 电子发烧友App
电子发烧友App



近期区块链的技术概念在传统IT圈逐渐升温,成为许多遗产系统升级重构方案的备选技术路线。笔者本人多年从事应用系统研发,目前所维护的系统性能渐露瓶颈,分片扩容难度较大且面临分布式改进的潜在需求,因而亟需区块链架构技术储备。
应用系统性能提升的关键在于运维端的接入管理模型(AAA,认证Authentication、授权Authorization、计费Accounting)及业务端的并发(Concurrency)/吞吐量(Throughput)模型。区块链是典型的“运维友好型”系统,天然的自我治理能力极大程度上优化了接入管理模型,但现有区块链系统的并发/吞吐量模型指标却饱受诟病。无论是BTC的7tps,还是ETH的40tps在传统业务系统动辄万级甚至十万级tps面前都难以抬头。
本着不重复造轮子的宗旨,首先梳理了一下对区块链项目的需求:
·聚焦底层基础设施,项目自身行业或领域特征不明显,易引入本行业业务;
·能够实现微服务级部署,扩容友好,易迁移部署;
·并发吞吐量5k+,稳定支撑10w级DAU,可靠性强。
根据需求有的放矢地寻觅区块链项目,寻觅的过程其实远比想象的简单。区块链项目多如牛毛,但纯做技术框架不扯业务场景或者经济模型的项目真心不多。通过对主流交易所的项目筛选(毕竟不能找一个不稳定的团队做的东西),基本圈定了EOS、QTUM、AELF项目。EOS官宣吞吐量约3300~3500tps,QTUM官宣吞吐量为BTC的十倍(权且估算100tps),AELF项目7月伊始发布测试网,官方暂未发布吞吐量信息。选定AELF作为调研对象的原因一方面是开发指南新近发布,与最近代码版本的可操作性强,且AELF采用的Akka并发框架应用范围较广,先前有所接触。
测试设计
现有的区块链系统业务处理能力普遍面向价值传递进行建设,因此对于区块链系统性能的评测思路应面向交易过程展开。AELF项目在区块链架构方面主打的特征是“主链+多级侧链”,链间有专门的跨链算法实现相对隔离的业务单元间资源的协同,链内节点均运行于集群,节点内部通过并行化方案提升吞吐量指标。根据官方在社区披露的信息,测试网初期(即目前)提供主链并行计算模块的测试验证,确认主链性能后再灰度升级至多级侧链版本,从软件质量体系的角度而言是合理的。通过参与社区内的技术直播互动,也与项目技术团队充分探讨了AELF选用的几个技术方案,尤其是Akka并行框架。积极选用已被验证的成熟技术元素确实是做新系统、新基础设施时的难能可贵的姿态,进一步提升了对AELF项目的好感度。PS:该团队技术的人也在社区,很NICE很好沟通。
Transaction,传统IT人习惯叫“事务”,区块链圈的人通常叫“交易”,可能是BTC白皮书翻译传承下来的吧。软件测评应充分考虑软件质量体系的要求,同理,对于一个区块链底层架构而言,模拟价值传输压力的交易激励能够作为区块链底层基础设施tps指标的验证形式。
据此,先定义一个原子事务作为本次测试验证的基本测试用例——“合约转账”。1次“合约转账”包括2次读2次写操作,具体步骤如下:
·从A账户读取余额(1次读);
·从B账户读取余额(1次读);
·从A账户减去金额(1次写);
·从B账户增加金额(1次写)。
因之前接触过BTC,深深叹服中本聪大神UTXO体系设置的精妙,但传统应用系统往往还是依赖账户模型体系,因此选用一个经典的原子转账事务作为标准测试用例,并以该用例的执行效率作为吞吐量指标的依据。AELF支持区块链智能合约,上述原子事务须编写为合约脚本部署至测试网。
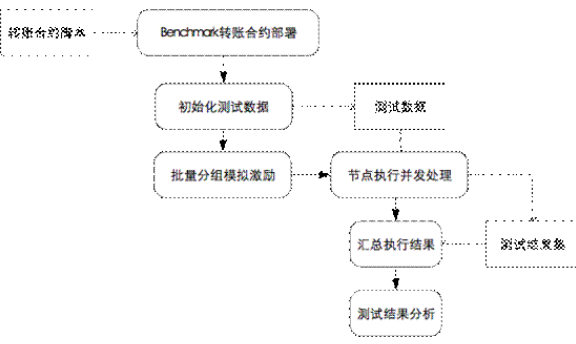
进而,再定义一个基本的测试流程梗概:
该测试流程可作为一个典型的区块链性能测评策略。以一次“合约转账”为一个基本业务执行单元,编写运行于区块链平台上的“合约脚本”程序,该程序能够被区块链系统各节点部署并执行。实施测评前需依据特定的用例或随机生成测试用例初始化测试数据,不同场景、不同轮次的测评实施须基于相同的测试数据以确保测试结果可信。测试数据作为交易申请相继对主网发起激励,对于AELF此类采用分布式并行化思想进行架构设计的项目,可采用多组数据并发激励的形式以测试较高并发交易场景下区块链系统的性能。测试过程中,可通过实时监视或特定时间片监视的方式判定测试用例的执行情况,时间片可设置为出块周期的N倍(N《=6,借鉴BTC主网6区块确认的惯例)。
继续定义不同的测试场景:
·场景I:单机场景,1业务处理节点+1业务数据集;
·场景II:集群-单机场景,N业务处理节点+1业务数据集;
·场景III:分布式集群场景,N业务处理节点+N业务数据集。
单机场景旨在验证区块链系统的独立性能,因区块链为分布式集群系统,针对单机场景测评验证对于最终全网性能指标结论的意义不是很大,但有助于我们更好地定义集群测试的边界。如单机测评的性能指标为P,进行集群测评时能够以P为基础通过节点/进程增长与性能指标增长之间的关系判定是否有必要进行更大规模的测评验证。此外,在单机测试的过程中通过补充带有网络延迟的测试环境有助于对网络环境影响因素进行基本的定量。
集群-单机场景旨在针对面向区块链底层平台所支撑的实际业务类型进行覆盖性测试。区块链技术本身是去中心化的,但区块链系统所支撑的上层业务可能有中心化特征,因此需要进行多对一场景的模拟测评。该场景的设计针对数据I/O存在固定瓶颈的情况下对区块链系统业务处理吞吐量进行定量测评。
分布式集群场景旨在针对处于P2P网络拓扑中交易执行处理与交易数据协同均需实现区块链共识的业务场景进行覆盖性测试。该场景为典型的区块链系统场景,通过单机场景及集群-单机场景的测评,能够辅助我们对该场景下的测试边界及测试差异性因子进行综合分析,确定测试实施的方式及被测部署环境的典型性,从而得到较为可靠的测评结论。
区块链系统的运行有多个层次,区块链程序可被部署至多台服务器(Server),每台服务器可运行多个进程级实例(Worker),对AELF而言,每个实例内可以配置多个并行化业务单元(Actor)。因此性能指标TPS受服务器、进程、业务单元的影响均需在测试中体现,最优TPS测评结果应表现在一个适宜的服务器、进程、业务单元配置之下,在测试条件允许之内寻找这个最优的配置也是本次测评的目的之一。
综上,拟实现的测试验证目的包括但不限于单服务节点运行状态下的并发执行能力及集群环境下的性能延展性。
测试搭建及部署
测试所选用的环境为标准云平台虚拟机(包括AWS及阿里云),根据官方在社区内推荐的配置,采用了8vCPU+16G内存的组合,网络带宽10G,Redis版本4.0.10,Twemproxy版本0.4.1,基本与标准集群生产环境类似,后续随测试网内容的增多配置可能有变化,在社区随时可以得到项目技术团队的解答。
8月8日补充:AELF官方Github已给出权威版测试搭建步骤,下文为笔者的搭建步骤。
对AELF测试网进行开发接入的核心是厘清Benchmark环境,通过与技术团队的咨询交流,下述为基本的搭建与部署执行步骤。
克隆及编译代码:
·git clone https://github.com/AElfProject/AElf.git aelf
·cd aelf
·dotnet publish –configuration Release -o /temp/aelf
确认配置文件目录:
·Mac/Linux: ~/.local/share/aelf/config
·Windows: C:UsersxxxxxAppDataLocalaelfconfig
配置数据集信息:
·将代码中的aelf/config/database.json拷贝至配置文件目录
·根据本机Redis安装情况修改配置:
{
// 数据库类型(内存:inmemory,Redis:redis,SSDB:ssdb)
“Type”: “redis”,
// 数据库地址
“Host”: “localhost”,
// 数据库端口
“Port”: 6379
}
单机场景部署:
将代码中的aelf/config/actor.json拷贝至配置文件目录,并根据本机情况配置IsCluster、WorkerCount、Benchmark、ConcurrencyLevel:
{
// 是否为集群模式
“IsCluster”: false,
“HostName”: “127.0.0.1”,
“Port”: 0,
// 并行执行 worker 的数量,建议与本机cpu 核数相同
“WorkerCount”: 8,
// 运行Benchmark模式
“Benchmark”:true,
// 最大并行分组级别,大于等于WorkerCount
“ConcurrencyLevel”: 16,
“Seeds”: [
{
“HostName”: “127.0.0.1”,
“Port”: 32551
}
],
“SingleHoconFile”: “single.hocon”,
“MasterHoconFile”: “master.hocon”,“WorkerHoconFile”: “worker.hocon”,
“ManagerHoconFile”: “manager.hocon”
}
运行Benchmark:
dotnet AElf.Benchmark.dll -n 8000 --grouprange 80 80 --repeattime 5
// -n 总事务数量 --grouprange 分组范围 --repeattime 重复执行次数
集群场景部署:
运行ConcurrencyManager:
dotnet AElf.Concurrency.Manager.dll --actor.host 192.168.100.1 --actor.port 4053
// --actor.host Manager的 IP 地址 --actor.port Manager的监听端口
将代码中的aelf/config/actor.json拷贝至配置文件目录,并根据本集群情况配置IsCluster、HostName、WorkerCount、Benchmark、ConcurrencyLevel、Seeds:
{
// 是否为集群模式
“IsCluster”: true,
// Worker的 ip 地址
“HostName”: “127.0.0.1”,
// Worker监听的端口
“Port”: 32551,
// 并行执行 worker 的数量,建议与本机cpu 核数相同
“WorkerCount”: 8,
// 运行Benchmark模式
“Benchmark”:true,
// 最大并行分组级别,大于等于WorkerCount*Worker 的进程数
“ConcurrencyLevel”: 16,
// Manager的 ip、端口信息
“Seeds”: [
{
“HostName”: “192.168.100.1”,
“Port”: 4053
}
],
“SingleHoconFile”: “single.hocon”,
“MasterHoconFile”: “master.hocon”,
“WorkerHoconFile”: “worker.hocon”,
“ManagerHoconFile”: “manager.hocon”
}
运行ConcurrencyWorker:
dotnet AElf.Concurrency.Worker.dll --actor.port 32551
// --actor.port Worker的监听端口
如Worker收到Manager的欢迎信息则说明该Worker加入集群,后续节点扩容可依托此环境开展
运行Benchmark:
dotnet AElf.Benchmark.dll -n 8000 --grouprange 80 80 --repeattime 5
测试执行与数据分析
该部分不再赘述具体的执行过程,直接针对三种场景给出测试验证的数据干货。特别强调,本次测试的数据结果为笔者自行测试,环境和过程可能因人为操作误差不是很严谨,具体性能指标以官方发布为准,好事者勿扰!!!
场景I 单机场景测试数据
通过上图可以看出,当数据库与业务单元分离部署时,网络延迟会导致TPS指标下降,同等网络延迟下TPS指标跟随变化趋势基本相同。
场景II 集群-单机场景测试数据
通过上两图可以看出当数据集服务为单例部署时,2进程16业务单元的部署模式较为理想。针对2进程16业务单元的部署模式又做了服务器扩容的补充分析,分析表明在数据集服务为单例时,服务器增长到5时性能达到瓶颈,TPS指标开始下滑。
场景III 分布式集群场景测试数据
上图测试环境为8个Redis实例构建的集群,5个Twemproxy,每台服务器连接不同的Twemproxy,TPS指标能够随扩容而增长至理想值附近。
其他相关测试参数:使用240000个交易,重复5次。
测试总结
通过上述测试验证的执行结果基本能够看出随着系统的扩容,吞吐量性能指标的增长是较为健康的,测试范围之内预期最优指标约为1.3w~1.5w tps。此外,在每一组特定的部署模式下,能够通过系统调优获得平均约10%~15%的性能提升,吞吐量性能曲线的极值点符合较为合理,符合快升缓降的泊松分布。目前小拓扑集群下的环境搭建验证基本能够满足中小型业务系统的吞吐量需求,初步可应用于传统应用系统的优化重构——当然,只用区块链技术做分布式数据库和通信组件难免有点大材小用,后续还需关注多级侧链体系的测试情况,进一步融和分布式业务模型。
简单的测试验证后,同为搬砖码农的笔者也有一些建议给AELF技术团队:
当Transaction数量级较大,且后续引入侧链的结构较复杂时,目前的分组策略耗时可能会有比较显著的提升,如10w级事务分1k级处理单元组时,可能的分组时间会达到800ms~1000ms,分组策略在后续多级侧链体系下有待进一步优化;
系统目前配置的Round-Robin-Group路由策略在生产环境下并非最优,路由能力可通过配置调优的方式得到进一步提升;
并行化事务处理过程中建议增加健康状态监控机制,如MailBox,以方便运维、开发团队了解执行过程及定位问题,否则复杂关联事务的死锁可能会导致无法预见的系统失效。
刨除掉上述三点,该测试网目前的表现可圈可点,后续进展值得期待。以上即为对区块链性能评测的方案分享。









 工商网监
工商网监
评论