如何为深度学习选择 GPU 服务器?_目前哪里可以租用到GPU服务器?_gpu服务器出租价格
前言
现今,日益完善的深度学习技术和-AI-服务愈加受到市场青睐。与此同时,数据集不断扩大,计算模型和网络也变得越来越复杂,这对于硬件设备也提出了更为严苛的需求。如何利用有限的预算,最大限度升级系统整体的计算性能和数据传输能力成为了最为重要的问题。
GPU-的选择
熟悉深度学习的人都知道,深度学习是需要训练的,所谓的训练就是在成千上万个变量中寻找最佳值的计算。这需要通过不断的尝试识别,而最终获得的数值并非是人工确定的数字,而是一种常态的公式。通过这种像素级的学习,不断总结规律,计算机就可以实现像人一样思考。因而,更擅长并行计算和高带宽的-GPU,则成了大家关注的重点。
数据并行的原理很简单,如下图,其中-CPU-主要负责梯度平均和参数更新,而-GPU1和-GPU2-主要负责训练模型副本(model replica),这里称作“模型副本”是因为它们都是基于训练样例的子集训练得到的,模型之间具有一定的独立性。具体的训练步骤如下

除了计算能力之外,GPU-另一个比较重要的优势就是他的内存结构。首先是共享内存。在-NVIDIA-披露的性能参数中,每个流处理器集群末端设有共享内存。相比于-CPU-每次操作数据都要返回内存再进行调用,GPU-线程之间的数据通讯不需要访问全局内存,而在共享内存中就可以直接访问。这种设置的带来最大的好处就是线程间通讯速度的提高(速度:共享内存》》全局内存)。
而在传统的CPU构架中,尽管有高速缓存(Cache)的存在,但是由于其容量较小,大量的数据只能存放在内存(RAM)中。进行数据处理时,数据要从内存中读取然后在-CPU-中运算最后返回内存中。由于构架的原因,二者之间的通信带宽通常在-60GB/s-左右徘徊。与之相比,大显存带宽的-GPU-具有更大的数据吞吐量。在大规模深度神经网络的训练中,必然带来更大的优势。
另一方面,如果要充分利用-GPU-资源处理海量数据,需要不断向-GPU-注入大量数据。目前,PCIe-的数据传输速度还无法跟上这一速度,如果想避免此类“交通拥堵”,提高数据传输速度可以选择应用-NVlink-技术的-GPU-卡片。

4-GPUs-with-PCIe

4-GPUs-with-NVLink
NVLink-是目前最快的-GPU-高速互联技术,借助这种技术,GPU-和-CPU-彼此之间的数据交换速度要比使用PCIe 时快-5-到-12-倍,应用程序的运行速度可加快两倍。通过-NVLink 连接两个-GPU-可使其通信速度提高至-80-GB/s,比之前快了-5-倍。
其中-Nvidia-的-Volta-架构计算卡使用的-NVLink-2.0-技术速度更快(20-25Gbps),单通道可提供-50-GB/S-的显存带宽。

P100-NVLink1.0-数据传输模式
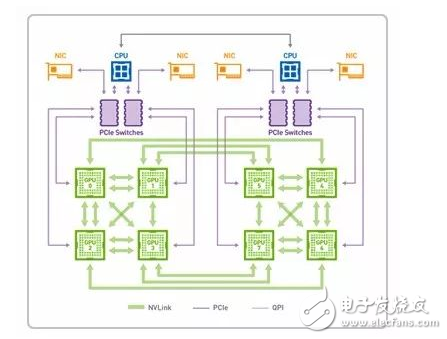
V100-NVLink2.0-数据传输模式

而且就目前而言,越来越多的深度学习标准库支持基于-GPU-的深度学习加速,通俗点描述就是深度学习的编程框架会自动根据-GPU-所具有的线程/Core-数,去自动分配数据的处理策略,从而达到优化深度学习的时间。而这些软件上的全面支持也是其它计算结构所欠缺的。
简单来看,选择-GPU-有四个重要参数:浮点运算能力、显存、数据传输与价格。
对于很多科学计算而言,服务器性能主要决定于-GPU-的浮点运算能力。特别是对深度学习任务来说,单精浮点运算以及更低的半精浮点运算性能则更为重要。如果资金充足的情况下,可以选择应用-NVLink-技术单精计算性能高、显存大的-GPU-卡片。如果资金有限的话,则要仔细考量核心需求,选择性价比更高的-GPU-卡片。
内存大小的选择
心理学家告诉我们,专注力这种资源会随着时间的推移而逐渐耗尽。内存就是为数不多的,让你保存注意力资源,以解决更困难编程问题的硬件之一。与其在内存瓶颈上兜转,浪费时间,不如把注意力放在更加紧迫的问题上。如果你有更多的内存,有了这一前提条件,你可以避免那些瓶颈,节约时间,在更紧迫问题上投入更多的生产力。
所以,如果资金充足而且需要做很多预处理工作,应该选择至少和-GPU-内存大小相同的内存。虽然更小的内存也可以运行,但是这样就需要一步步转移数据,整体效率上则大打则扣。总的来说内存越大,工作起来越舒服。
在一些深度学习案例中,硬驱会成为明显的瓶颈。如果数据组很大,通常会在硬驱上放一些数据,内存中也放一些,GPU-内存中也放两-mini-batch。为了持续供给-GPU,我们需要以-GPU-能够跑完这些数据的速度提供新的-mini-batch。
为此,可以采用和异步-mini-batch-分配一样的思路,用多重-mini-batch-异步读取文件。如果不异步处理,结果表现会被削弱很多(5-10%),而且让认真打造的硬件优势荡然无存。那么,这时候就需要-SSD,因为-100-150MB/S-的硬驱会很慢,不足以跟上-GPU。
许多人买一个-SSD-是为了舒服:程序开始和响应都快多了,大文件预处理也快很多,但是,对于深度学习来说,仅当输入维数很高,不能充分压缩数据时,这才是必须的。如果买了-SSD,则应该选择能够存下和使用者通常要处理的数据集大小相当的存储容量,也额外留出数十-GB-的空间。另外用普通硬驱保存尚未使用的数据集的主意也不错。
非常好我支持^.^
(60) 93.8%
不好我反对
(4) 6.2%
相关阅读:
- [电子说] 租用GPU服务器一般多少钱 2024-11-25
- [电子说] GPU服务器和传统的服务器有什么区别 2024-11-07
- [电子说] GPU服务器AI网络架构设计 2024-11-05
- [电子说] GPU服务器用途 2024-10-18
- [电子说] GPU服务器在AI训练中的优势具体体现在哪些方面? 2024-09-11
- [电子说] gpu服务器与cpu服务器的区别对比,终于知道怎么选了! 2024-08-01
- [电子说] gpu服务器是干什么的 gpu服务器与cpu服务器的区别有哪些 2024-01-30
- [电子说] 超微gpu服务器评测 2024-01-10
( 发表人:彭菁 )