 电子发烧友App
电子发烧友App


3月29日,ABT Network(ABT 链网)正式发布。ABT Network以完全去中心化方式连接编织多条区块链形成的网络,以云节点和织链为网的方式重新定义了新一代区块链基础架构。本文谈谈 ABT Network 诞生前发生的有趣经历。
为方便阅读,先简单介绍一下本文谈到的一些概念:
· ABT Network:多条使用 ArcBlock 技术打造的区块链形成的网路。
· ABT Chain Node:ArcBlock 使用 Forge Framework 打造的区块链节点软件。
· Forge Framework:ArcBlock 为区块链开发打造的框架,可以看做区块链世界里的 Ruby on Rails。
打造人人都可部署的节点
在开发 Forge Framework 和 ABT Chain Node 时,我们有一个深深的信念:运行在 Forge 之上的区块链项目可以是阳春白雪,也可以是下里巴人;可以是每日千百万级 transaction 的大型应用,也可以是独立开发者及其小圈子的自娱自乐。因而,一个节点只要有过得去的算力,就可以运行 Forge,这样,只要愿意,人人都可以部署自己可负担的节点。
那什么算是「过得去的算力」呢?考虑到 App 开发者的开发期的经济能力,我们将其定位在单节点月支出在 $15 以内,在 Digital Ocean 上,这对应:

也就是 1GB / 1CPU / 25GB disk 一路到 2GB / 2CPU / 60GB disk 的乞丐版云主机。
在今年一二月份的大部分开发时间里,我们都在使用 $5 的至尊乞丐版主机 —— 而且,我们一口气在美西 (SF),美东 (NY),西欧 (London) 和东南亚 (Singapore) 部署了四个节点,组成一个 P2P 网络,来开发 Forge。我们相信,极端恶劣的环境,能打造尽可能健壮的软件,让各种问题都提前暴露出来。
有了环境,我们需要有足够模拟真实应用场景的流量。为此我们开发了一个 simulator(模拟器),并且做了一个简单的描述语言来描述我们如何开启 simulation(节选):
pools:
create_asset: 5
declare: 5
exchange: 5
transfer: 10
update_asset: 5
consume_asset: 5
poke: 5
meta:
tick: 500
simulations:
- name: exchange token and assets
interval: 2
num: 2
type: exchange
settings:
value: “1000..20000”
- name: transfer token and assets
interval: 5
num: 2
type: transfer
settings:
value: “1000..5000”
after:
- interval: 1
action: consume_asset
通过改变 pool size,我们可以调节并发程度,通过控制 tick,我们控制 traffic 的速率;通过添加更多的 simulation,我们改变 traffic 的多样性。
在 simulator 的作用下,很长一段时间里,我们的开发网络三天两头 crash(崩溃) —— 一会 out of memory,一会 too many open files,一会 gen_server tiemout,一会 tcp send/receive buffer full。这些问题,如果换上个 4G memory / 4 CPU / 100G disk 的主机,只有很小的概率才暴露出来,而我们主动让其发生在开发环境中,使得大部分问题得到了妥善处理。比如说,我们发现我们使用的 consensus engine(共识引擎) 不稳定,时不时 crash,crash 之后很容易把 state db(状态数据库) 写坏,使得节点彻底崩溃,无法恢复。对此,我们的做法是,一旦 consensus engine crash,我们让 Forge 自动 crash(可惜了 erlang VM 强大的 crash recover 机制),然后由我们开发的 forge starter 将 forge 重启。重启后,我们回溯到上一个区块的数据,重新 apply,如果 consensus engine 可以恢复,那么旧继续往后走;否则便继续 crash 和继续回溯。
在这样严苛的环境下 Forge 逐渐成长,至尊乞丐节点组成的网络,不断死亡,不断重生,就像「明日边缘」里的汤姆克鲁斯,从小白一路成长为小强,迎来了第一百万个 transaction。
好景不长,在大约 1.5M txs 时,网络再次 crash:
这次 crash 的一干二净,所有节点全军覆没,连 ssh 都上不去。Digital Ocean 的监控显示 CPU 基本为 0,正琢磨着是不是 disk 写满了,一台机器回光返照,给我登上去 du 的机会。果然,25G 的 disk 被吃得一干二净。take snapshot,换大硬盘,搞定。
三月上旬我们终于抛弃了 $5 的机器,换装 $15 的「大」节点。在 Digital Ocean 的云上,我们同时跑了好几个网络,做 rolling upgrade。之前我们一周一个 milestone,出一个大版本,若干小版本,三月第二周起,我们每天出一个版本,因而,版本太多而网络不够用了。。。
很快,1 million txs 的里程碑被 5 million 取代:
继而被 6M,7M,… 取代。后来我们 breaking change 太多,也就没有继续累积这个数字。
可以让区块链节点稳定地在 $15 的机器上部署是我们 ArcBlock 的一个创举。我们做过别的公链的节点 —— 对方给出的推荐配置,一个节点一个月要一千多美金。如果一个应用开发者开发者,想部署一个自己的链,初期通过自己的节点来服务其用户,假设节点部署在全球四个区域:每个区域两个节点,那单单是这样一笔开销,就超过上万美金每月 —— 没有充沛现金的小玩家,是烧不起这个钱的。所以我们希望这个数字能够低至几百。
然而 Digital Ocean 毕竟是服务于小客户的,一个严肃的 dApp,在开发阶段使用 DO 无可厚非,在生产环境 —— 当链上线之后,更具实力的云服务是更好的选择,比如我们自己的 ABT network 就部署在 aws。
简约而不简单的生产环境
由于 ABT network 强调织链为网,我们首发三条以化学元素「氩(Argon)」「溴(Bromine)」「钛(Titanium)」命名的元素链(其中 Bromine 是一条专门运行最新 nightly build 版本的测试链)。因而我们需要为这三条链准备安全可信的生产环境。
我们是这样考虑线上的生产环境的:
1. 每条链都部署到亚太欧美四个区域;
2. Argon 和 Titanium 各十六个节点;Bromine 四个节点
3. 所有节点都只对外暴露 p2p 端口;
4. 节点的 GraphQL RPC 和自带的区块浏览器通过 ELB 允许外部访问,而 gRPC 只允许本地访问;
5. 每个 region,每条链的 ELB 的域名,由 route 53 按照 latency 来 load balancing。
最重要的,要自动化,要足够省钱。
自动化,这个不消说,我们已经有深厚的 ansible / terraform 经验。
省钱是个学问。
按照上面的配置,哪怕只用物美价廉的 c4.large / c5.large,每个节点配 110G EBS,每条链每个区域都配一个 ELB,一个月下来光固定成本就要 $3721。
计算公式: 0.11 (c4.large 价格) x 36 x 24 x 31 + 36 x 110 x 0.12 (EBS 价格) + 25 (ELB 价格) x 12
这其中,EC2 占了大头,接近 $3000。
我们的目标,是尽可能降低这个成本。
于是我们的目光投向了 spot instance。下图是 spot instance 在 us-east-2 和 ap-southeast-1 的价格走势:
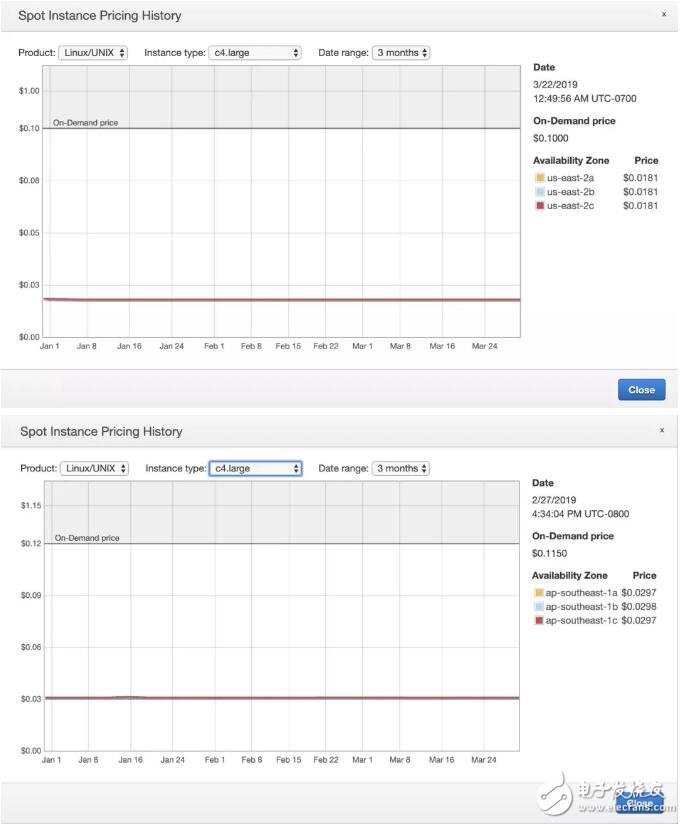
价格基本稳定在 on-demand instance 的 2 折,也就意味着 EC2 这块,我们可以把成本降到 $600,总价只需 $1300 每月。
然而用 spot instance,绕不过去的坎就是万一 instance 被杀掉,如何尽快恢复服务?尤其是验证人节点?
我们采用的方式是 root disk 和 data disk 分离,Forge 存储的所有数据放 data disk,而 Forge 的配置,节点私钥,验证人私钥,放 root disk,然后在初始化之后备份到一个 AES 加密的,只允许单次写的 S3 bucket 中。之后,在节点运行的时候,每条链每个区域定期备份某一个健康节点的 data disk。这样,当验证人节点被杀掉时,我们可以从最近的一个备份中恢复 data disk,然后从 S3 中找回该验证人节点的私钥和配置。
这个思路说起来挺简单直观,做起来可要颇费一番心思的。不过最终我们趟平了这条路,证明了它是可行的,对 dApp 开发者,甚至其他区块链的同行,这种使用 spot instance 运行区块链节点的方式都有借鉴意义。
最终我们的部署脚本 forge-deploy 分成四部分:
1. 只需要一次性运行的脚本:比如为每个区域每个 VPC 创建 security group
2. 制作 Forge AMI 的脚本:我们每 release 一个新的版本,都会创建一个新的 AMI。
3. 创建一条新链所需要的资源的脚本:比如创建 spot request,EBS,创建 ELB,target group,设置 listener (及 listener rules),创建域名及域名解析的 policy。
4. 管理一条已有链的脚本:比如初始化链,重启节点,升级节点,修复损坏的节点,添加新的节点等
三月的最后两周,forge-deploy 在原有零散脚本(部署 DO 机器的脚本)的基础上边开发边测试 —— 我们的链建了拆,拆了建,两周趟过了很多区块链团队可能一年都没有趟过的路:最多的时候我们有 6 条链并行运行,算上那些朝生暮死的 abtchain,origin,bigbang,test,abc 等链,我们前前后后创建了和销毁了三十多条链 —— 注意,这里说的是多区域多节点的链,单个节点的链并不包含在内。
由于之前累积了足够的自信,在 ABT Network 上线的那一天,我们自负地把之前为发布已经创建好的三条链:Argon,Bromine 和 Titanium 在上线倒计时前不到半小时拆掉重新发布,让整个团队和社区关心我们的人可以看到区块从零到一的跃迁。虽然中间有点波折 —— 部署脚本运行得比预想要慢一些 —— 因而在发布倒计时结束后我们还没有部署完成,但最终,耽搁了大约二十分钟,三条链还是如愿上线。每条链的部署只需要两条命令:

其中,create_fleet 会在四个区域里都做这些事情:
1. 获取当前区域的 default VPC id
2. 获取 VPC 的 subnet id
3. 获取预先创建好的几个 security group 的 id
4. 用预设的配置为验证人节点申请 spot fleet
5. 用预设的配置为哨兵节点申请 spot fleet
6. 等待所有申请好的 instance 可以正常工作
7. 创建 ELB
8. 创建 target group,并将所有 instance 加入 target group
9. 获取预先上传好的证书 id
10. 创建两个 ELB listener,80 端口直接 301 到 443,而 443 端口把流量转发到 target group
11. 创建 DNS 域名记录,设置 latency based policy
当四个区域都完成之后,为这条链的所有 instance 创建 ansible inventory,以便后续处理。
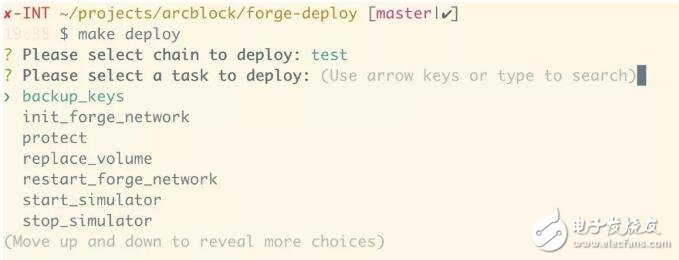
接下来,在 init_forge_network 里,会做这些事情:
1. 把 data disk mount 到对应的 instance 上,并格式化文件系统为 XFS
2. 使用临时配置文件启动 Forge,生成 node key 和 validator key
3. 把生成的 key 备份到 S3
4. 根据 inventory file,找出验证人节点,将其 validator address 写入 genesis 配置中
5. 启动 forge
所有节点起来后,稍候片刻,一条链就完美诞生了!













 工商网监
工商网监
评论