机器学习工作流编排工具Netflix
大小:0.3 MB 人气: 2017-10-10 需要积分:1
Meson是一个通用的工作流编排和调度框架,用于管理跨异构系统执行工作负载的ML管道。它管理着一些ML管道的生命周期,这些ML管道用来构建、训练并验证驱动视频推荐的个性化算法。
Meson的主要目标之一是提高算法实验的速度,可靠性和可重复性,同时允许工程师使用他们选择的技术来处理每个步骤。
增强机器学习管道
在Netflix内部,Spark、MLlib、Python、R以及Docker在当前一代的机器学习管道中起到了重要作用。
我们来看看驱动视频推荐的典型机器学习管道,以及在Meson中它是如何表示和处理的。

(点击放大图片)
工作流包括:
选择一组用户——使用Hive查询来选择用于分析的队列
清洗/准备数据——一个Python脚本来创建两组用户,用于并行路径
在并行路径中,一条使用Spark构建并分析全局模型,使用HDFS作为临时存储。
另一条使用R来构建具体地区(国家)模型。地区的数量根据用于分析所选择的队列动态变化。图中的构建地区模型和验证地区模型步骤对于每个地区(国家)重复执行,在运行时扩展,使用不同的参数集执行,如下所示。
验证——当两条路径收敛时,使用Scala代码对模型的稳定性进行测试。在这个过程中,如果模型不稳定,则回到上面的步骤,重复整个过程。
发布新模型——使用Docker容器发布这个新模型,其他生产系统来获取这个模型。
(点击放大图片)
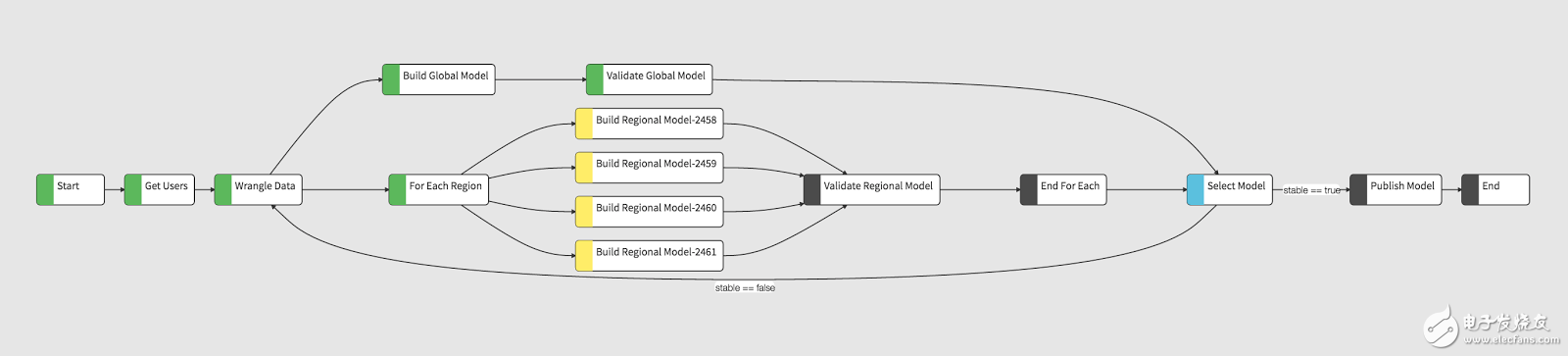
上图显示了上面描述的工作流运行过程。
用户集选择,数据清洗的完成由绿色步骤表示。
并行路径正在处理:
Spark分支完成了模型的生成和验证。for-each分支分出了4个不同的地区模型,它们都在处理(黄色)。
用于模型选择的Scala步骤是激活的(蓝色)。这表明一个或多个输入分支已经完成,但它还不会安排执行,因为还有些输入分支(a)还没有开始或(b)正在处理。
运行时上下文和参数随着工作流传递,用于业务决策。
揭开面纱
让我们深入幕后场景来了解Meson是如何在不同系统之间统筹,以及生态系统中不同组件之间的相互影响。工作流有着不同的资源需求和总运行时间期望。我们依靠Apache Mesos这样的资源管理系统来满足这些需求。Mesos提供了任务隔离,以及CPU、内存、存储和其他计算资源的优秀抽象。Meson利用这些功能来实现任务的弹性和容错性。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%