利用AI实现图像的超级压缩
神经网络这样的数据驱动算法,已经狂风暴雨般的席卷了世界,包括廉价且强大的硬件和大量的数据等方面的因素,导致AI技术的突飞猛进。
神经网络是当前“图像识别”、“自然语言理解”等“认知”领域的最新技术,但其应用并不限于这些。在这篇文章中,我们将讨论一种使用神经网络压缩图像的方法,该方法能以更快的速度,达到图像压缩技术的最优化。
该文基于论文:An End-to-End CompressionFramework Based on Convolutional Neural Networks(https://arxiv.org/pdf/1708.00838v1.pdf)
本文假设,你对包括卷积和损失函数等神经网络有一定了解。
▍什么是图像压缩?
图像压缩是将图像转换为更小占用空间的过程。原始图像存储将占用大量空间,因此会使用编解码器减小原始图像的大小,例如JPEG和PNG。
图像压缩有两种类型:无损和有损。
顾名思义,在无损压缩中,可能获取原始图像的所有数据,而在有损压缩中,一些数据在转换过程中丢失。
例如:JPG是一种有损算法,而PNG是一种无损算法。
图1.0:无损和有损压缩之间的比较
能看到右边的图像有许多块状的纹路,这就是信息的丢失。相似颜色的临近像素被压缩为一个区块,这节省了空间,但也丢失了关于实际像素的信息。
图示只是有损压缩的直观示例,真实的JPEG,PNG等编解码器所使用的算法要复杂得多。无损压缩当然更好,但最终在磁盘上占用的空间太多。
当然,有更好的方法压缩图像而不会丢失太多的信息,但是它们相当慢,许多算法使用迭代的方式,这意味着它们不能在多个CPU内核或GPU上并行运行。这使得这些算法在日常使用中不实用。
▍卷积神经网络
如果任务需要计算,且可以近似计算,就可以考虑使用神经网络。论文作者使用了相当标准的卷积神经网络来改善图像压缩。他们的方法不仅仅是“更好的方式”,还可以利用并行计算,实现高速压缩。
其背后原理是卷积神经网络(CNN),能很好地从图像中提取空间信息,然后以更紧凑的表征来表示(例如,仅存储图像的“重要”位点)。论文作者利用CNN的这种能力来更好地压缩、展示图像。
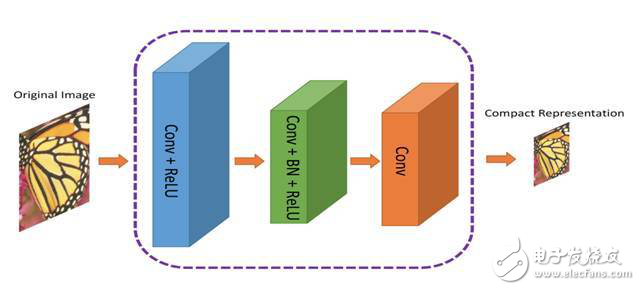
▍架构
论文提出了一个双重网络。第一层网络(ComCNN)提取图像信息并生成一个致密表征。然后,该网络的输出将由标准编解码器(例如JPEG)来处理。
经过编解码器后,图像将被传递到第二层网络,该层网络将从编解码器“修复”图像,试图恢复原始图像。作者称之为重建卷积神经网络(RecCNN)。这两个网络都经迭代训练,类似生成对抗网络(GAN)。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
下载地址
利用AI实现图像的超级压缩下载
相关电子资料下载
- Arm物联网事业部业务拓展副总裁马健:如何帮助AIoT企业加速创新? 21
- Blackwell GB100能否在超级计算机和AI市场保持领先优势? 174
- 讯飞星火大模型V3.0正式发布,全面对标ChatGPT 299
- 亚马逊云科技生成式AI最新案例分析,助力企业业务创新迭代 57
- 新思科技携手台积公司加速N2工艺下的SoC创新 196
- 服务器硬盘通用基础知识 19
- 常见的一级指针参数有什么作用 73
- NVIDIA AI 现已在 Oracle Cloud Marketplace 推出 33
- CNCC | 论坛:探索 AI 全栈解决方案和基于 LLM 的推理与部署实践 36
- Prophesee的GenX320第五代DVS传感器产品参数介绍 31