采用7nm工艺进行加工,无形中大幅增加了Fab的工艺难度及成本。而Chiplet将诸多模块一分为多,各个模块选用不同的工艺节点分别加工流片,最后通过先进封装组装在一起,降低了成本也节约了Fab先进制成的产能。
高端SiP技术,各个芯片可独立设计/可复用
SiP(系统级封装)面很广,严格意义上讲Chiplet也属于SiP。由于采用了Chiplet,SoC就可以拆分成多个芯片,可以彼此独立进行设计流片,分担了一家公司全包的运营及研发压力。各个芯片模块如标准零件一般,可以复用在各个系统中,彼此运营及研发的成本也大大降低。
异构异质集成,突破性能极限
SoC芯片分拆后, 各个芯片模块彼此流片,就无需采用同一种工艺节点。同时,最关键的,针对特别模块,我们可以发挥更多的想象空间,突破硅基的限制,采用第二、第三代等芯片材料,提高整体系统性能。
减少传输路径,增加系统带宽,提高整体性能
SoC集成了多个模块,且芯片面积较大, 模块与模块之间的互联往往要跨越整个芯片,传输路径较大,无形中降低了系统的整体性能。Chiplet,各个模块彼此独立,通过前期架构的合理设计,可以有效的减少传输路径,提高系统带宽和性能。
各个模块独立,大幅减小芯片面积并提升良率
Fab厂中, 受限于工艺能力及空气中的颗粒因素,芯片面积越大,对应的良率越低,SoC芯片拆分为独立芯片模块后,单颗芯片的面积变小,可以有效的提高整体良率,降低成本。
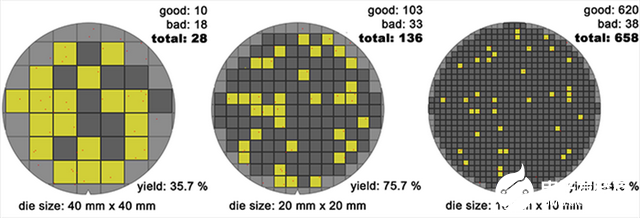
突破光照尺寸限制,增加系统集成
光刻机的光照Image尺寸一般在33X26=858mm², SoC芯片也要受光照尺寸的限制,不可能无限变大,超过光照尺寸后,工艺及设备难度都非常大,成本也会成指数增长。Chiplet芯片分叉后,有效的减小了芯片面积,从而降低了光照限制要求。
Chiplet的封装挑战
相较于传统的封装,封装处于整个芯片行业的末流,在进行芯片设计的时候封装端需要考虑的因素不多,整体重要性不高。Chiplet的诞生与快速发展,将封装人员推到了“芯片封装架构师“这一重要的职能。
“封装架构师”,需要从总体上综合考量诸多因素,包括:
应用层次:系统应用,带宽,IP接口等
系统层次:互联方式,速度,EDA软件等
封装层次:封装结构,散热,可靠性等
工艺层次:工艺路线,供应链,材料,设备等
这些因素彼此之间互为因果,牵一发而动全身给Chiplet带来了巨大的挑战。针对以往经验,我们在这儿归纳几点挑战及相应分析:
从系统架构到底层工艺
系统架构和工艺实现,在芯片行业里面,貌似一个是芯片最前端的岗位,而一个是最后端的职位,在传统封装领域,两者之间的交集不多。但是,在Chiplet时代这两者有着密切的联系。
我们在定一个系统架构时,需要考虑到系统的带宽、速度,功耗等因素, 而这些与我们所选的芯片间互联(D2D) IP强相关。
我们拿UCIe举例, UCIe作为一种国际D2D互联协议,它一些主要参数如下表:
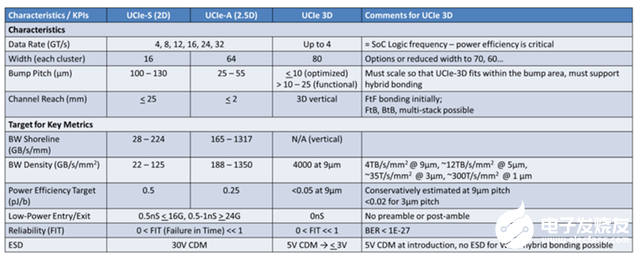
UCIe有S(Standard)、A(Advanced)和3D三种标准, 分别用传统Flipchip封装、2.5D封装和3D封装形式, 三种标准的带宽密度从UCIe-S的22(GB/s/mm²)到UCIe-3D的4000(GB/s/mm²),差不错相差了181倍之多。即便我们注意到UCIe-3D的速率只有4(GT/s)而UCIe-S的最高速率是32(GT/s),为什么还是有这么大的差距呢?答案就在先进封装工艺上。UCIe-S采用的是传统Filpchip封装工艺, bump pitch在130um。而UCIE 3D采用先进的Hybrid Bonding(HB)封装工艺,其bump pitch只有9um, 折算到面积的话相差了208倍,这就解释了为什么UCIe-3D在速率较低的情况下,整体带宽密度还是比UCIe-S高了181倍。
基于上面的例子, 先进封装实现了高密度互联,而实现高密度的方法就是HB这种先进封装工艺,系统架构通过先进封装和工艺紧密的联系在了一起。而先进封装,如我们之前所举例,有很多的封装形式及实现方式,不同的封装形式有不同的优点和缺点,我们如何选择合适的封装形式,从而选择具体封装工艺,需要从一开始的架构层面就考虑清楚。
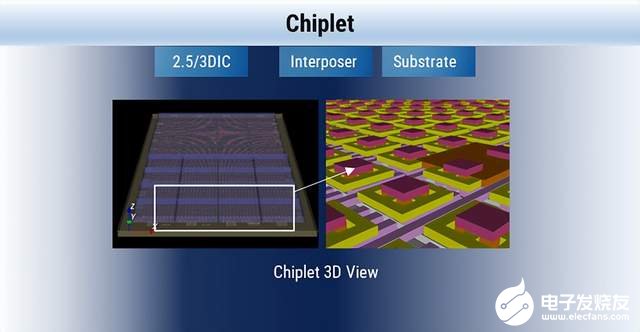
稳定的供应链资源
不管选择那种封装形式, 都需要在系统及运营的架构层面去考虑整个供应链问题,包括:EDA,IP,FAB,OSAT等,如下图。
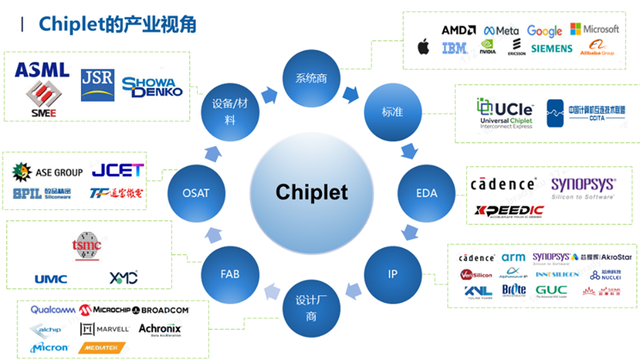
AI网络构建一套高性能芯片系统的时候,需要考虑很多因素:首先需要考虑的是使用的应用场景,满足哪些协议标准,采用什么EDA工具进行设计实现,选用的IP种类以及使用哪种D2D PHY来实现;再者,从选择什么Fab及工艺方式,采用何种封装形式、工艺再到选择OSAT公司,考虑选用的材料及设备等。这一系列需要考虑的因素,没有哪家公司可以完全囊括住。这些因素所牵涉的供应商类型众多且不同供应商提出的方案也各有千秋,从而形成完整的供应链体系。
稳定可靠的供应商资源是整个先进封装行业最大的挑战,包括垄断技术、产能短缺以及价格大幅波动等。比如说COWOS 2.5封装, TSMC一家独大,产能吃紧;又比如之前基板ABF厂家味之素的产能短缺,导致基板交期普遍拉到半年及以上的情况;再到最近AI芯片大火,导致HBM的供不应求,一天一价的状况;以上无不说明供应链资源的重要性。AI算力系统商身处芯片及Chiplet这个大行业中, 如何保证稳定且可靠的供应链资源也是各家企业遇到的重点挑战之一。
从全局考虑问题
Chiplet先进封装使得整个供应链变得如此紧密,密不可分。某种意义上来说,各个因素不是单方面影响的,而是互为因果,互相制约的,需要我们从辩证思维的方法来考量整个系统。
还是拿UCIe做对比, 系统商为了满足系统大带宽的要求,选择了UCIe-A作为芯片之间的互联标准,从而你就选择了芯片互联IP的方式,也选择了D2D PHY的互联形式,进而选择了2.5D这种先进封装形式。基于2.5D封装, 你就基本确定了芯片、Interposer及基板设计的团队及EDA工具,也确定了FAB及OSAT的供货范围, 从而有了设备及材料的范围。
相反的, 由于材料的限制,比如基板ABF材料,有一系列的物理属性:热膨胀性(CTE),会产生翘曲及应力集中,影响到整个封装结构,影响到FAB及OSAT封装工艺的实现;导热性,导热性能的高低 会影响到整个系统的散热性能及整体结构设计,影响系统端;电性能(介电常数Dk&损耗角DF), 基板速度上不去或存在严重串扰,影响整个D2D PHY的性能,从而影响一开始的系统带宽的要求。
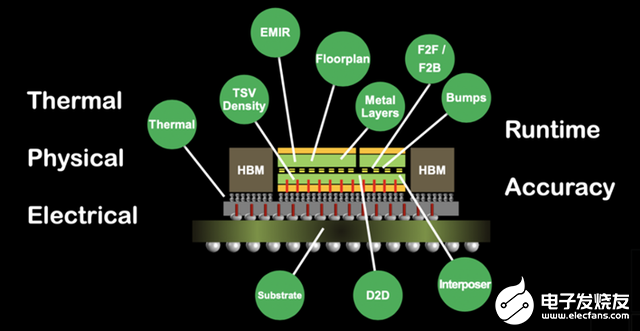
综上,从最上面的带宽要求,到最下面的材料,彼此是互为因果,相辅相成的。这也要求Chiplet在设计的时候需要总体上综合考虑,也是设计的难点,需要丰富的设计和实践经验。
项目经验的积累与创新
Chiplet先进封装作为这几年兴起的领域,不管是设计公司还是FAB&OSAT都没有非常丰富的经验,在这个过程中,很多问题可能之前是完全没有预料到的。特别是涉及到材料的问题,材料的选择方面相对复杂,很难用某种理论或某个实验来说明。
比如说,最近NVIDA Blackwell良率过低的问题,其很大一个原因在于COWOS-L这种工艺上,而TSMC大家都知道之前走的是COWOS-S的工艺,这是一种量产工艺。那大家就要问了, 为什么不继续用COWOS-S工艺呢?非得用一种没有量产经验的COWOS-L来做?主要是因为,S这种工艺是基于硅基Interposer上实现的, 最后将Interposer及上面的芯片焊接在有机基板上。一个硅基,一个有机,材料不同,彼此的热膨胀系统(CTE)相差甚多。在Interposer处于小尺寸范围内的时候,CTE的差距或许不足以在封装上产生足够大的应力及形变。但是, 随着系统带宽的要求越来越大, Interposer上面需要的HBM及芯片数量越来越多,当HBM到8个及以上的时候,中间的Interposer就需要3.3个Reticle(3.3x33x26=2831.4mm²)尺寸的时候,这个CTE差距就没法覆盖了。需要我们创新新的封装技术及结构, COWOS-L就来了。
COWOS-L,本质上是利用局部Si Bridge的方式替代COWOS-S整体Si Interposer的设计。最后的封装整体还是有机材料为主,与基板的有机材料在CTE上做匹配, 降低整个封装的翘曲及应力集中现象。但是毕竟是新技术,需要时间的积累;通过工程师不断的尝试,才能保证有稳定可靠的封装量产能力 。
解决这些工程实际问题,光靠理论及仿真是远远不够的。合格的先进封装技术需要项目经验的积累,需要工程实践的运作,更加需要工程人员的不断突破创新。
总述
如上面我们所分析的,AI算力芯片必须使用Chiplet先进封装,而先进封装又与系统架构,设计经验及供应链息息相关。从片内互联到片间互联再到服务器集群互联,这些互联层面环环相扣,Chiplet先进封装技术的迭代与创新将对未来AI芯片的性能产生长远的影响,也可以说先进封装技术是实现AI高性能计算/网络的物理层底座。任何将产业链上下游生态剥离的想法都是不切实际的。
奇异摩尔作为AI网络产业链的一环也是国内Chiplet互联领域的先行者。我们的团队拥有超过50+高性能网络及Chiplet量产项目的经验,将不断践行新质生产力,为我国智算中心的建设以及国产大算力芯片的性能突破贡献技术力量。














 工商网监
工商网监
评论