人机交互的核心对话系统
语音作为互联网的一种入口方式,正在侵入我们的生活,人机交互的核心——对话系统,对交互的应用至关重要,人脑与机器智能的结合,能够突破现有技术瓶颈吗?

从整个交互系统接入用户的输入信息开始,包括语音、人脸、多模态情感相关的信息,我们在对话系统里面对输入的信息进行理解,通过这个对话部分以后产生输出,最后用文字也可以用语音合成展现出来,这就是整个流程,其中我们关注的最主要的是语音部分以及对话系统部分,其他的多模态今天的分享不会涉及太多。
国内研究语音相关的团队主要包括科研院所、语音技术公司以及互联网公司三部分:
科研院所主要包括高校和科学院,比如科学院里有声学所、自动化所,高校里面研究比较多的清华、北大、西工大、科大、上海交大等,这些都是在语音圈里占有较高位置的老牌队伍。
语音技术公司包括我们比较熟悉的科大讯飞、云知声、极限元、思必驰等。
互联网公司包括BAT、搜狗等拥有强大的语音技术团队来支撑着其本身的很多业务。
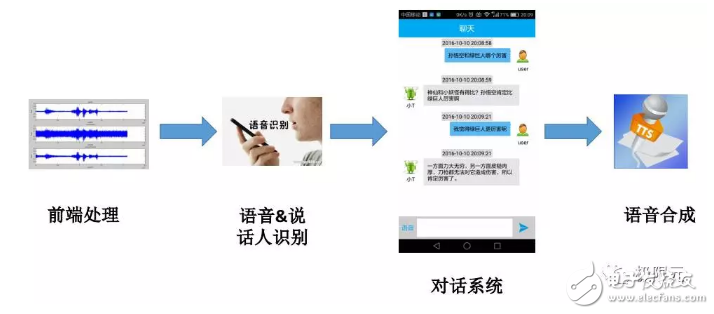
在应用对话系统时,首先从语音输入开始要有一些前端处理,包括硬件和软件的前期处理;接下来是语音内容,说话人识别等相关的内容进行判别,对话系统根据输入信息来进行对话逻辑的分析,以及对应语言的产生,最后由语音合成系统来合成语音,在这里重点介绍一下前端处理、语音识别、说话人识别语音合成等相关技术。
前端处理技术的研究进展
前端处理包括回升消除、噪声抑制、混响抑制等技术,刚开始时研究前端处理的人员并不多,近年来特别是ECHO的推出,把一些远场的问题融入到语音识别等系统中,所以这部分的研究在这几年兴起比较快,语音识别的研究从一些简单的数据如手机的录音扩展到远场的语音识别,这些促进了前端处理技术的发展,在语音圈里做前端处理比较牛的应该是陈景东老师。

回声消除:回声消除在远场语音识别中是比较典型功能,最典型的应用是在智能终端播放音乐的时候,远场扬声器播放的音乐会回传给近端麦克风,此时就需要有效的回声消除算法来抑制远端信号的干扰,这是在智能设备如音响、智能家居当中都需要考虑的问题。比较复杂的回声消除系统,近端通过麦克风阵列采集信号,远端是双声道扬声器输出,因此近端需要考虑如何将播出形成算法跟回声消除算法对接,远端需要考虑如何对立体声信号相关。
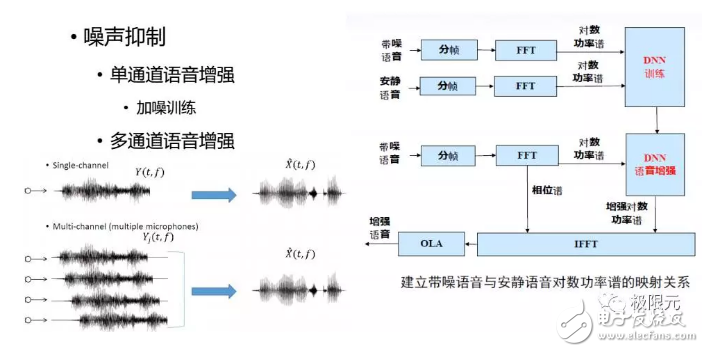
噪声抑制:噪声抑制可以有多通道的也可以有单通道的,今天主要介绍单通道噪声抑制,单通道语音增强通过DNN的方法进行增强,语音信号是有一个谐波结构的,通过加入噪声这个谐波结构会被破坏掉,语音增强的主要目的就是抬高波峰,降低波谷,这个训练对DNN来说是比较容易的。但是也有实验研究表明,基于DNN的语音增强对浊音段效果会比较好,但对轻音段效果并不是很好,语音的浊音段有显著谐波结构,因此要有目的去训练这个模型。

混响抑制:声音在房间传输过程中经过墙壁或者其他障碍物的反射后到达麦克风,从而生成混响语音,混响的语音会受到房间大小、声源麦克风的位置、室内障碍物等因素的影响,大多数的房间内混响时间大概在200–1000毫秒范围内,如果混响时间过短,声音会发干,枯燥无味,不具备清晰感,混响时间过长会使声音含混不清,需要合适的声音才能圆润动听。
前端处理涉及的内容比较多,除了前面提到的还包括多说话人分离、说话人移动过程中的声音采集、不同的麦克风阵列结构、各种噪声和房间模型如何更好的建模等。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%