基于信息熵的WSN节点拥塞避免机制 - 全文
近年来,WSN中的拥塞问题日益引起了学术界的广泛关注。研究人员逐步提出了多种针对WSN自身特点的控制策略(如CODA,ESRT,Fusion等)。这些控制算法采用了不同的机制有效地减轻拥塞,是一种被动的方式,可能导致节点数据的重发,且一般不能完全消除节点拥塞现象。
现有无线传感器网络的节点拥塞控制机制都是在节点发生拥塞时才采取一定的拥塞控制措施。但是,无线传感器网络节点大规模密集部署,在突发数据流引发拥塞后,再采用拥塞控制措施也不一定可以完全避免节点拥塞,很有可能导致灾难性的后果发生。因此,在本文中,提出了基于节点相对信息熵的拥塞避免机制,该拥塞避免机制是基于事件的有效信息量,真正体现无线传感器网络以事件为中心的特点。
1 基于信息熵的节点拥塞避免策略
节点拥塞避免的重要问题是按一定的策略,为网络资源均衡合理地分配数据窗的大小。在无线传感器网络中,由于节点大规模部署,若两个节点位于各自的通信半径内,它们可以直接通信。节点响应监测区域内的事件或周期性地产生数据并发送至基站。如图1所示,对于相同的感知区域,把感知到的数据转发到下游节点,其下游节点不断把数据再转发到自身的下游节点,这样不断地进行数据转发,最后可能导致下游的某个节点产生拥塞。显然,对于大规模部署和处理紧急事件的无线传感器网络来讲,拥塞不仅严重浪费了节点能量还降低了转发效率,而且还可能导致不可预料的事件发生。
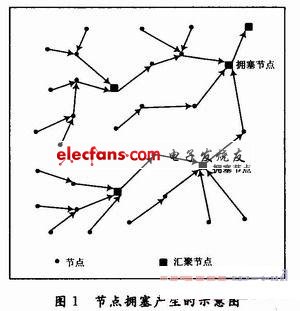
1.1 WSN节点网络模型
WSN由分布在各个地方的传感器节点通过自组织方式所形成的网络模型。在该模型中,传感器节点采集数据,通过无线传感器网络传递到基站,然后再传递给检测中心。在这里假设每一个传感器节点都有直接或间接与基站通信的能力,则节点会响应监测区域内的事件或周期性地产生数据并发送到基站。
假设N个传感器节点按相对均匀的随机高密度部署在一个监测区域内,具有以下性质:
(1)N个传感器节点被随机部署在监测区域,基站不受能源限制,且位于一个区域的边界上,其他传感器节点为电池驱动;
(2)所有节点都为静止节点,且各节点的软硬件同构,通信频率相同;
(3)每个节点采用全向天线,节点之间为双向链路即A节点能和B节点通信,B节点也能和A节点通信,节点的通信范围有限且通信半径保持为R;
(4)WSN的信道质量可靠且传输的误码率基本可以忽略,其路由机制保持相对静止,不会出现很大范围的路由变化。
1.2 WSN中信息熵的数学定义
在此基于WSN的网络模型和信息论,给出WSN节点的信息熵的数学定义。
定义1:节点信息熵:根据香农的定义,自信息的数学期望为信息熵,因此节点信息熵表示节点N每发送一个数据包所提供的平均信息量:

式中:q表示ai(i=1,2,…,q-1,q)的取值有q种可能性;P(ai)为字符ai出现的概率,节点信息熵H(X)表征了传感器节点整体的统计特征,是总体平均不确定性的量度(单位:比特/数据包)。式(1)中的单位取决于对数函数的底数。本文中,取对数函数底数为2,即表示每个数据包含有1比特的信息量。
在无线传感器网络中,节点感知到的数据既存在一定的差异又有一定的冗余,为了表征节点之间的这种关系,下面引入了节点相对信息熵。
定义2:节点相对信息熵:假设P和Q是两个概率分布函数,则定义P相对于Q的信息距离即节点相对信息熵为:

式中:Pi和Qi为一个字符在节点中所出现的概率。
节点相对信息熵可用于计算任意两节点之间节点信息熵的差异性的大小。它的物理意义是两组概率分布之间的差异性程度,因而对于两组不同的概率分布P和Q,计算其节点相对信息熵D(P‖Q),如果这个值越小,表明两组概率分布越接近,这两个节点之间的数据相似程度越大,则节点P就可以减少向节点Q发送数据包以保证网络的畅通。对于极限情况,当D(P‖Q)=0时,表示两组概率分布完全相等,则这两个节点之间的数据几乎一样,此时,节点P可以暂停向节点Q发送数据包。
1.3 基于节点信息熵的拥塞避免策略
在一种路由协议机制下,若一个数据包从节点u发送至邻居节点d,则称u是d的上游节点,d是u的下游节点。在本文的网络模型中,总是假设路由机制是静态的或是很少进行更新的,因此可知每个下游节点d总是可以知道有多少个上游节点u。按照上述基本假设,本文提出的拥塞避免策略过程如图2所示。
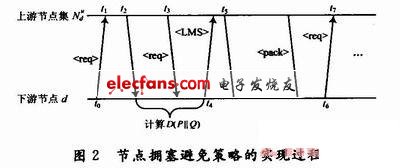
1.4 算法的分析与实现
在这里以双重身份节点m(节点m既可以看作下游节点,也可以看作上游节点)作为主要考虑节点,首先当节点m作为上游节点时,向其自己的上游节点发送消息
(1)如果节点m发送数据窗SDWm>0且当前信道可用,则节点m根据其收到的下游节点发送的广播消息
(2)否则节点m发送数据窗SDWm=0,然后向其上游节点集发送消息
(3)如果仅作为上游节点u的发送数据窗SDWm>0,则上游节点u退出上游节点集![]() ,此时上游节点u不响应下游节点d发送的
,此时上游节点u不响应下游节点d发送的
(4)如果仅作为上游节点u发送数据窗SDWm=0,上游节点集![]() 则向下游节点发送消息(req>;
则向下游节点发送消息(req>;
(5)下游节点m收到消息
(6)根据计算得到节点相对信息熵的大小向上游节点集![]() 广播消息
广播消息
在上述过程中,若上游节点u当前的发生数据窗大于0,则不响应下游节点d发送的
2 实验仿真
为了验证本文所提出的避免节点拥塞机制的性能,选取经典的CODA算法作比较。现假设本文的仿真实验环境设置如下:
(1)选取200个节点随机部署在600×600的正方形区域内,基站选择在该区域边界上;
(2)节点的位置是固定的,且节点之间的通信半径R=50,网络带宽设置为1 Mb/s;
(3)信道质量相对可靠,可忽略信道对误码率的影响,源节点产生的数据包大小相同,且报文的产生率为每单位时间10个数据包,节点可用最大缓冲区间为15个数据包。
图3描述了仿真过程中的网络传输延迟。从图中可以看出,CODA下的网络传输延迟(每个到达基站的数据包在网络中停留的时间)得到了一定的控制,而本文由于采用了基于发送数据窗的拥塞避免机制,降低了数据包在缓冲区内的平均等待时间,减少了在网络中的传输延迟。
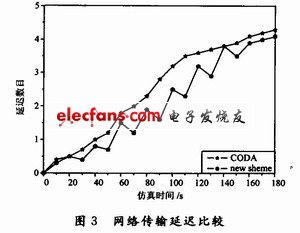
图4表示了对网络平均丢包率的比较。由于仿真环境假设信道质量相对可靠,不会对网络平均丢包率造成影响,因此,这里的数据包的丢失主要是由网络的拥塞引起的。从图中可以看出,CODA的网络平均丢包率比本文的平均丢包率高。由于CODA采取了调节局部拥塞的节点,则在第120 s左右网络平均丢包率趋于稳定,网络平均丢包率几乎为0,但并不能保证在有突发数据流出现时随着时间的推移还会出现网络平均丢包率增大的现象。而本文的算法完全是采用的节点避免策略,因此在整个网络生命周期内,网络的平均丢包率几乎为0。
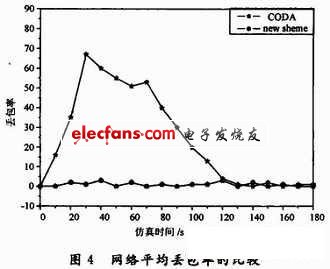
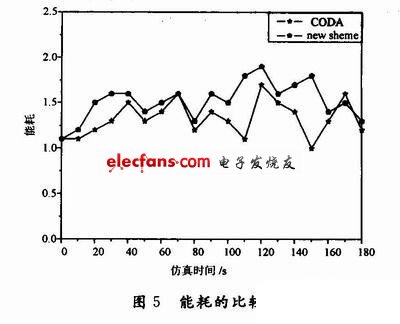
图5主要从无线传感器网络的能耗上进行比较。由于CODA下的数据包传输跳数较少,进而转发数据包的次数也会减少,所以CODA的能耗相对较低一些。本文的算法虽然增加了传输跳数和节点之间的通信次数,但却减少了由于冲突和拥塞带来的能量浪费,进而有效地提高了能源的利用率。从图5中可以看出,本文的算法比CODA的能量消耗相对多些,但这对于处理突发的紧急事件却起着重要的作用,这样即使多消耗了
一点能量,却可以避免灾难性后果的发生。
3 结语
本文在现有节点拥塞控制的基础上提出了基于信息熵的节点拥塞避免机制。仿真测试表明,该算法更适合于突发情况下的无线传感器网络的特点。算法使用的基于信息熵的拥塞避免策略,可以有效地避免节点产生拥塞,从而减少了网络的平均丢包率,降低了网络中的传输延迟,这对于处理突发紧急的事件是非常重要的,由于节点不需要时刻监测信道状态,因此只有在有突发事件发生时,才会消耗大量能量。总的来说,本文的算法是比较合理的。
- 第 1 页:基于信息熵的WSN节点拥塞避免机制
- 第 2 页:基于节点信息熵的拥塞避免策略
本文导航
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
相关阅读:
- [RF/无线] wsn的传输介质及特点有哪些 wsn如何实现与互联网互联 2023-06-14
- [电子说] WSN网络可以用来干什么 wsn与物联网的区别与联系 2023-06-14
- [电子说] 萨科微宋仕强文章被华尔街日报、New York Daily纽约日报、AmericanNewsNetwork美国新 2023-06-19
- [电子说] 人员定位及轨迹管理的技术原理、应用领域及作用 2023-05-23
- [电子说] 楼宇自动化的发展趋势:通过互连传感器提升能源效率 2023-04-13
- [电子说] 浅析网络认证技术 2021-11-18
- [电子说] 无线通信传感网络的结构组成 2021-08-23
- [电子说] 基于组的WSN异常检测入侵检测系统的应用方案 2021-06-29
( 发表人:叶子 )