 电子发烧友App
电子发烧友App


第三集:算法仿真
算法是对芯片系统进行的整体战略规划,决定了芯片各个模块功能定义及实现方式,指引着整个芯片设计的目标和方向。可谓,牵一发而动全身。
不管是模拟IC还是数字IC设计,算法仿真都是第一步。通常,会由算法工程师组成独立的算法团队。
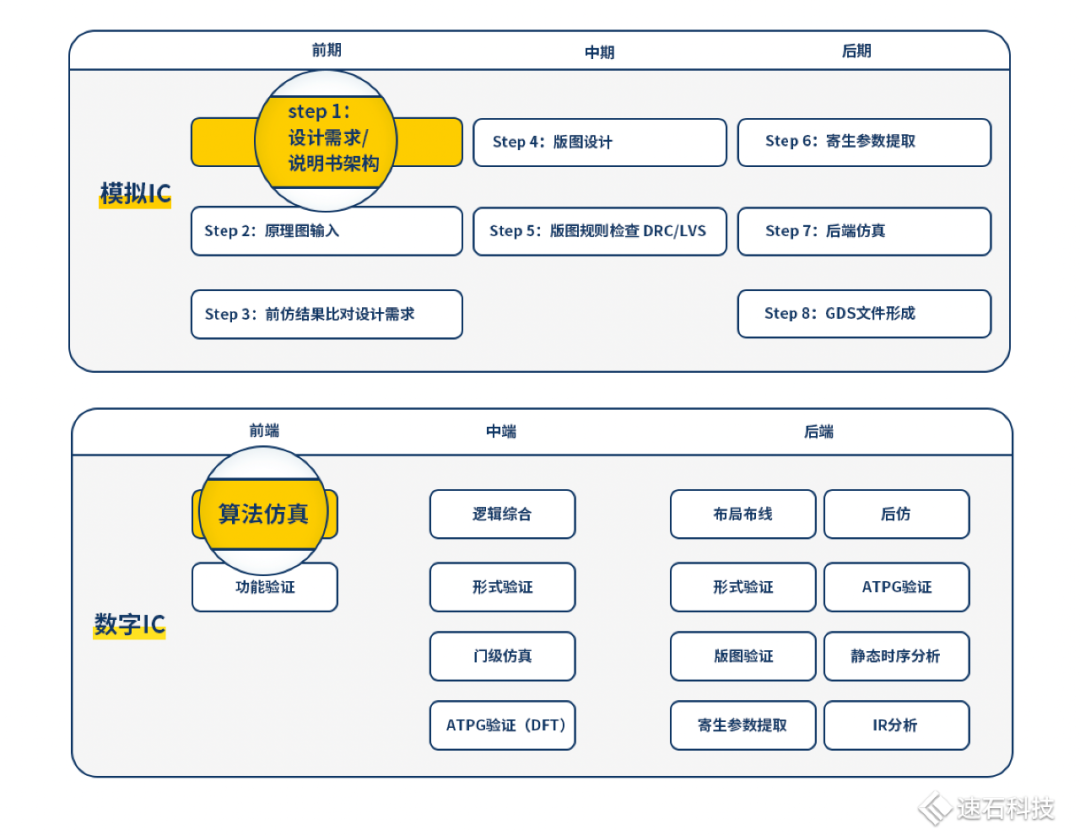
CPU/GPU本应该是算法仿真的常客,但因为历史比较悠久,发展成熟,市场几乎被英伟达和AMD垄断,很多IC设计公司选择直接采购IP的方式跳过这一步。
近几年,无线通信芯片成为了算法业务的最大甲方。因为这类芯片的信号编解码与频谱迁移时方式十分复杂,再加上种类繁多,各国的通信协议、标准、频率也在不断变化。随着我国5G通信标准的放开,算法仿真的地位与日俱进。
另一个涉及大量算法业务的场景是AI芯片,应用场景小到手机、智能家电,大至汽车。
跟前两篇数字和模拟IC的设计场景相比,算法仿真有着非常不一样的表现。
所以我们单独把ta拉出来,结合一家无线通信芯片公司实际业务场景,看看算法仿真有哪四大特性,以及从动态视角出发,看我们怎么帮算法工程师解决问题,提高研发效率。
算法仿真的本质
算法(Algorithm),是指在数学和计算机科学间,一种被定义好的、计算机可施行指示的步骤和次序。算法代表着用系统的方法描述解决问题的策略机制,解决一个问题可以有很多种算法。
举个栗子。
求解下图黄色区域图形面积,我们有三种算法。
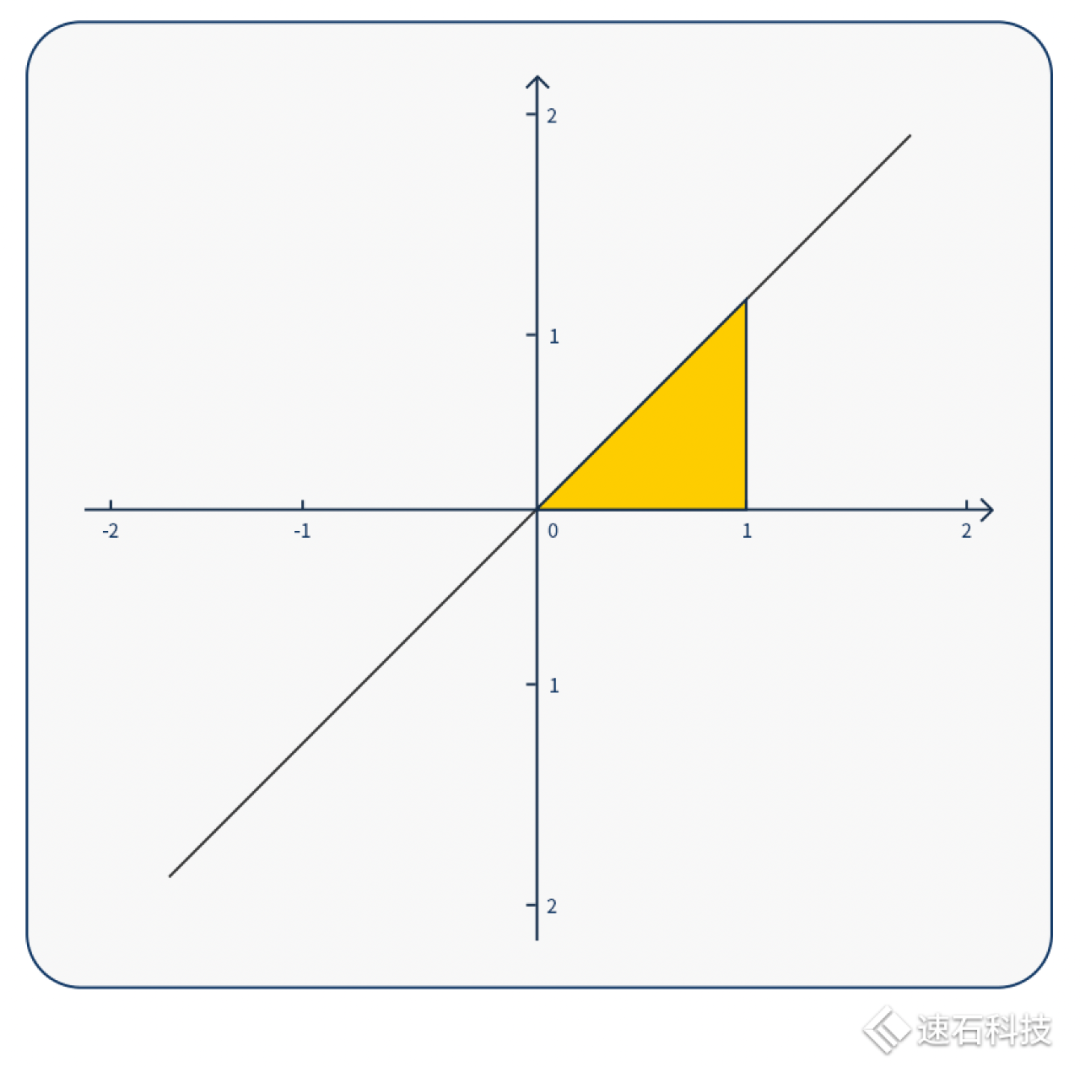
方法一:你可以直接用三角形的面积公式解。这种方法快速、直观,小学文化程度即可,但局限性也高、不通用,不适用于图像复杂的情况;
方法二:也可以用符号计算求不定积分。求解析解方法,适用于各类不定积分中有解析表达式的函数图像。计算门槛较高,大多手算,很少有计算工具。而且实际工程应用场景中,很多函数没有解析解;
方法三:用数值计算方式解积分,求数值解。数值计算法适用范围最广,可以求任意函数曲线的定积分,将函数一段段分解,再算出面积。不同的分解方法就代表不同的算法。这种方法只能求数值解,无法求解析解,且计算量巨大,适合机器计算,不适合人工计算,在工程领域应用甚广。
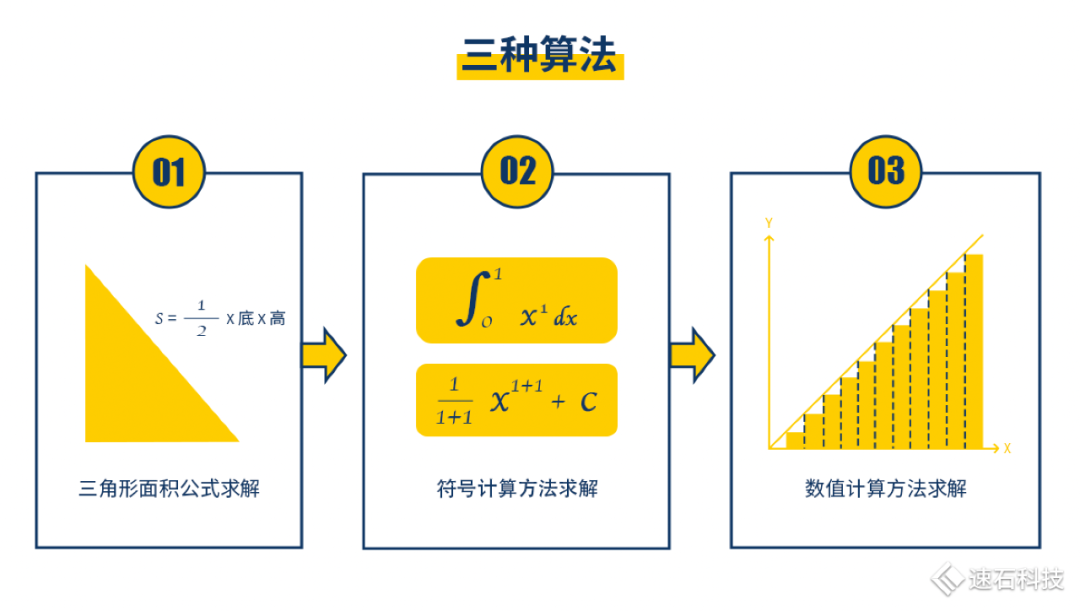
在芯片设计领域,算法仿真的本质是评估不同数值计算解法的工作量、计算效率适用范围,选出最优算法,使ta不仅要满足算得最快、最准,还要能确保功能、精度、效率、吞吐量等指标。
算法仿真是一个不断迭代、优化的过程,一般都要反复调整参数,进行N次回归测试。
一家算法团队的小目标
一家无线通信芯片公司算法团队,开局情况如下:
算法部门共有15人,全公司有480核共享本地资源,各部门按需提前申请使用。
根据公司的业务发展目标,大致估算出未来新算法项目任务总数为1283980。
假设一:全公司本地资源均归他们用,每个人的资源上限是32核;
假设二:单case运行时间为10小时;
假设三:回归测试次数为1次;
假设四:1个case只有1个job,且只用1个核。

总运行时间达到3.05年。 啊这。。 可能打开方式不对,再来: 增加假设五:人均资源上限逐渐提升到120核; 假设六:算法团队人数逐步扩张至46人;
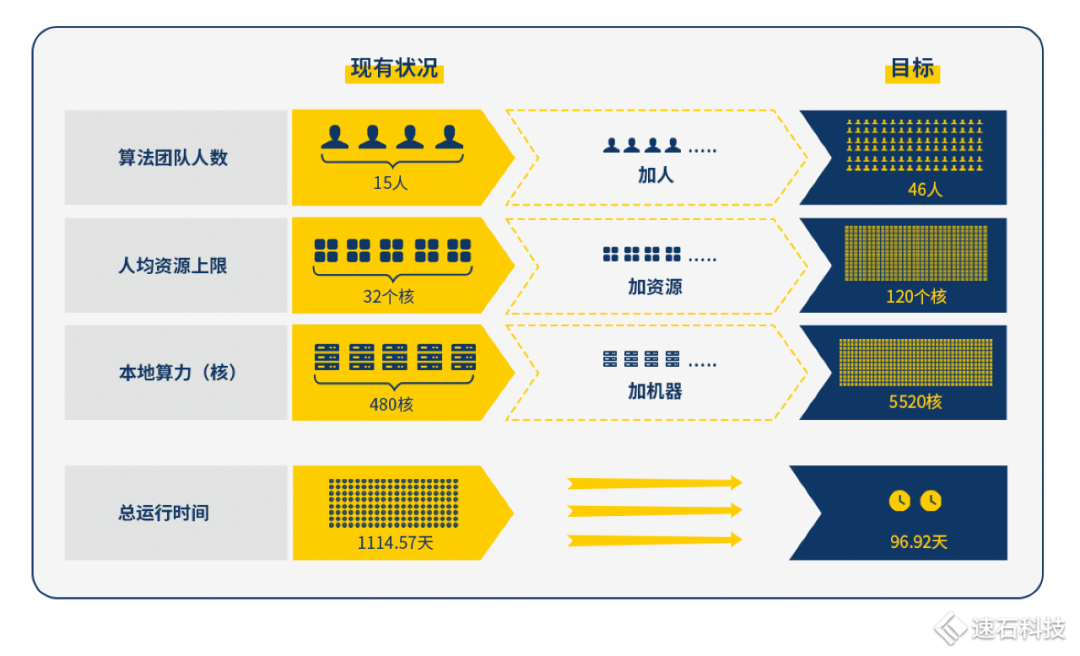
总运行时间约96.92天。
嗯,这回挺好。
想得是挺美,小目标怎么实现?
现实一:公司共享本地资源不可能只归算法部门专用;
现实二:单case运行时间,难以估计;且1个case往往不止1个job,且1个job未必只用1个核;
现实三:回归测试只有1次,几乎不太可能,总任务数可能数倍增长;
现实四:本地机房从480核要扩张十几倍,可不止是买买买硬件,机房建设、运维人力、硬件维保、存储网络、环境部署等等,都不是小事;
现实五:算法工程师要求非常高,招聘难度极大。
真是,没一个字让人爱听的。
但算法仿真这里,此路不通。
我们来看看算法仿真的特性:
算法仿真的四大特性
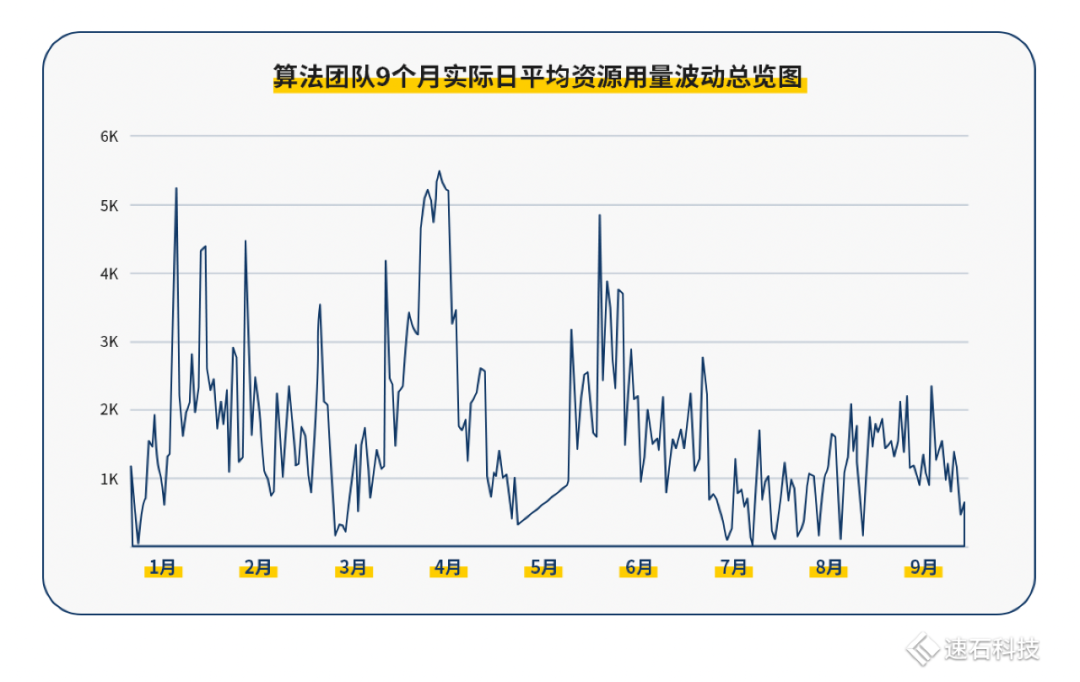
下图是这家无线通信芯片公司算法团队9个月实际日平均资源用量波动总览图:
01
需求不可测
从个人角度出发,算法团队每个人的算法任务都是互相独立,互不影响的。算法确定之后,每一轮的计算量基本确定(case分解成的job数,job占用的核数基本确定),每个算法任务的单次耗时与回归测试次数都是不一样的,这导致最后的资源需求完全不可测。
如果再叠加团队使用因素,资源的不可测性也会被成倍地放大。如果原先个人的资源使用区间是0到250核小时;如果团队内有20人,那不可测区间就放大至0至5000核小时。
02
短时间使用量波动巨大
除了算法任务需求的不可测性,资源使用量的波动还受实际算法任务的进度影响。
每个算法工程师的工作独立且进度不一,有时可能大量任务同时批量运行,也可能部分在调试,部分在运行,甚至可能一个在运行的任务都没有。
不同工程师的工作进度差异与所用算法不一,不仅导致了波峰、波谷间的资源使用量差距极大,而且这样的波动可能发生在极短时间内。
极限情况:所有工程师都在顶格跑任务,5520核的资源量瞬间拉满(100%);而下一刻只有10%的工程师在跑任务,且每人都只使用自己配额80%的资源量,那总资源仅使用了一部分。
不同公司的算法团队之间,因为团队规模与业务差异,资源用量差异也非常大。
03
资源需求类型多样
算法仿真整体来说,对资源的各方面需求并不算高。
但不同算法的需求都不一样:
有的需要单核4G内存的机型,有的要单核8G内存的机型;
有的算法对存储要求高,有的算法对存储没要求:
有的涉及图形计算,甚至还需要用到GPU机型。
04
长期可持续状态
上述三大特性,都不是突发现象,属于算法团队的日常工作状态。
这一状态的长期可持续性,我们需要对此做好足够的准备。
一种动态思路:增加时间维度
算法仿真的四大特性决定了:按这家公司原来的静态处理方式,也就是把任务量当成恒定的,通过加人加机器的方式来满足研发需求,变得很不现实。哪怕顶格准备资源,资源利用率也会长期处于较低状态。
那按动态处理方式,也就是随着时间变化,灵活根据需求匹配不同规模/类型资源的方式来动态满足研发需求,从个人及团队视角出发,看我们怎么帮算法工程师解决问题,提高研发效率。
01
算法工程师视角
1)资源无需申请,即开即用 再也不用跟同事抢资源或者漫长的排队等待了,也不用走繁琐的资源申请流程。 2)资源选择空间变大 选择空间变大,资源类型变多,可用资源上限变高,可以灵活选择更加适配算法任务的资源类型。 3)提交任务立马就能跑,告别等待 提交任务立马就能跑,一整套研发环境现成的,即开即用。 灵活切换,今天跑一百,明天跑一万,无需等待环境配置。 4)以前怎么用,现在就怎么用 跟本地相比无感知,用户使用习惯没有任何改变,不需要调整任何脚本。 5)任务跑得快,效率线性增长 多case高并发执行。同一批算法任务之间互相独立,可以做到效率线性提升。
02
团队管理视角
1)动态方式解决资源不可测问题 算法任务的不可预测且波动巨大,导致了资源预测与规划基本不可能。 按传统静态处理方式来解决问题: 按顶格规划,这笔账都不用算,会造成黄色区域的巨大浪费; 按中间取值准备,当某个时间点算法仿真短时间内任务量激增,就会出现人机不匹配,不是有人力没机器,就是有机器没人力。这种错配导致资源利用率极低,影响研发进度。
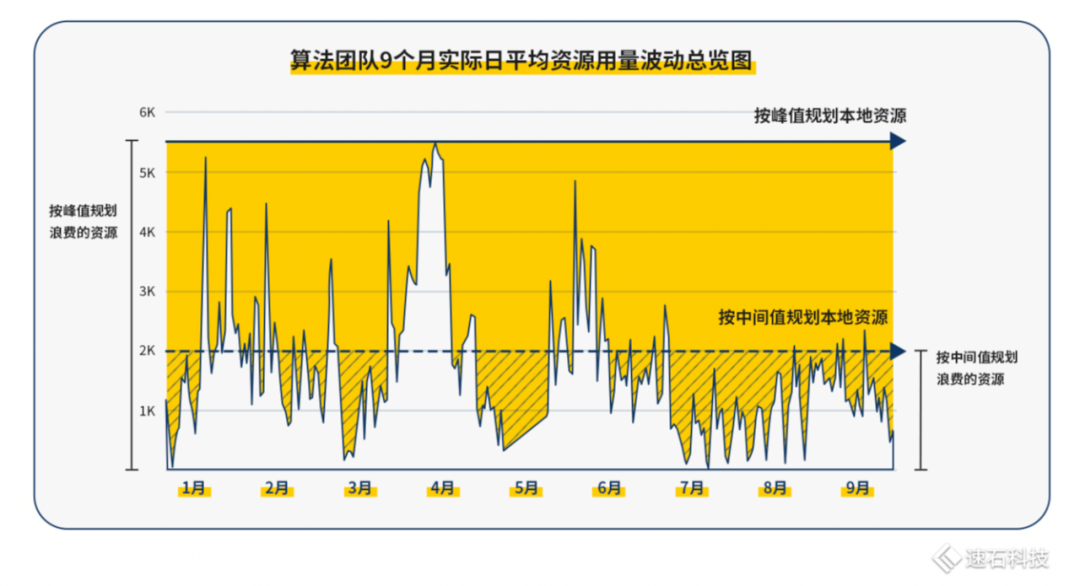
图中3-5月,峰值算力就从200核攀升27倍达到5520核,随即又迅速从5520核下跌到500核左右,这波动幅度简直比过山车还剧烈,而且毫无规律。 我们的动态处理方式,会随着时间变化,灵活根据当前时间点任务需求匹配不同规模/类型资源的方式,动态满足研发需求。 不管500核还是5000核,我们都能实时根据需要,满足整个团队的大幅波动资源需求,保障日常算力和峰值算力任务调度效率。 2)Auto-Scale自动伸缩,随用随关不浪费 Fsched调度器的Auto-Scale功能,能解决团队资源利用率与成本问题。资源“自由”的同时不浪费。 一方面随用户任务需求,设置自动伸缩上下限,自动化调用资源完成任务; Auto-Scale功能可以根据任务运算情况动态开启云端资源,需要多少开多少,并在任务完成后自动关闭,让资源的使用紧随着用户的需求自动扩张及缩小,最大程度匹配任务需求。
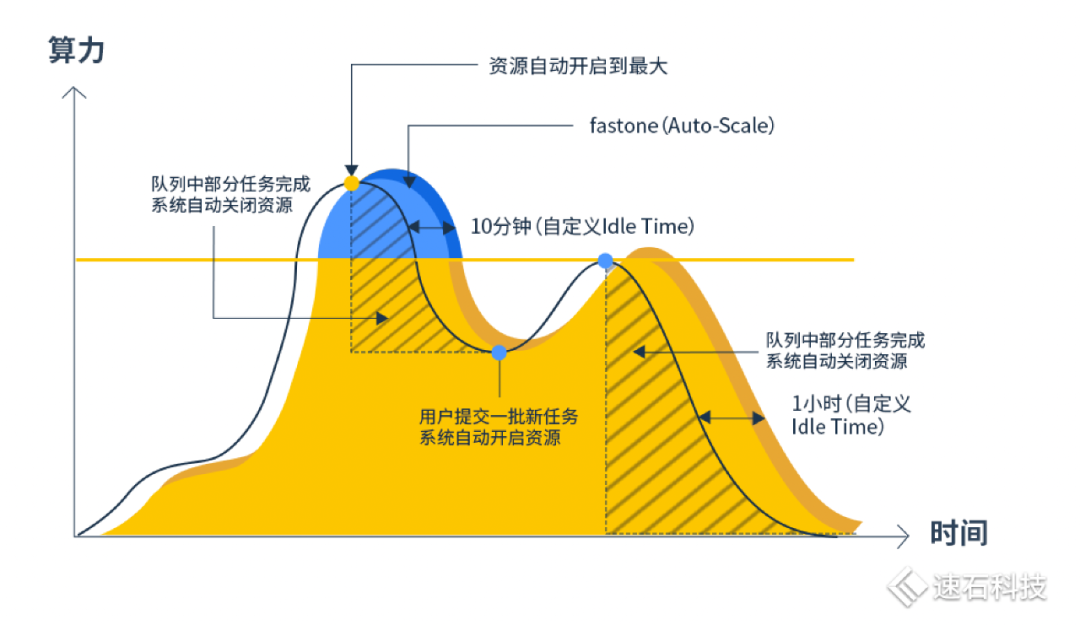
这既节约了用户成本,不需要时刻保持开机,也最大限度保证了任务最大效率运行。中间也不需要用户干预,手动操作。
另一方面我们还能监控用户提交的任务数量和资源需求,在团队内部进行资源及时适配,解决错配问题。 3)提升团队整体运营效率 我们的运营数据dashboard能让团队管理者监控各个重要指标变化,从全局角度掌握项目的整体任务及资源情况,为未来项目合理规划、集群生命周期管理、成本优化提供支持。 还能根据不同成员或小组的业务紧迫程度和业务重要性,合理分配与控制用户使用资源。 4)全球数据中心解决资源瓶颈 我们的全球数据中心,能持续稳定地提供用户所需资源类型及数量,分钟级调度开启上万核计算资源,满足业务紧迫度。 用户可以选择自主选择大内存、高主频等多样化的资源类型来满足不同算法需求。一旦发现所选资源类型与算法任务不匹配,还可随时中止任务、更换资源类型,任务进度不受影响。
编辑:黄飞












 工商网监
工商网监
评论