向量处理机结构原理教程
向量处理机结构原理教程
学习目标:
理解向量的三种处理方式及其特点;
掌握CRAY-I的向量处理;
掌握链接技术的基本思想;
掌握链接流水线示意图的画法及性能计算。
正文:
3.5向量处理机
3.5.1向量处理方式和向量处理机
这里,举一个简单的例子来说明向量处理方式。考虑以下向量计算:
D = A *(B + C)
其中A、B、C、D是长度为 N 的向量。


水平处理方式也就是逐个求d[i]的方式,为此,先计算:d[1] = a[1]*(b[1] + c[1]);再计算:d[2] = a[2]*(b[2] + c[2]);……;最后计算:d[N] = a[N]*(b[N] + c[N])。一般的计算机就是采用这种方式组成循环程序进行处理的。在每次循环中,至少要用到如下几条机器指令:
……
ki = bi + ci
di = ki * ai
……
BE(等于"0"分支成功)
上面程序计算共需N次循环,其中N-1次分支成功,在每次循环中有一次数据相关。如果用静态流水线,则要进行2次乘和加的功能转换,所以共出现 N 次数据相关和 2N 次功能切换。因此,这种水平处理方式不适合于对向量进行流水处理。
2. 垂直(纵向)处理方式
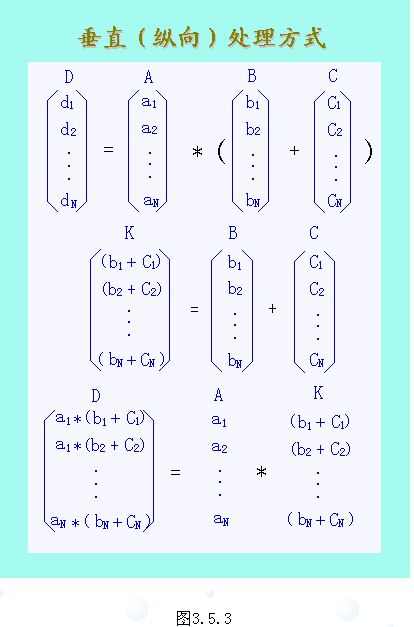
垂直处理方式是将整个向量按相同的运算处理完之后,再去执行别的运算。对于上式,则有:
K = B + C
D = K * A
可以看出,这种处理方式仅用了两条向量指令,且处理过程中没有出现分支指令,每条向量指令内无相关,两条向量指令间仅有1次数据相关。如果仍用静态多功能流水线,也只需1次功能切换,所以这种处理方式适合于对向量进行流水处理。
在这种处理方式中,由于向量长度N是不受限制的,无论N有多大,相同的运算都用一条向量指令完成。因此,向量运算指令的源向量和目的向量都存放在存储器内,这使这种处理机流水线运算部件的输入、输出端都直接(或经向量数据缓冲器)与存储器相联,从而构成所谓存储器-存储器型操作的运算流水线,其结构如图3.5.4所示。这种结构对存储器带宽的要求很高。CDC公司的STAR-100、CYBER-205等中央处理机都是采用这种结构。

3. 分组(纵横)处理方式

分组处理方式是把长度为N的向量,分成若干组,每组长度为 n ,组内按纵向方式处理,依次处理各组。
为了减少循环的影响,每组内各用两条向量指令,各组内仅有一次向量指令的数据相关。如果也用静态多功能流水线,则各组需2次功能切换,比水平处理方式要少。所以,这种处理方式也适合于对向量进行流水处理。
这种处理方式对向量长度N的大小亦不限制,但是,每一组的长度最大不能超过n。因此,可设置长度为n的向量寄存器,使得每组向量运算的源向量和目的向量都在向量寄存器中,运算流水线的输入、输出端都与向量寄存器相联,从而构成所谓寄存器-寄存器型操作的运算流水线。

这种结构要求有容量足够大的向量寄存器组。它们不但能存放源向量,而且能保留中间结果,从而大大减少访问存储器的次数;此外,可降低对存储器带宽的要求,亦可减少因存储器访问冲突而引起的等待时间,从而提高处理速度。
3.5.2向量处理机实例分析
七十年代中期问世的CRAY-1向量机是向量处理机的典型代表,其向量流水处理部件简图如图3.5.6所示。可为向量运算使用的功能部件有:整数加、逻辑运算、移位、浮点加、浮点乘、浮点迭代求倒数。它们都是流水处理部件,且六个部件可并行工作。向量寄存器组的容量为512个字,分成8块。每个 Vi 块可存元素个数达64的一个向量。
为了能充分发挥向量寄存器组和可并行工作的六个功能部件的作用以及加快向量处理, CRAY-1设计成每个 Vi 块都有单独总线可连到六个功能部件,而每个功能部件也各自都有把运算结果送回向量寄存器组的输出总线。这样,只要不出现 Vi 冲突和功能部件冲突,各个 Vi 之间和各个功能部件之间都能并行工作,大大加快了向量指令的处理,这是CRAY-1向量处理的显著特点。
所谓 Vi 冲突指的是并行工作的各向量指令的源向量或结果向量的 Vi 有相同的。除了相关情况之外,就是出现源向量冲突,例如:
V4 = V1 + V2
V5 = V1 ∧ V3
这两条向量指令不能同时执行,需在第一条向量指令执行完,释放 V1 后,第二条指令才能执行。这是因为这两条指令的源向量之一虽然都是取自 V1 ,但二者的首元素下标可能不同,向量长度也可能不同,难以由V1同时提供两条指令所需的源向量。这种冲突和前面所讨论的结构相关是一样的。所谓功能部件冲突指的是同一个功能部件被一条以上的并行工作向量指令所使用。例如:
V4 = V2 * V3
V5 = V1 * V6
这两条向量指令都需用到浮点相乘部件,那就需在第一条指令执行完毕,功能部件释放后,第二条指令才能执行。
CRAY-1有如图3.5.7所示的四种向量指令。第1种,每拍从 Vi 、Vj 块顺序取得一对元素送入功能部件。各种功能部件执行的时钟周期数不同,其输出也是每拍送进 Vk 块一个结果元素。元素对的个数由VL(向量长度)寄存器指明。向量屏蔽寄存器(VM)为64位,每位对应V的一个元素。在向量合并或测试时,由VM控制对哪些元素进行合并和测试。一条指令至多只能处理64对元素(对应每块的容量)。若向量的长度大于64,需用向量循环程序将其分段,各段中向量元素个数要小于等于64,然后以段为单位从存储器中调入并进行处理。第2种和第1种的差别只在于它的一个操作数取自标量寄存器 Si 。大多数向量指令都属这两种。由于它们不是由存储器,而是由向量寄存器取得操作数,所以流水速度可很高,CRAY-1的时钟周期时间为12.5ns(一拍)。第3、4种是控制存储器与V向量块之间的数据传送,Load、Store一个字(元素)需花6拍。
CRAY-1向量处理的另一个显著特点是,只要不出现功能部件冲突和源向量冲突,通过链接结构可使相关的向量指令也能并行处理。
例如,对上述向量运算 D = A * (B + C),若 N ≤64,向量为浮点数,则在B、C取到 V0 、V1 后,就可用以下三条向量指令求解:
1、V3 ← 存储器(访存,载入A)
2、V2 ← V0 + V1(浮点加)
3、V4 ← V2 * V3(浮点乘,存D)
第1、2条指令无任何冲突,可以并行执行。第3条指令与第1、2条指令之间存在数据相关,不能并行执行,但是如果能够将第1、2条指令的结果元素直接链接到第3条指令所用的功能部件,那么第3条指令就能与第1、2条指令并行执行。其链接过程如图3.5.8所示。
由此可见,所谓链接特性,实质上是把流水线“定向”的思想引入到向量执行过程的结果。 CRAY-1在把元素送往功能部件及把结果存入 Vi 时都需一拍。由于第1、2条指令之间没有任何冲突,可以同时执行,而“访存”拍数正好与“浮加”的一样,因此,从访存开始,直至把第一个结果元素存入 V4 ,所需拍数(亦称为链结流水线的流水时间)为:
1(送) + 6(访存) + 1(入) + 1(送) + 7(浮乘) + 1(入) = 17拍
此后,就是每拍取得一个结果元素存入V4。显然,这要比第1、2条指令全执行完,所有元素全进入V2、V3后,才开始执行第3条指令要快得多。通过这种链接技术使得 CRAY-1 流水线能灵活组织,从而更能发挥流水技术的效能。
CRAY-1 的向量指令还可做到“源V”和“结果V”是同一个,这种向量递归操作和前述的链接特性对于实现诸如求向量点积等是很有好处的。
上面我们结合 CRAY-1 介绍了向量流水机器的结构特点。然而,要使软件能充分发挥硬件所提供的这些特点却是很不容易的,它必然要对语言结构和编译程序提出新的要求。例如,它希望高级语言能增设向量运算符(如向量加、向量乘等),不然,程序设计者在编制高级语言程序时,要把向量运算通过 DO LOOP 实现,而编译程序反过来却又要把 DO LOOP 型语句变换成向量型的机器语言去执行。例如
C = A + B
的向量运算,程序设计者是用
DO 20 I = 1,N
20 C(I) = A(I) + B(I)
实现,但编译程序却又要把它编译成
VECT_BEGIN
A,B,C = VECTOR(1…N)
C = A + B
VECT_END
去执行。
另外,优化的目标程序必然要和向量流水机器的具体结构特点密切相关,这会使编译程序的设计复杂化。例如,对图3.1.7所示的 ASC 结构,那就要求把目标程序中的相加指令和相乘指令分别集中在一起,以减少流水线功能切换所费时间。然而,CRAY-1 却无此要求,因为它有独立的能并行执行的相乘、相加功能部件。但是,它却要求编译程序能充分发挥多功能部件和上述链接能力所能提供的多条向量指令可并行执行的特点。
非常好我支持^.^
(489) 97.2%
不好我反对
(14) 2.8%
相关阅读:
( 发表人:admin )