ios10中神经网络分析
大小:0.5 MB 人气: 2017-10-10 需要积分:1
有时候,我们可能想超越平台内置API的限制,创造独一无二的东西。但更多的时候,我们是使用了一些现成的库或直接建于Accelerate或Metal的快速计算功能之上,推出自己的机器学习功能。
例如,我的同事专为办公室建立了一个录入系统,只使用一台可检测人脸的iPad,然后在Slack投递一个gif,并允许用户通过自定义命令开门。
但是现在,我们有了用于神经网络的第一方支持:在2016年的WWDC上,苹果公司推出了两个神经网络的API,分别称为基础神经网络子程序(BNNS)和卷积神经网络(CNN)。
机器学习和神经网络
AI先驱Arthur Samuel将机器学习定义为“没有明确编程的情况下,给予计算机学习能力的研究领域”。人们用机器学习系统理解一些数据的意义,而这些数据不能很容易地使用传统模型来描述。
例如,编写一段计算房子建筑面积的程序很容易,我们可以考虑到所有房间和其他空间的规模和形状,但是却不能在公式中计算房子的价值;而另一方面,机器学习系统却非常适合解决这样的问题。通过给系统提供已知的具体数据,如市场价值、房屋尺寸、卧室数量等,从而可以利用它预测价格。
神经网络是构建机器学习系统最常用的模型之一。早在半个多世纪前的1940年,已经发展了神经网络的数学基础,而上世纪80年代,并行计算才使其更为可行;并且到了2000年,人们对于深度学习的兴趣又引发了神经网络的回潮。
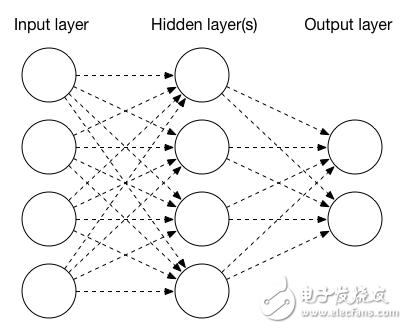
神经网络由多个层构造,其中每个层由一个或多个节点组成。最简单的神经网络具有三层:输入、隐藏和输出。输入层节点可以代表图像中的各个像素或一些其他参数;如果我们试着自动检测照片的内容,输出层节点则经常作为分类的结果,例如“狗”或“猫”;隐藏层节点配置为对输入执行操作,或配置为应用激活函数。
层类型
三种常见的层的类型为:池化(pooling)层、卷积层和全连接层。
池化层通常通过使用输入的最大值或平均值来汇集数据,降低其大小。一系列的卷积和池化层可以结合起来,用于将照片逐步提炼成越来越高层次的特征集合。
卷积层将卷积矩阵用于图像的每个像素,实现图像变换。如果你已经用过Pixelmator或Photoshop滤镜,那你很可能也用过了卷积矩阵。卷积矩阵通常是一个3×3或5×5的矩阵,被施加到输入图像的像素中,以计算输出图像中新的像素值。为获得输出像素值,我们就乘以原图像中的像素值,并计算平均值。
例如,该卷积矩阵用于图像模糊:
1 1 1 1 1 1 1 1 1
而下面的矩阵能够锐化图像:
0 -1 0 -15-10 -1 0
神经网络的卷积层使用卷积矩阵处理输入,并产生下一层的数据。例如,提取图像中的诸如边缘特征的新特性。
全连接层可以被认为是滤波器尺寸和原始图像相同的卷积层。换句话说,你可以这么认为,全连接层是一个函数,能够为每个像素分配权重,平均其结果,然后给出单个的输出值。
训练和推理
每一层都需要配置适当的参数。例如,卷积层需要输入和输出图像的信息(规模、通道数目等),也需要卷积层参数(内核大小、矩阵等)。全连接层通过输入和输出向量、激活函数和权重来定义。
要获得这些参数,必须训练神经网络。需要以下几步才能完成:通过神经网络传递输入,确定输出,测量误差(即实际结果与预测结果相差多远),并通过反向传播调整权重。训练神经网络可能需要数百、数千甚至成千上万的样本。
目前,苹果公司新的机器学习API,可用于构建只做推理的神经网络,而不是训练。这都是Big Nerd Ranch的功劳。
Accelerate: BNNS
第一个新的API是Accelerate框架的一部分,被称为基础神经网络子程序(BNNS,Basic Neural Network Subroutines)。BNNS补充了BLAS(基础线性代数子程序),并用于一些第三方的机器学习应用。
BNNS在BNNSFilter类中定义层。Accelerate支持三种类型的层:
卷积层(由BNNSFilterCreateConvolutionLayer函数创建)全连接层(BNNSFilterCreateFullyConnectedLayer)池化层(BNNSFilterCreatePoolingLayer)
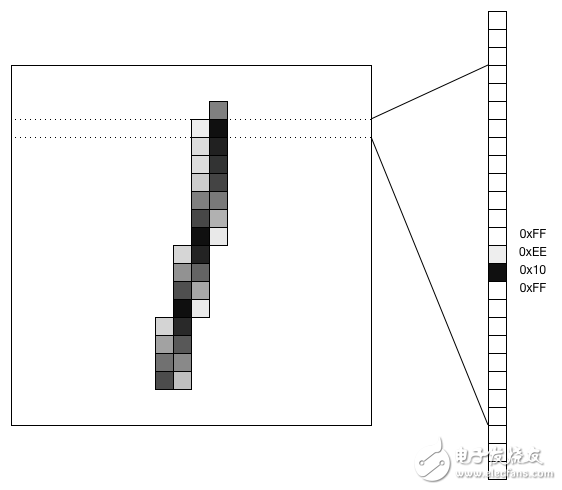
MNIST 数据库是一个众所周知的数据集,包含数以万计的手写数字,用于扫描和调整,以适应20乘20像素的图像。
一种处理图像数据的方法是将图像转换成矢量,并使之通过一个全连接层。对于MNIST数据,一个20×20的图像将成为400个值的矢量。下面展示了如何将手写的数字“1”转换为向量:
下面是配置全连接层的实例代码,该层将大小为400的矢量作为输入,采用S形的激活函数,输出矢量大小为25:
// input layer deor BNNSVectorDeor i_desc = { .size= 400, .data_type = BNNSDataTypeFloat32, .data_scale = 0, .data_bias = 0, };// hidden layer deor BNNSVectorDeor h_desc = { .size= 25, .data_type = BNNSDataTypeFloat32, .data_scale = 0, .data_bias = 0, };// activation function BNNSActivation activation = { .function= BNNSActivationFunctionSigmoid, .alpha= 0, .beta= 0, };BNNSFullyConnectedLayerParameters in_layer_params = { .in_size = i_desc.size, .out_size = h_desc.size, .activation= activation, .weights.data= theta1, .weights.data_type = BNNSDataTypeFloat32, .bias.data_type = BNNSDataTypeFloat32, };// Common filter parameters BNNSFilterParameters filter_params = { .version= BNNSAPIVersion_1_0; // API version is mandatory};// Create a new fully connected layer filter (ih = input-to-hidden) BNNSFilter ih_filter = BNNSFilterCreateFullyConnectedLayer(&i_desc, &h_desc, &in_layer_params, &filter_params);float * i_stack = bir; // (float *)calloc(i_desc.size, sizeof(float));float * h_stack = (float *)calloc(h_desc.size, sizeof(float));float * o_stack = (float *)calloc(o_desc.size, sizeof(float));int ih_status = BNNSFilterApply(ih_filter, i_stack, h_stack);
Metal!
该部分会得到更多的Metal吗?确实是的,因为第二个神经网络API是Metal Performance Shaders(MPS)框架的一部分。Accelerate是在CPU上进行快速计算的框架,而Metal将GPU发挥了极致。Metal的特点是卷积神经网络(CNN,Convolution Neural Network)。
MPS自带了一个类似的API集。
创建卷积层需要使用MPSCNNConvolutionDeor和MPSCNNConvolution函数。MPSCNNPoolingMax将为池化层提供参数。全连接层由MPSCNNFullyConnected函数创建。激活函数由MPSCNNNeuron的子类定义:
MPSCNNNeuronLinearMPSCNNNeuronReLUMPSCNNNeuronSigmoidMPSCNNNeuronTanHMPSCNNNeuronAbsolute
BNNS和CNN的比较
下表为Accelerate和Metal激活函数列表:
Accelerate/BNNS
Metal Performance Shaders/CNN
BNNSActivationFunctionIdentity
BNNSActivationFunctionRectifiedLinear MPSCNNNeuronReLU
MPSCNNNeuronLinear
BNNSActivationFunctionLeakyRectifiedLinear
BNNSActivationFunctionSigmoid MPSCNNNeuronSigmoid
BNNSActivationFunctionTanh MPSCNNNeuronTanH
BNNSActivationFunctionScaledTanh
BNNSActivationFunctionAbs MPSCNNNeuronAbsolute
池化函数:
Accelerate/BNNS
Metal Performance Shaders/CNN
BNNSPoolingFunctionMax MPSCNNPoolingMax
BNNSPoolingFunctionAverage MPSCNNPoolingAverage
Accelerate和Metal为神经网络提供的一组函数功能非常相似,所以二者选择取决于每个应用程序。GPU通常首选各种机器学习所需的计算,而数据局部性可能会导致Metal CNN的运行性能比Accelerate BNNS版本要差。如果神经网络对已存入GPU的图像进行操作,例如,使用MPSImage和新MPSTemporaryImage时,很明显,这时更适合用Metal。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%