 电子发烧友App
电子发烧友App


当与区块链数据集一起使用时,机器学习模型往往会过度拟合。什么是过度拟合,如何解决?
使用机器学习来分析区块链数据集的想法乍一看非常吸引人,但它充满了挑战。在这些挑战中,缺少标记的数据集仍然是应用机器学习方法到区块链数据集时需要克服的最大困难。
这些限制导致许多机器学习模型使用非常小的数据样本进行训练和过度优化,从而导致一种称为过度拟合的现象。今天,我想深入探讨一下区块链分析中的过度拟合问题,并提出一些解决方法。
过度拟合被认为是现代深度学习应用中最大的挑战之一。从概念上讲,当模型生成的假设过于针对特定数据集而导致无法适应新数据集时,就会发生过度拟合。
理解过度拟合的一个有用的类比是将其视为模型中的幻觉。本质上,当一个模型从数据集中推断出不正确的假设时,它就会产生幻觉/过度拟合。
自从早期的机器学习以来,已经有很多关于过度拟合的文章,所以我不认为有任何聪明的方法来解释它。在区块链数据集的情况下,过度拟合是缺乏标记数据的直接结果。区块链是大型的、半匿名的数据结构,在这种结构中,所有东西都用一组公共结构表示,比如交易、地址和区块。
从这个角度来看,区块链记录的限定信息是最少的。是交易、转账还是付款?是个人投资者的钱包还是交易所的冷钱包?这些限定词对于机器学习模型是必不可少的。
假设我们正在创建一个模型来检测一组区块链中的交换地址。这个过程需要我们使用现有的区块链地址数据集来训练模型,我们都知道这些数据集并不常见。如果我们使用EtherScan或其他来源的小数据集,模型可能会过度拟合并做出错误的分类。
使过度拟合如此具有挑战性的一个方面是,很难在不同的深度学习技术中推广。卷积神经网络倾向于形成与递归神经网络不同的过拟合模式,而递归神经网络又不同于生成模式,这种模式可以外推到任何类型的深度学习模型。
具有讽刺意味的是,过度拟合的倾向与深度学习模型的计算能力成线性关系。由于深度学习代理可以生成复杂的假设,而且几乎不需要任何成本,因此过度拟合的倾向就会增加。在机器学习模型中,过度拟合是一个持续的挑战,但在处理区块链数据集时,它几乎是一个给定的问题。解决过度拟合的明显方法是使用更大的训练数据集,但这并不总是可行的。在IntoTheBlock,我们经常遇到过度拟合的挑战。
在区块链数据集中对抗过度拟合的三个简单策略
与过度拟合作斗争的首要原则是认识到它。虽然没有防止过度拟合的灵丹妙药,但实践经验表明,一些简单的、几乎是常识的规则有助于在深度学习应用中防止这种现象。
在已经发布的防止过度拟合的几十个最佳实践中,有三个基本的思想包含了其中的大多数。
数据/假设比率
过度拟合通常发生在一个模型产生了太多的假设而没有相应的数据来验证它们的时候。因此,深度学习应用程序应该尝试在测试数据集和应该评估的假设之间保持适当的比例。然而,这并不总是一个选择。
有许多深度学习算法,如归纳学习,依赖于不断产生新的,有时更复杂的假设。在这些场景中,有一些统计技术可以帮助估计正确的假设数量,从而优化找到接近正确的假设的机会。
虽然这种方法不能提供准确的答案,但它有助于保持假设数量和数据集组成之间的统计平衡。哈佛大学教授莱斯利·瓦兰特在他的书中精采地解释了这一概念。
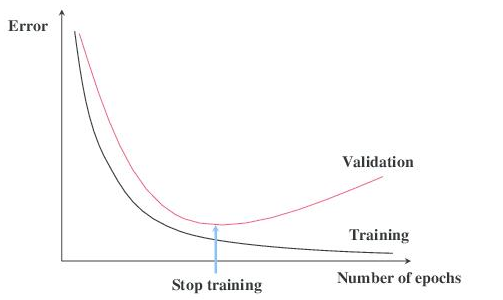
当进行区块链分析时,数据/假设的比例非常明显。假设我们正在构建一个基于一年区块链交易的预测算法。
因为我们不确定要测试哪个机器学习模型,所以我们使用神经架构搜索(NAS)方法,该方法针对区块链数据集测试数百个模型。
考虑到数据集只包含一年的交易,NAS方法可能会生成一个完全适合训练数据集的模型。
支持简单的假设
在深度学习模型中,防止过度拟合的一个概念上琐碎但技术上困难的想法是不断生成更简单的假设。当然!简单总是更好的,不是吗?
但在深度学习算法的背景下,有什么更简单的假设呢?如果我们需要将其归结为一个量化的因素,我会说深度学习假设中属性的数量与复杂度成正比。
简单的假设往往比其他有大量属性的假设更容易评估,无论是在计算上还是在认知上。
因此,与复杂的模型相比,简单的模型通常不太容易过度拟合。下一个明显的难题是如何在深度学习模型中生成更简单的假设。
一种不太明显的技术是根据算法的估计复杂度对其附加某种形式的惩罚。这种机制倾向于更简单、更准确的假设,而不是更复杂、有时更准确的假设。
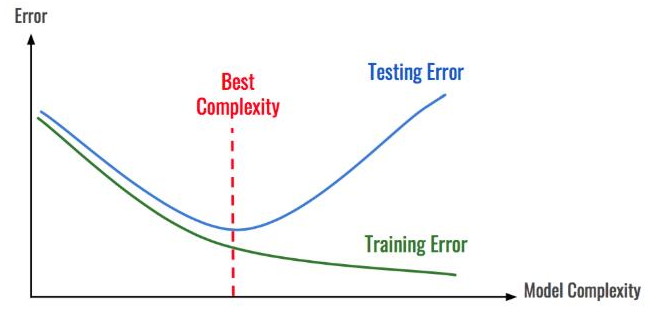
为了在区块链分析中解释这个概念,让我们假设我们正在构建一个在区块链中对支付交易进行分类的模型。
该模型使用一个复杂的深度神经网络生成1000个特征来进行分类。如果应用于较小的区块链,如Dash或Litecoin,该模型很可能会过度拟合。
偏差/方差平衡
偏差和方差是深度学习模型的两个关键估计量。从概念上讲,偏差是我们模型的平均预测值与我们试图预测的正确值之间的差异。高偏差模型对训练数据的重视程度低,模型过于简化。它往往会导致训练和测试数据的高误差。
或者,方差指的是模型对给定数据点或值的预测的可变性,它告诉我们数据的分布。高方差模型对训练数据非常重视,对未见过的数据不进行泛化。因此,这样的模型在训练数据上表现得很好,但在测试数据上有很高的错误率。
偏差和方差如何与过度拟合相关?在超简单的术语中,概括的艺术可以通过减少模型的偏差而不增加其方差来概括。
在深度学习模型中,定期将生成的假设与测试数据集进行比较并评估结果是一个很好的实践。如果假设继续输出相同的错误,那么我们就有一个很大的偏差问题,我们需要调整或替换算法。如果错误没有清晰的模式,那么问题就是不一致,我们需要更多的数据。总而言之:
· 任何低复杂度的模型都会因为高偏差和低方差而倾向于拟合不足。
· 任何高复杂度的模型(深度神经网络)都会因为低偏差和高方差而倾向于过度拟合。
在区块链分析中,偏差-方差摩擦无处不在。让我们回到我们的算法,试图预测价格与许多区块链因素。如果我们使用简单的线性回归方法,模型很可能不适合。然而,如果我们使用一个具有小数据集的超级复杂的神经网络,模型可能会过度拟合。
使用机器学习来分析区块链数据是一个非常新兴的领域。因此,大多数模型都遇到了机器学习应用程序的传统挑战。
过度拟合是区块链分析中无处不在的挑战之一,其根本原因是缺乏标记数据和训练过的模型。没有什么神奇的解决方案可以解决过度拟合的问题,但是本文中列出的一些原则已经被证明对IntoTheBlock是有效的。
责任编辑:Ct









 工商网监
工商网监
评论