 电子发烧友App
电子发烧友App


互联网时期,大数据的概念便被提出来。但在大部分人看来,大数据就如同“乌托邦”一样,是渴望创新的人打造的假想国。当在这前面加上区块链,这一切看来似乎就更虚无缥缈。
但实际上,大数据的产业价值已经影响到人们生活的方方面面。区块链+大数据两种看似牛马不相及的技术,却在解决数据分散、非对称持有方面有着更多价值,可以更好实现互联网信息的互联互通。
随着区块链发展至今,这一结合到底是科技进步还是痴人说梦?关于区块链+大数据背后的技术研究,大众又知几何?
OK区块链联合OKLink技术副总裁梁福坤,他从区块链浏览器这一方向入手,阐述了区块链和大数据的可结合之处以及区块链技术与传统互联网技术的不同之处,希望能对读者有所启发。
目前来说,OKLink区块链浏览器聚焦定位三大技术方向:区块链、大数据和人工智能(AI方向),三者之间紧密协作,打造区块链数据门户的整体生态。
下面阐述三大技术在浏览器中的位置和作用,以及面临的架构技术挑战。
1. 区块链技术
区块链角色更多关注全节点作为数据源提供方,依赖区块链技术的分布式、公开透明、可追溯、不可篡改等特征,同时结合数据分布式存储、点对点传输、共识机制、加密算法等多种技术融合形成的区块链创新应用模式。
在区块链浏览器的整体架构中,区块链作为数据源存在的挑战与传统大数据进行ETL(Extract-Transform-Load)比较。
多币种主链数据组织差异大,在众多主链数据持有能力上,需要思考如何在系统架构上提出能够保证通用结构复用,又要兼顾多主链个性化灵活支持的需求。同时,理解区块链全节点数据的业务特征、不同版本之间差异、分叉对不同高度的解析细节上在研发周期中占用较大比重。
以往大数据架构不需要太多的关注数据业务本身涵义,更多聚焦在数据流转、计算、存储,而区块链则需要对业务了解放在首位,起点较高。
2. 大数据技术
在OKLink区块链浏览器上,大数据聚焦在区块链数据源解析之后,推送到Kafka消息队列后续,对数据进行统计分析,实时计算和离线计算部分。
同时,在浏览器前端展示ToC提供线上检索服务和对不同的数据应用放提供ToB(面向商业)的API访问方式。
当然,区块链浏览器中大数据的实践和传统互联网大数据有着较为明显区分特征,下面逐一说明:
A) 数据中台
区块链大数据更加侧重数据中台的角色,而不是传统的后台提供数据分析、离线计算的位置。之所以在数据中台委以重任,是需要更快、更为灵活的交付用户数据。
所以查询快是OKLink的一大亮点,要提供区块链数据的快速交付,需要在数据解析到流转、计算存储、查询4个方面整个链路做全方面的优化,整体协作来完成快速交付。
时效性在区块链对ToB方面至关重要,ms级别的先机会对类似量化交易及时做出预判,类似传统意义提到的时间就是金钱,唯快不破。
B) 数据弱化分区特征
在互联网等传统大数据进行存储,一般会对数据按照日期进行一级分区,对于数据进行分布式存储和计算在MPP架构中应用非常娴熟,数据可以根据使用情况做热数据、温数据、冷数据处理分层Cache、归档等处理。
而区块链大数据存储在业务层面需要时刻准备交付,即数据可以理解均为热点数据,例如按照地址检索交易记录,即便较久交易也需要实时交付。
同时,时间维度在做区块链的业务场景应用中不重要,反而区块高度、交易Hash、地址等维度命中率在大部分场景下有较多应用。
在架构层面,满足弱化分区特征,需要实现索引和数据的异构引擎配合存储和计算,在服务层面需要做到数据一致性、检索过程业务透明、新增索引项灵活配置、热部署等工程方面挑战。
C) 流批处理
流批处理指的是区块链计算指标需要结合历史的统计信息和当前的实时数据做更新,例如地址的累计交易金额=历史累计交易金额+当前交易金额。
前面提到如果大数据处于后台角色,可以完全通过离线计算批处理的方式进行统计,这样的方式即保证了准确性,又相对保险,但在时间上会有滞后。而作为数据中台能快速准确交付用户信息,这里需要历史聚合数据和当前变更数据做实时计算。
这种场景最大的挑战是数据指标的冷启动+实时计算结合,并且一个指标从定义到交付更为灵活,就需要在架构设计上支持配置化的指标定义,而非Case by Case的定制开发。
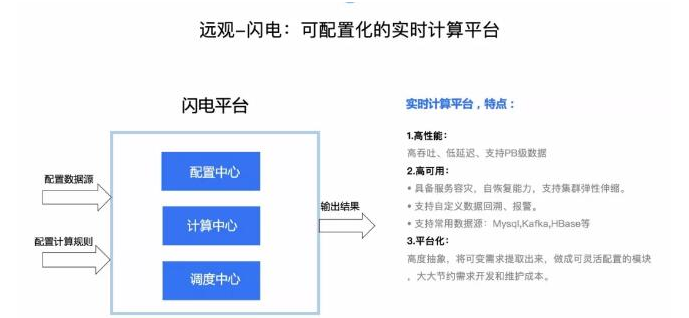
OKLink实时计算平台“闪电”中采用Flink作为流批数据计算的架构选型,支持灵活定义Source数据源、ETL数据上下游衔接和灵活定义Sink输出。在存储方面借助HBase存储满足实时更新和按照Key检索,历史聚合信息计算结果存储在HBase,并且记录历史截止交易高度,闪电平台敏锐察觉数据变更并且延续后续实时计算过程。
D) 数据补偿机制
即当线上数据出现问题之后,如何能够快速修正数据。一般来说,数据出现问题的原因包括:计算逻辑变更、数据解析bug、区块分叉、数据延迟交付等因素。
这些因素虽然在浏览器上线后出现的频率较低,但是每次出现人工处理成本较高,主要表现在处理时间、人工核验的质量参差不齐。
数据补偿机制是数据质量保证重要的途径,可以满足数据的最终一致性需求。数据补偿的处理步骤可以归纳为识别坏数据、定位数据源、清理目标写入、数据重计算四个部分,因为针对不同的数据源处理步骤大同小异,所以非常适合工程化方案解决。
当前这里面也存在一些挑战,比如坏数据出现位置监控与定位、已写入引擎数据识别和清楚、修正补丁(Patch)热部署热加载避免停服、旁路数据修正等。
E) 新数据频繁变更
数据变更在互联网场景更多体现在OLTP数据库中,而在OLAP场景下更多为沉淀数据,追加较多变更非常少。
频繁变更带来的问题是数据碎片化严重、标记删除和定期归档工程化较为复杂,目标存储引擎支持更新,同时如果支持幂等性业务操作,还需要识别已写入数据哪些是覆盖想,哪些是删除项。
3. 人工智能技术
人工智能(AI)技术在区块链浏览器场景下,落地存在较多场景。从公开、透明、不可篡改的数据中,发现数据背后更多的价值挖掘,例如地址画像、量化交易都是从已有区块数据中发现相关性。
AI技术和区块链技术均存在擅长的发挥领域,但是也避免不了有各自的短板,而取长补短融合才能发挥更大的空间。
区块链数据去中心化和分布式存储给AI带来公开透明的大数据生态市场、更加丰富AI的数据特征工程、模型与算法提升。同时,把AI技术应用到区块链,可以让区块链智能合约、工作量证明、自治组织等更加智能、高效、安全、未来精准评估。
首先在数据公开对称层面,区块链数据不像传统大数据掌握在BAT等大公司手中,相对数据使用者是对等的关系。
因为区块链数据对使用者更加开放和对等的信息公开性,基于区块链数据的应用在数据层面让使用者站在同一个起点和基础。而人工智能的核心算法层、模型层面,更为适应业务需求开展深度发挥,在数据应用层面百花齐放。
其次是合作共赢方面,因为是相同数据样本产出的结果,后期产业融合、成果融合方面更为开放和流畅。
这其中代表性的例子类似地址的标签画像,不同的应用放可以针对标签构建特征工程和描绘,最后成果可以根据地址的ID-Mapping可以实现融合共享。
类似业界安全方面比较注重的黑产地址、博彩地址、富豪地址、矿池和交易所地址的多角度识别,未来AI、区块链技术在相互调用、促进方面会有更多想象空间等待发现。











 工商网监
工商网监
评论