降低Cache失效率的方法[2]
降低Cache失效率的方法[2]
表4.7列出了在这两种极端情况之间的各种块大小和各种 Cache 容量的平均访存时间。速度最快的情况: Cache 容量为1KB、4KB、16KB的情况下块大小为32字节时速度最快;容量为64KB和256KB时,64字节最快。实际上,这些块大小都是当今处理机器 Cache 中最常见的。

如前所述, Cache 设计者一直在努力同时减少失效率和失效开销。从失效开销的角度来讲,块大小的选择取决于下一级存储器的延迟和带宽两个方面。高延迟和高带宽时,宜采用较大的 Cache 块,因为这时每次失效时,稍微增加一点失效开销,就可以获得许多数据。与之相反,低延迟和低带宽时,宜采用较小的 Cache 块,因为采用大 Cache 块所能节省的时间不多。一个小 Cache 块失效开销的两倍与一个两倍于其大小的 Cache 块的失效开销差不多,而且采用小 Cache 块,块的数量多,有可能减少冲突失效。
4.3.2提高相联度
表4.5和图4.3.1、图4.3.2已经说明了提高相联度会使失效率下降。从中我们可以得出两条经验规则。第一,对于表中所列出的 Cache 容量,从实际应用的角度来看,8路组相联在降低失效率方面的作用已经和全相联一样有效。也就是说,采用相联度超过8的方法实际意义不大。第二条规则叫做2:1 Cache 经验规则,它是指容量为N的直接映象 Cache 的失效率和容量为N/2的两路组相联 Cache 差不多相同。
许多例子都说明,改进平均访存时间的某一方面是以损失另一方面为代价的。增加块大小的方法会在降低失效率的同时增加失效开销,而提高相联度则是以增加命中时间为代价。Hill曾发现,当分别采用直接映象和两路组相联时,对于 TTL 或 ECL 板级 Cache ,命中时间相差10 %;而对于定制的 CMOS Cache,命中时间相差2 %。所以,为了实现很高的处理器时钟频率,就需要设计结构简单的 Cache;但时钟频率越高,失效开销就越大(所需的时钟周期数越多)。为减少失效开销,又要求提高相联度。下面通过一个例子进一步说明。
例4.5 假定提高相联度会按下列比例增大处理器时钟周期:
时钟周期2路 =1.10×时钟周期1路
时钟周期4路 =1.12×时钟周期1路
时钟周期8路 =1.14×时钟周期1路
假定命中时间为1个时钟,直接映象情况下失效开销为50个时钟周期,而且假设不必将失效开销取整。使用表4.5中的失效率,试问当 Cache 为多大时,以下不等式成立?
平均访存时间8路 < 平均访存时间4路
平均访存时间4路 < 平均访存时间2路
平均访存时间2路 < 平均访存时间1路
解: 在各种相联度的情况下,平均访存时间分别为
平均访存时间8路 = 命中时间8路 + 失效率8路 ×失效开销8路
= 1.14+失效率8路 ×50
平均访存时间4路 = 1.12 +失效率4路 ×50
平均访存时间2路 = 1.10 +失效率2路 ×50
平均访存时间1路 = 1.00 +失效率1路 ×50
在每种情况下的失效开销相同,都是50个时钟周期。把相应的失效率代入上式,即可得平均访存时间。例如,1KB的直接映象 Cache 的平均访存时间为
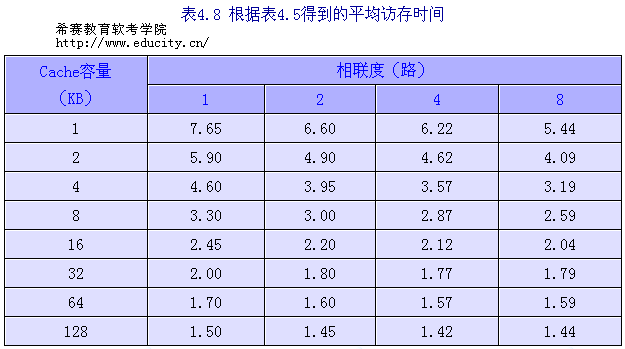
平均访存时间1路 = 1.00 +(0.133×50) = 7.65
容量为128KB的8路组相联 Cache 的平均访存时间为:
平均访存时间8路 =1.14 +(0.006×50) = 1.44
利用这些公式和表4.5中给出的失效率,可得各种容量和相联度情况下 Cache 的平均访存时间,如表4.8所示。表中的数据说明,当 Cache 容量不超过16KB时,上述三个不等式成立。从32KB开始,对于平均访存时间有:4路组相联的平均访存时间小于2路组相联的,2路组相联的小于直接映象的,但8路组相联的却比4路组相联的大。
请注意,本例中没有考虑时钟周期增大对程序其它部分的影响。
4.3.3Victim Cache
增加 Cache 块大小和提高相联度是从 Cache 一出现就被体系结构设计者们用来降低失效率的两种经典方法。从本小节开始,我们来看一看近几年提出的几种方法,这些方法能在不影响时钟周期或失效开销的前提下降低 Cache 失效率。
一种能减少冲突失效次数而又不影响时钟频率的方法是:在 Cache 和它与下一级存储器的数据通路之间增设一个全相联的小 Cache ,称为Victim Cache。图4.3.4为其结构框图。 Victim Cache 中存放由于失效而被丢弃(替换)的那些块(即victim)。每当发生失效时,在访问下一级存储器之前,先检查 Victim Cache 中是否含有所需的块。如果有,就将该块与 Cache 中某个块做交换。Jouppi于1990年发现,含1到5项的 Victim Cache 对减少冲突失效很有效,尤其是对于那些小型的直接映象数据 Cache 更是如此。对于不同的程序,一个项数为4的 Victim Cache能使一个4KB直接映象数据 Cache 的冲突失效减少20%~90%。

从 Cache 的层次来看, Victim Cache 可以看成位于 Cache 和存储器之间的又一级 Cache ,采用命中率较高的全相联策略,容量小,而且仅仅在替换时发生作用。
4.3.4伪相连Cache
有一种方法既能获得多路组相联 Cache 的低失效率又能保持直接映象 Cache 的命中速度,这种方法称为伪相联或列相联。
1. 基本思想及工作原理
采用这种方法时,在命中情况下,访问 Cache 的过程和直接映象 Cache 中的情况相同;而发生失效时,在访问下一级存储器之前,会先检查 Cache 另一个位置(块),看是否匹配。确定这个另一块的一种简单的方法是将索引字段的最高位取反,然后按照新索引去寻找伪相联组中的对应块。如果这一块的标识匹配,则称发生了伪命中。否则,就只好访问下一级存储器。
2. 快速命中与慢速命中
伪相联 Cache 具有一快一慢两种命中时间,它们分别对应于正常命中和伪命中的情况。图4.3.5中绘出了它们的相对关系。使用伪相联技术存在一定的危险:如果直接映象 Cache 里的许多快速命中在伪相联 Cache 中变成慢速命中,那么这种优化措施反而会降低整体性能。所以,要能够指出同一组中的两个块哪个为快速命中,哪个为慢速命中,这是很重要的。一种简单的解决方法就是交换两个块的内容。
下面通过一个例子来说明伪相联带来的好处。
例4.6 假设当在按直接映象找到的位置处没有发现匹配,而在另一个位置才找到数据(伪命中)需要2个额外的周期。仍用上个例子中的数据,问:当 Cache 容量分别为2KB和128KB时,直接映象、两路组相联和伪相联这三种组织结构中,哪一种速度最快?
解: 首先考虑标准的平均访存时间公式:
平均访存时间伪相联 = 命中时间伪相联+失效率伪相联×失效开销伪相联
我们从该公式的最后一部分着手。不管我们对命中的情况做了何种改进,失效开销总是相同的。为了确定失效率,需要知道什么时候会发生失效。只要我们总是通过把索引的最高位变反的方法来寻找另一块,在同一“伪相联”组中的两块就是用同一个索引选择得到的,这与在两路组相联 Cache 中所用的方法是一样的,因而它们的失效率相同,即
失效率伪相联 = 失效率2路
再看命中时间。伪相联 Cache 的命中时间等于直接映象 Cache 的命中时间加上在伪相联查找过程中命中(即伪命中)的百分比乘以该命中所需的额外时间开销,即
命中时间伪相联=命中时间1路+伪命中率伪相联×2
伪相联查找的命中率等于两路组相联 Cache 的命中率和直接映象 Cache 命中率之差:
伪命中率伪相联 =命中率2路-命中率1路
=(1-失效率2路)-(1-失效率1路)
=失效率1路-失效率2路
综合上述分析,有
平均访存时间伪相联=命中时间1路+(失效率1路-失效率2路)×2
+失效率2路×失效开销1路
将表4.5中的数据代入上面的公式,得
平均访存时间伪相联,2KB =1+(0.098-0.076)×2+(0.076×50)=4.844
平均访存时间伪相联,128KB=1+(0.010-0.007)×2+(0.007×50)=1.356
根据上一个例子中的表4.8,对于2KB Cache ,可得
平均访存时间1路 =5.90 个时钟
平均访存时间2路 =4.90 个时钟
对于128KB的 Cache 有,可得
平均访存时间1路 =1.50 个时钟
平均访存时间2路 =1.45 个时钟
可见,对于这两种 Cache 容量,伪相联 Cache 都是速度最快的。
尽管从理论上来说,伪相联是一种很有吸引力的方法,但它的多种命中时间会使 CPU 流水线的设计复杂化。因此伪相联技术往往应用在离处理器比较远的 Cache 上,如二级Cache。
非常好我支持^.^
(3) 100%
不好我反对
(0) 0%
相关阅读:
- [电子说] Cache和内存有什么区别 2024-09-26
- [电子说] 高速缓冲存储器有什么作用 2024-09-10
- [电子说] 解析Arm Neoverse N2 PMU事件L2D_CACHE_WR 2024-09-03
- [电子说] buffers内存与cached内存的区别 2024-07-29
- [电子说] Cortex R52内核Cache的具体操作(2) 2024-07-15
- [电子说] Cortex R52内核Cache的相关概念(2) 2024-07-15
- [电子说] Cortex R52内核Cache的相关概念(1) 2024-07-15
- [电子说] CortexR52内核Cache的具体操作 2024-07-15
( 发表人:admin )