 电子发烧友App
电子发烧友App


在上一篇关于以太坊1.x的文章中,我们对Eth 1.x研究的起源、利害因素以及一些可能的解决方案做了简要回顾。在上篇文章的结尾我们提到了“无状态”以太坊的概念,而在本文中我们将进一步详细阐释无状态客户端。
无状态(stateless)是Eth 1.x研究的新方向,因此我们将进行一次相对深入的探析,以便对未来可能面临的挑战和可能性了然于胸。如果读者有兴趣进一步了解,我会尽量提供相关资源的链接。
什么是“状态”?
要解释无状态以太坊,我们首先需要理解“状态”(state)的概念。当我们提到“状态”时,一般是指“事务的状态”。
以太坊的完整“状态”描述了所有账户和余额的当前状态,以及在EVM中部署和运行的所有智能合约的集体历史。链上每个最终确定的区块,都有且只有一个状态,这是由网络中的所有参与者共同确认的。每当有新的区块被添加到链上,状态都会随之改变且更新。
在Eth 1.x研究语境中,我们不仅要知道状态是什么,还要知道它在协议(据黄皮书中的定义)和大多数客户端实现(如geth、parity、trinity、besu等)中是如何表现的。
什么是Trie?
以太坊所使用的数据结构叫作Merkle Patricia Trie。有趣的是,‘Trie’最初截取自‘retrieval’一词,但大多数人会将其发音为‘try’,以区别于‘tree’。回到正题,关于MPT数据结构,我们需要了解:
在trie的一端,是描述状态(值节点)的所有特定数据片段。数据可以是特定帐户的余额,也可以是存储在智能合约中的变量(例如某种ERC-20通证的总供应量)。Trie的中间则是分支节点,通过哈希运算将所有值串联在一起。分支节点是包含其子节点哈希的数组(array),每个分支节点随后再次经过哈希并归入其父节点的数组中。这一连串的哈希最终会到达trie另一端的一个状态根节点。
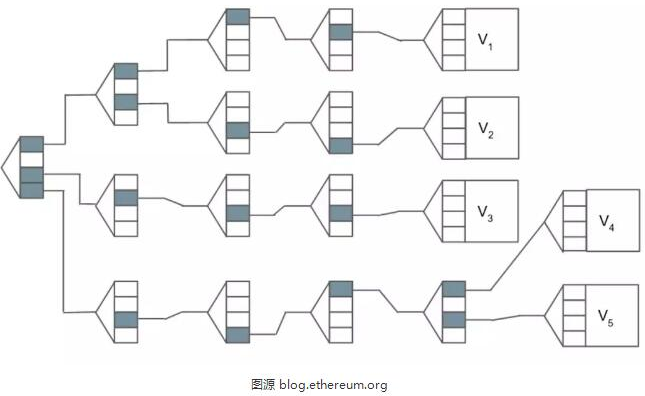
在上面的简化图示中,我们可以看到一些数值,以及得到这些值的路径。例如,为了得到V-2,我们经历了1,3,3,4的路径。同理,V-3可通过路径3,2,3,3来获取。需要注意的是,本例中的路径长度始终为4个字符,并且要获取某个值只有一条可用路径。
该结构具有确定性和可加密验证的重要特性:生成状态根的唯一方法就是通过计算状态的每个单独数据段,如此一来,通过比对根哈希和前序哈希(Merkle证明),就可以轻松证明两个状态是相同的。反之,我们也不能用相同的根哈希创建两个不同的状态,任何使用不同值修改状态的尝试都将导致不同的状态根哈希。
以太坊通过引入新节点类型,扩展节点(extension nodes)和叶节点(leaf nodes)来提升效率,优化trie结构。通过将路径的一些部分编码为节点,如此一来trie就会更加紧凑。

在这种优化后的MPT结构中,每个节点都需要在多个后续节点共享的路径压缩部分或值(若有必要,由路径的其他部分前缀)之间进行选择。其实是相同的数据和组织,但是这个trie结构只需要9个节点而非18个节点。看起来似乎更有效率,但事后看来,实际上这并不是最理想的。我们将在下一节讨论原因。
要获取状态的特定部分(例如账户当前的ETH余额),需要从状态根开始,沿着trie的路径从一个节点到另一个节点,直到达到所需的值。在每个节点上,路径中的字符用来决定下一个目的节点,就像是一个用于导航哈希数据结构的探测棒。
而在以太坊真正使用的版本中,路径是长度为64个字符(256位)的地址哈希,值是RLP编码数据[1]。分支节点是包含17个元素的数组(其中有16个是每个可能的十六进制字符,剩余一个则为值),而叶节点和扩展节点包含2个元素(一个是部分路径,另一个是下一个子节点的值或哈希)。要了解更多细节,可以浏览以太坊的wiki页面[2],或者,如果你喜欢亲自钻研,那么这篇文章提供了一个很棒的Python DIY trie练习[3](不幸的是这篇文章已经过时了)。
在数据库中使用Trie
读到这里我们应该提醒自己,trie结构只是一个抽象的概念。这是一种将以太坊状态的整体打包成统一结构的方法。该结构需要在客户端的代码中实现,并存储在磁盘上(或者分布在全球的数千个磁盘中)。这意味着要采用多维trie结构并将其嵌入到一个普通的只理解[key,value]对的数据库中。
在大多数以太坊客户端(turbo-geth除外)中,MPT是通过为每个节点创建不同的[key, value]对来实现的,其中value是节点本身,key是该节点的哈希。

因此穿越trie的过程,或多或少与之前描述的理论上的过程相同。要查找帐户余额,我们将从根哈希开始,并在数据库中查找其值以获取第一个分支节点;使用哈希地址的第一个字符,可以找到第一个节点的哈希;在数据库中查找哈希,然后得到第二个节点;使用哈希地址的下一个字符,我们可以找到第三个节点的哈希。如果运气好的话,我们沿途可能会碰到一个扩展节点或叶节点,也就不需要检查全部的64个半字节。无论如何,我们最后会找到所需的帐户,并从数据库中检索其余额。
这个过程与计算每个新区块的哈希在很大程度上是相似的,但是是反过来的:从所有边缘节点(账户)开始,通过连续的哈希来构建trie,直到最后一个新的根哈希,再与链中最新确认的区块进行比较。
这就是状态trie明显的效率优势所能够施展的地方:在磁盘上重构整个trie的强度是非常大的,以太坊使用的优化版MPT结构通过折衷实现效率来提高协议效率。
这些额外的节点类型(叶节点和扩展节点)理论上节省了存储trie所需的内存,但它们会使得用于修改常规数据库中状态的算法更加复杂。不过一台功能强大的计算机设备能够极速执行该过程。然而,纯粹的处理能力也只能起这么大的效用了。
节点同步
到目前为止,我们的讨论还局限在运行以太坊客户端(如geth)的个体计算机范围中。而以太坊是一个网络,所有这一切的关键是要在全球数千台计算机以及不同客户端之间达到统一的状态共识。
不断洗牌的#Defi、cryptokitty拍卖或cheeze巫师大战的token,以及常规的ETH交易都会碰撞在一起,给以太坊客户端创建一个极速变化的状态。而以太坊客户端需要保持状态同步,随着以太坊越来越广泛的应用,同步状态就会愈难,状态trie的结构也会愈深。
“Turbo-geth是抽薪止沸的一种实现:其将trie数据库扁平化,并使用节点的路径(而非其哈希)作为[key, value]对。这有效地使得检索操作无关树的深度,并带来了各种酷炫的功能,使得运行全节点时性能提升且减少磁盘负载。”
以太坊的状态非常大,并且随每一个区块而变化。那么状态和改变究竟有多大?我们可以将整个以太坊的当前状态大致定位在状态trie的约4亿个节点上。其中,大约每15秒需要添加或修改约3000个(甚至多达6000个)节点。与以太坊区块链保持同步,实质上就是不断有效地构建新的状态trie。
“这种状态trie数据库操作的多步骤过程,正是以太坊客户端占用如此庞大的磁盘I/O和内存的原因,即便是“快速同步”(fast sync)模式可能也需要长达6个多小时才能完成。而要运行一个以太坊全节点,快速SSD(而非便宜但可靠的HDD)必不可少,因为处理状态更改对磁盘读/写的要求非常高。”
其中需要注意的关键点在于,建立一个新节点进行同步,与保持现有节点同步,这两者之间相去甚远。而当我们实现无状态以太坊之后,它们之间的区别将会模糊化(希望如此)。
最直接的同步节点的方法是使用“full sync”(完全同步)方式:从创始区块开始,将每个区块中的每笔交易恢复成列表,并构建状态trie。后续区块一旦产生,状态trie就会被修改,随着区块链完整历史的重现对节点进行添加或修改。而从创世区块开始下载并执行每个区块的状态更改,需要花费整整一个星期的时间。如果你同步时不亟待进行新的交易,那就只是时间问题。
另一种同步方式“fast-sync”(快速同步)名副其实,其同步速度更快,但也更复杂:新客户端可以从最近受信任的“检查点”(checkpoint)区块请求状态条目,而不再需要从创世区块开始。该方式需要下载的信息量要少得多,但仍然有许多信息需要处理。快速同步目前不受带宽限制,而是受磁盘性能的限制。
实质上,进行快速同步的节点是在与链的末端进行赛跑。节点需要在状态陈腐(stale)并且全节点不再提供该状态之前从“检查点”(checkpoint)中获取所有状态(如果发生这种情况,节点可以辗转至新的检查点)。一旦快速同步节点克服了这种障碍,并使其状态完全与检查点(checkpoint)同步,就可以切换为完全同步,即从每个区块中包含的交易生成并更新自己的状态副本。
什么是区块见证(witness)?
讲到这里,我们可以开始探索无状态以太坊的概念。无状态以太坊的主要目标之一就是减少新节点同步过程的痛苦。考虑到只有0.1%的状态是随区块变化的,所以似乎应该有一种方式可以减少切换为完全同步之前需要下载的所有额外信息。
但这也是以太坊采用加密安全数据结构所带来的挑战之一:在trie结构中,仅更改一个值就会导致全然不同的根哈希。这是一种特性,不是漏洞。这使得每个人都能确保自己和网络中的其他节点处于同一状态。
如果要走捷径的话,我们需要一条关于状态的新信息:即区块见证(block witness)。假设此trie结构中只有一个值最近产生了改变(下图绿色部分):

同步状态(包括该笔交易)的全节点将采用传统的方式:获取所有状态片段,并对它们全部进行哈希运算,以创建新的根哈希。如此就可以轻松验证自己的状态是否与其他所有人的状态相同(因为节点掌握了相同的哈希以及相同的交易历史)。
那对于新加入进来的节点呢?新节点要进行验证所需的最小信息量是多少,以保证至少在其观察时段内的观察结果与其它节点是一致的?
一个新的节点需要更早的全节点提供证明,证明所观测到的交易符合迄今为止的状态。

用抽象的术语来说,一个区块见证(witness)证明提供了状态trie中所有丢失的哈希,并结合了一些位置“结构”信息,表示这些哈希在状态trie中位于何处。这使得新节点能够将新交易包含在其状态中,并在本地计算新的根哈希,而不需要下载状态trie的完整副本。
简言之,这就是beam同步( beam sync)[4]蕴含的原理。Beam同步方案不再收集检查点trie中的每个节点,而是开始监测并尝试在交易发生时就执行交易,从全节点请求每个区块的见证(witness)内容,以获取没有掌握的信息。随着越来越多的状态被新交易影响,通过beam同步逐渐填充信息,直到最终切换到完全同步,客户端可以更信任自己的状态副本。
不同程度的“无状态”
随着区块见证(witness)的引入,“完全无状态”概念的定义逐渐清晰。与此同时,这也是我们开始遇到瓶颈和问题的地方,并且没有明显可行的解决方案。
与beam同步方案不同,真正的无状态客户端自始至终不会保留状态副本,而是只与区块见证(witness)一同获取最新的交易,只需要包含执行下一个区块所需的一切信息。
所以我们几乎可以预见如果整个网络都是无状态的,那么实际上是可以达到永动状态的。新区块的见证从上一个区块产生,然后依次传递见证!至少可以持续到最后确认的“事务状态”,以及该状态产生的第一个见证。而这对于以太坊来说将是一个富有戏剧性的巨变,所以不太可能会获得广泛的支持。
有一种不那么激进的方法:适应不同程度的“无状态”。在这种网络中,会有一些节点保存完整的状态副本,也能为其它所有节点提供最新的见证(witness)。
· 完整状态节点会像往常一样工作,但需要额外计算一个见证(witness)并将其添加到新区块,或通过辅助网络子协议广播;
· 部分状态节点可以只在少量区块生成期间保留完整的状态,或者只“监测”其相关的状态部分,然后从见证中获取验证区块所需的其余数据。这对需要运行基础设施的DApp开发者而言大有裨益;
· 根据定义,零状态节点想要在运行客户端时尽可能轻巧,可以完全依赖区块见证来验证新的区块。
要启用这个方案,可能需要类似于bittorrent采用的分块(chunking)和群集(swarming)行为,其中见证(witness)片段根据其需要进行广播,并与具有(互补)部分状态的其他节点建立最佳连接。或者,这可能需要制定一个状态trie的替代实现方案,使得更适宜见证(witness)的生成。这都是我们需要研究和实验的内容!
如若想要更深入地探析状态节点与无状态节点之间的权衡,可参见Alexey Akhunov的《The shades of statefulness》[5]。
这种半-无状态方式的一个重要特点在于这些改变不一定要诉诸硬分叉形式。通过微小的并且可测试的渐进方式,就可以将以太坊的无状态组件构建成一个辅助型子协议,或者划分为一系列不具争议的EIPs,而无需进行大型“信念飞跃式”的升级。
无状态客户端路线图
我们在研究中遇到的一个明显问题就是区块见证(witness)的大小。普通区块包含一个区块头和交易列表,其大小约为100 kB。相对于网络延迟及15秒的区块时间,这种大小可以使得区块广播速度较快。
然而,见证(witness)需要包含状态trie的边缘和深层节点的哈希。这意味着其大小要大得多:早期数据显示大约为1 MB。因此,与网络延迟和区块时间相比,同步见证要慢得多,这可能会是一个障碍。
这种两难境地类似于电影下载和流媒体之间的区别:如果网络过慢导致流媒体无法顺畅加载,那么下载完整电影就是唯一可行的选择。如果网络速度快,那就可以流畅播放电影。如果实际情况是网络速度不上不下,那么我们就需要更多的数据来作出决定。那些标准之下的互联网服务提供商,会在需求过高时认识到低速网络的局限性。
很大程度上,这就是Eth 1.x工作组正在着手解决的为具体问题。目前,我们对假想见证网络的了解,还不足以确定其是否能正常或理想运行,难点就在于细节(以及数据)。
一种方法是通过改变trie本身的结构(如二进制trie),考虑如何压缩和减少见证(witness)数量,以使其在实现时更高效。另一种方法则是原型化网络原语(例如bittorrent的swarming),使得见证能够有效地在网络中不同节点之间传递。而这两个方案,都能受益于形式化见证规范(目前该规范还不存在)。
责任编辑;zl











































 工商网监
工商网监
评论