 电子发烧友App
电子发烧友App



机器学习是近段时间以来的大热门,而尽管 EDA 处理的也是大数据类型的问题,但在将机器学习技术整合进 EDA 工具方面还没有取得很大的进展。
许多 EDA 问题和解决方案本质上就是关于统计的,这说明机器学习自然而然适合 EDA。那为什么这个领域在采用机器学习技术上如此缓慢而视觉识别和搜索等其它技术领域却可以如此轻松地接纳它?
Solido Design Automation 技术运营副总裁 Jeff Dyck 表示:“你可以感受到这是一个机器学习问题。我们有大量的数据,但我们可以应用哪些方法来解决这些问题?这才是难点。不是说读一本教科书或学一门课就能将这些方法应用到所有问题上。工程问题需要一个不同的角度。”
在深入了解机器学习在哪些地方有所应用之前,我们先看看一些问题。
从基于规则到深度学习
我们首先对这些技术进行一个分类吧。“从最广义的角度讲,在 EDA 领域,我们全部都已经习惯了基于规则的方法(rule-based techniques,RBT)。”英伟达资深工程总监 Ting Ku 解释说,“实际上机器学习是RBT的一个子集,而深度学习又是机器学习的一个子集。RBT是确定性的,不会涉及到数据库,也不会定义特征。而机器学习的出发点是统计的,而非确定性的,而且因为必须从经验中学习,所以还会涉及到数据库。使用机器学习,我们也许还需要预定义的特征,而这正是机器学习和深度学习的区别。对于深度学习而言,除了没有预定义的特征,其它都和机器学习一样。所以问题来了:‘特征(feature)是什么?’”
一旦你有了特征并存储了足够的数据,你就要想办法把它们用起来。“搜索整个设计空间是不切实际的。”NetSpeed Systems营销和业务开发副总裁 Anush Mohandass 说,“由于该空间高度非线性的本质,搜索时间会随着搜索范围扩大而指数级增加。对于这样的问题,机器学习(其中,过去的解决相似问题的经验可被用作训练数据,从而学习和预测可用于相似的新问题的解决方案)表现了巨大的潜力。”
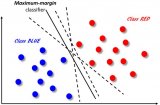
机器学习的方法有很多,大体上可分为监督学习、无监督学习和强化学习。大多数 EDA 应用都着眼于监督学习。E3 Data Science 的 CTO Eric Hall 解释说:“有两种类型的监督学习。回归(regression)可用于我们想要预测数值的情况,而分类(classification)则可用于预测多个结果中一个结果的情况。可以解决这些问题的机器学习算法有很多,但是却没有任何一种能够单独解决所有问题。”
也还存在其它问题,Hall 补充说:“在寻找未被发现的特征来对非线性进行建模方面,深度学习技术表现很出色,但它却是一个黑箱,难以解释而且可能需要很长的训练时间。”
训练
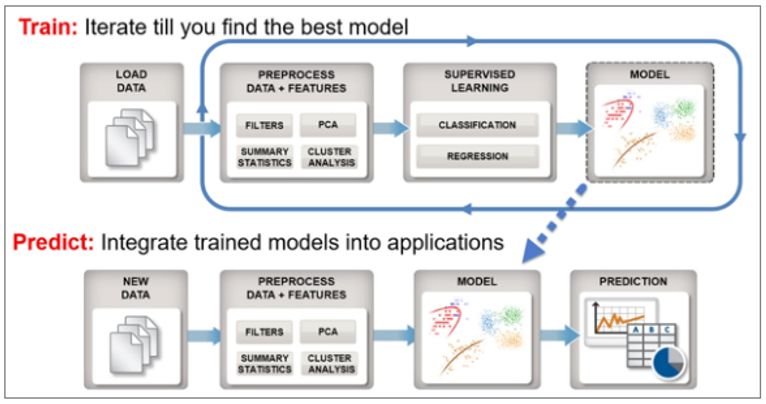
机器学习技术的表现取决于其训练所用的数据。“机器学习是一个迭代过程,”Ku 说,“机器学习算法根据输入数据有相应输出。这些输出可能不正确,所以你还必须要验证。完成之后,这些数据又被包含回数据库。这时候就该开始再训练(rertraining)了。这个循环一直持续。在某种程度上,我们希望这些迭代循环能够使得该模型相当准确,使得其在看到一个新案例时能够做出很好的预测。”
在许多案例中,数据可能来自于以前的设计,但这就够用了吗?Solido 的 Dyck 说:“想象一下,假如有 2000 个并行工作的 SPICE 模拟器要解决一个我们以前从未见过的芯片的一种从未见过的制造工艺问题。我们可以收集一些过去做法的信息并使用这些信息来塑造模型,但我们也有实时数据。这是实时机器学习以及实时构建模型。”
而实时学习还有其它很多问题。“如果流数据(streaming data)出了什么问题或者有会污染模型的错误答案,那你就需要过滤或调整它——而这是非常艰难的。”他补充说,“我们需要自动恢复和修复。当出现问题时,你必须要能够对流数据进行调试。”
但调试机器学习系统还是一个相对未知的领域。验证技术就算有,也只是寥寥无几。
涉及 EDA 流程的学习还有其它一些类型。“我们需要能通过设计实现过程获取知识,”高通高级技术总监 Sorin Dobre 说,“EDA 有一个很好的机会,可以将监督和无监督机器学习解决方案扩展用于设计流程优化(design flow optimization)。我们有20 年经验的高级工程师可以确保高质量的设计,但我们也需要帮助刚刚开始的设计师。我们没法等上五年时间才完全发挥他们的生产力。”
就算对经验丰富的设计师,这个工作也正变得越来越难。“过去,架构师根据他们的经验来设计互连(interconnect),并且根据他们的直觉来做出关于拓扑结构和布线选择的关键设计决策。” NetSpeed 的 Mohandass 说,“但是,这种方法并不适用于片上需求非常多样化的异构系统。由于多个片上器件之间交互的复杂性,要设计一种接近最优的,而且能够工作的、表现良好的、还考虑了所有用例的互连实际上是不可能的。”
数据集
Plunify 的 CEO Harnhua Ng 说:“获取一个好的数据集可能难度很大。这些工具的学习能力可以保证当工程团队使用它们越多时,学习数据库就会变得越聪明,从而加速设计完成的时间。”
所以只有那些已经有大规模数据集的人可以使用这些技术吗?或者 EDA 可以提供初始的训练吗?“对于 EDA 领域的许多机器学习应用而言,与算法相关的参数选择和训练需要完全在设计客户或代工厂的计算环境内进行。”Cadence 的杰出工程师 David White 说,“在这些应用中,最具挑战性的任务是创建自动化的训练和验证方法,使其可以确保算法在目标硅技术上按预期运行。在一些案例中,更先进和更复杂的机器学习方法可以提供更高的准确度,但要在该领域提供支持却最为困难。在开发过程中,人们需要根据所需的准确度以及可用训练数据的数量和其它支持以及模型相关的约束条件来权衡合适的算法与架构选择。”
听上去很难,实际上也正是如此。“EDA 问题有很高的维度、高阶的互动、不连续性和非线性,需要先进的实验技术设计、先进的监督学习、智能筛选和过滤以及基准基础设施(benchmarking infrastructure)。”Solido 总裁兼 CEO Amit Gupta说,“此外,EDA 问题还有很高的流数据速率和大规模的数据归档,需要优化的流解析器(streaming parser)、可并行化算法、高效和可扩展的集群管理、自动恢复和修复以及大数据调试。”
Mohandass给出了一个互连设计所需的数据集的例子。“完美的互连策略依赖于非常大量的 SoC 参数,其中包括布图(floorplan)、布线约束、可用资源、连接要求、协议层面的依赖、时钟特性、工艺特性(比如线延迟、功耗、带宽和延迟约束)等等。设计策略空间中不同维度的数量可以增至数百个,这会创造一个过大的设计空间。”
基础设施
这个问题有几个维度。Synopsys 副总裁兼 CIO Hasmukh Ranjan 说:“机器学习可以被用在 EDA 中,但为了最大化其所带来的好处,机器学习既应该被用在这些工具本身之中,也应该围绕这些工具用在设计流程之中。”
高通的 Dobre 表示同意:“没必要将所有东西都做到 EDA 工具里面。你可以用独立的机器学习解决方案来驱动已有的工具。”
IC Manage 的执行副总裁 Shiv Sikand 提供了一个例子:“通过分析之前流片(tapeout)的数十亿个数据点,我们可以预测漏洞、设计复杂度、人力资源、证书的影响,并计算当前项目服务器集群的吞吐量。通过确定半导体设计中的瓶颈,我们可以提供前瞻性预测并识别潜在的延迟。”
我们可能也需要检查我们运行工具的基础设施。“我们也需要考虑智能存储,”Sikand 补充说:“通过分析与文件操作相关的数据流,聚类和回归分析等机器学习技术可以持续改进 P2P 网络和缓存管理,以提供更好的应用性能。”
Dobre 的团队也很熟悉这些问题:“我们有包含数以万计 CPU 的计算农场。当你查看需要同时验证的设计的数量时,你该怎样以一种最优的方式来使用这些资源,而不造成资源需求爆炸?这就需要数据管理。你该怎么有效地应对在设计空间和在代工方面的这么多的数据,并提取出下一设计所需的知识和信息以减少学习周期?”
将运行该机器学习算法的机器又增加了额外的另一个维度。“机器学习将通过现有的复杂算法来减少设计和仿真的时间。” Markets and Markets 副总监 Sachin Garg 说,“EDA 工具可以采纳或采取智能决策来使其更进一步,但我们需要更好的硬件(CPU GPU)来运行如此复杂的机器学习算法,以使其更有效率。当前一代又一代的 GPU 可以为并行计算负载提供巨大的加速和出色的性能扩展。”
Cadence 的 White 同意这个说法:“在大规模并行计算架构领域的进步为基于假设的优化和验证( what-if based optimization and verification)开启了大门,从而可以有效地探索设计空间和融合最有潜力的决策。”
应用领域
成功依赖于定义正确的特征集合的能力。“以考虑工艺偏差(variation)的设计为例,”Ku 说:“如果你想建模一个概率密度函数,你需要属性(attribute)。特征(feature)是能将一种事物与另一种事物区分开的属性。对于人来说,特征可能是头发颜色、身高、性别。对于考虑工艺偏差的设计而言,特征则可能是 PVT 角、定义器件变化的算法和器件的随机变量。所以特征就是一些对一个特定问题重要的东西。”
在 10nm 和 7nm 工艺上,我们可以看到有很多工艺偏差。“代工厂提出新工艺技术的努力是很重要的。”Dobre 说,“即便这是在数字领域,也需要将库元素看作是模拟设计。你必须跨多个工艺角来对设计进行验证。你该怎样在不出现所需资源爆表的情况下实现高质量?机器学习可以将生产力提升 10 倍、减少数周的测量时间和减少资源消耗。在识别会导致产量不达标的模式上,机器学习是一种有效方法。我们看到了其中的巨大潜力,可以带来经济效益。”
EDA 正在努力解决这个问题。“对于先进节点的设计,新型的硅技术和额外的验证需求带来了更大的不确定性,从而也提升了潜在的风险。”White 说,“在传统的设计流程中,先前的设计和布局数据并不会被有效地用来帮助指导下一个设计。分析方法的进步允许我们检查(开采)之前的设计数据和趋势,并将其用于在设计流程的最早期阶段指导设计决策。这些同样的方法也可以被用于发现和提供驱动机器学习引擎的训练和开发的背景(context)。这样的解决方案很可能需要利用大量的数据和数百个机器学习组件,它们都将需要管理和验证。一旦数据被放在了适当的背景中,机器学习就可以被用于获取复杂行为提供的分析(比如寄生、电气、验证),而且准确度高、速度快。”
另外还有一些其可以提供帮助的设计领域。Hall 说:“我们可以将其用于内存或逻辑门的功率估计或时序估计。这将能减少不确定性并为人类工作提供补充,从而可以创造出更具竞争力的产品。”
另一个正在出现解决方案的领域是布线(routing)。“在互连设计的背景中,第一步是识别每一个维度中设计策略的组合,这能为之前大量不同的 SoC 设计带来优良的解决方案。” Mohandass 指出,“下一步是使用这些信息来学习模式并预测哪些策略组合将最有可能带来优良设计。”
类似的技术也可应用于 FPGA 布线。“带有复杂时序和性能封闭(performance closure)问题的复杂 FPGA 设计是基于机器学习技术的工具的良好候选项。” Plunify 的 Ng 补充说,“机器学习工具能够分析过去的编译结果,从而可在数以千万亿计的可能方案中预测出最优的综合/布局和布线参数以及布放位置。它们可以使用统计建模和机器学习来推断哪些工具参数对一种设计最优,以从数据中提取见解来提升结果的质量。”
值得信任的结果
但相对于其它机器学习应用,设计面临着更大的障碍。“最后如果一个方案存在设计过于激进或过于保守的风险,人们就不会采用这个方案。”Dyck 解释说,“机器学习工具是大型的估计器。你不能要求人们去信任它。所以我们需要能够清楚准确度的建模技术。目前这种技术还非常少——你必须发明它们。我们需要主动的学习方法,可以逐步发现相关的领域,而这些往往在最糟糕的情况旁边。要向我展示可能会导致芯片失败的地方,并且在那个区域提供清楚的洞察。这样你就要在这些区域直接进行实验。针对问题领域是很重要的。”
Dyck 还指出了 EDA 所面临的另一个障碍:“如果你不能证明一个答案是正确的,他们就不会接受它。所以你需要设计可验证的算法。你需要将验证用作该技术的一部分,这样当你给出一个答案时,你就可以说明它在运行时是正确的。”
总结
机器学习已经开始渗透进 EDA 和设计流程中了。Gupta 说:“机器学习已经开始在 EDA 领域发挥重要的作用。它还有进一步提供颠覆性技术突破来解决半导体难题的机会。”
但我们还有很长的路要走。Ku 说:“今天我们看到的只是冰山一角。我们希望未来 EDA 能停止提供数据。数据当然很好,但我们真正需要的是决策。你需要做的就是在数据和决策之间加入一层,该机器算法可以通过学习数据来了解应该做出怎样的决策。EDA 正处在进行这项工作的完美位置上。”
如果要维护信任,还需要一些小步骤。 Synopsys 的 Ranjan 总结道:“人工智能和机器学习可以成为一家公司与众不同的地方,但是使用人工智能必须不能降低算法的精确度。“
yuzhong 从竞争对手之中脱颖而出的关键,但在利用它时需要不对准确度产生损害。”
责任编辑:tzh


















 工商网监
工商网监
评论