实例分析关于美团Node的全栈开发实践
大小:0.4 MB 人气: 2017-10-10 需要积分:1


“前后端分离”显然已不是什么新鲜的话题,Zakas在2013年10月份就曾发表过一篇博客《Node.js and the new web front-end》讨论Node背景下新时代的前端。毫无疑问,Node的出现给Java语言带来了新的生机,也使得前端开发者有了更多的可能性。
前后端分离表面上看似乎是一场“圈地运动”,但实质上前后端分离是为了解决以往开发模式的一些诟病和痛点,同时也是迎合大的行业趋势的明智之举。我所在的美团酒店事业部去年7月份成立,新的业务、新的开发团队,这一切使得我们的前后端分离推进的很彻底。截至目前,前端承载的所有业务和线上服务都是基于Node,生产环境已经有近60台服务器。如此带来的全新前后端协作方式能够让专业的人做专业的事,无论前端后端都能较之前更专注在自己擅长的方面。
开发模式、技术栈
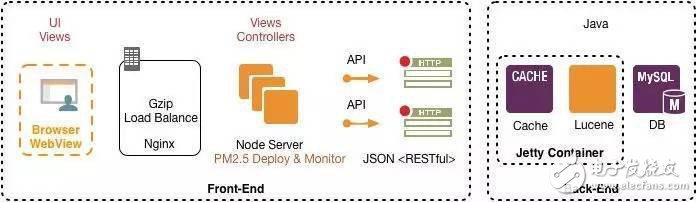
传统的开发模式只需要专注在多终端的呈现上(浏览器、WebView)。而现在,浏览器只是前端的其中一环,延伸出来的还有Node端的架构、服务的运维能力等。上图是我们目前的服务架构:Nginx位于Node服务之前,用做负载均衡、服务调度、Gzip压缩等。之后便是Node服务,我们通过PM2.5进行Node服务的Cluster部署和负载均衡(充分利用多核优势),同时作为轻量的中间层,负责路由、Controllers、Views、以及视图的渲染,数据的获取通过RESTful的API接口使用JSON格式交互。而后端则只需要负责业务逻辑、数据存储、Models,并为前端提供JSON数据即可。
这样改变之后,Node端可以进行首屏渲染等页面加载方面的优化,页面渲染出来之后后续的交互、渲染都交由浏览器端的Java代码来完成,Node端的模板和浏览器端的模板大部分情况下都是相同的,所以我们需要考虑模板重用的问题。我们用Juicer替换了Express框架默认的模板引擎,Juicer是一个高效、轻量的前端 (Java) 模板引擎,效率和易用是它追求的目标。除此之外,它还可以运行在 Node.js 环境中。通过Juicer,可以解决Node端和浏览器端的模板、Helper复用问题。而且基于前后端分离的工程架构下,前端的代码仓库和后端隔离,前端独立负责前端静态资源文件、模板文件、Controller的维护和发布。
按照这样重新定义前后端分工之后,前端可以做的事情较以往更多了,比如微信SDK的接入,因为微信JS SDK的使用需要在服务端进行签名,所以现在我们不需要后端介入,前端完全可以独立完成微信SDK的接入。此外像我们内部和商家端SSO登录逻辑的接入都完全由前端独立完成。
技术选型的思考
对于前端的技术选型,我们始终保持理性、拥抱的态度。我们不会为了盲目求新而引入新的技术,技术选型是针对我们目前大团队的场景,为了解决以往协作过程中发现的一些痛点和不足。比如引入Node是为了改进前后端的工作流和效率,提升前后端的开发体验。再比如目前我们项目中采用的Angular、React也是针对特定的业务场景,为了提升开发效率、增强代码的可维护性。在我们的业务应用中,面向商家、后台的一些增删改查系统,Angular能够显著的提升开发效率,而React我们目前只是在面向用户的PC端项目中在做一些尝试和实践。
带来的挑战
这样的分工和架构模式在给前端带来更多可能性、更多便利的同时,也带来了不小的挑战,相比传统的前端角色而言,我们需要更多的关注线上服务的状态,进程内存占用、CPU占用的详细状况,以及线上异常的监控等。在我们拥抱Node的同时,对前端的能力要求是更上一阶的。一段看起来正常的JS代码,在浏览器端和在Node端两种不同的运行环境下,就可能会暴露出一些以往关注不到的问题,比如内存泄露:一个闭包或者一个用于缓存数据的对象,跟浏览器不同,Node对内存泄露十分敏感,因为线上应用有成千上万甚至百万计的流量,所以哪怕是一个字节的内存泄露也会造成内存堆积,从而导致垃圾回收过程耗时增加,应用响应缓慢,知道进程内存溢出,应用重启或崩溃。
内存泄露问题的定位
以下是我们在生产环境遭遇的一个案例:最近发现线上服务的内存占用在服务重启后会呈线性的增长,进程启动18小时后,内存就已经占用接近1.6G左右,之后不久便会超过V8的内存限制导致服务重启。从图中可以看出,在修复之前内存使用情况一直在随时间进行周期性的波动,波动的原因就是线上Node进程不断的重启导致的。
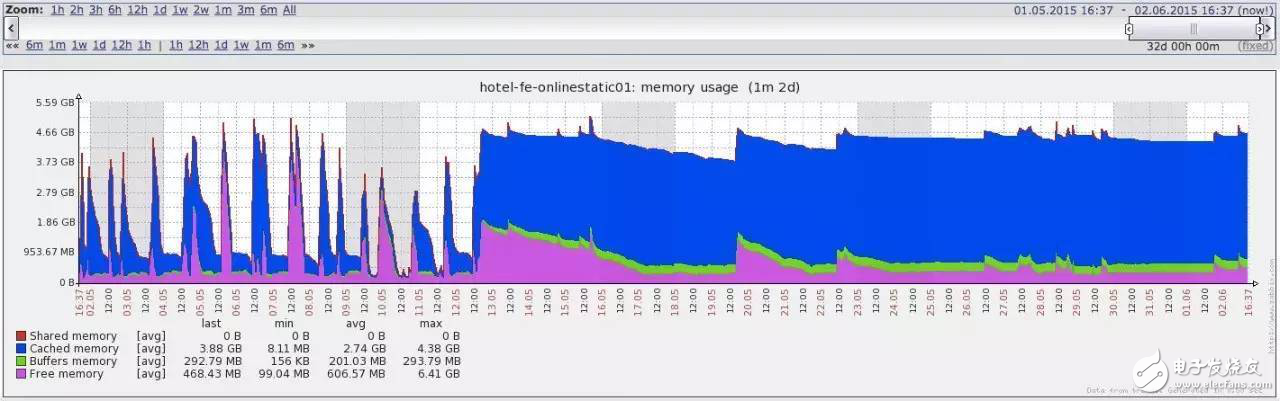
众所周知,在V8的垃圾回收机制下,一般的代码很少出现内存泄露的情况,但是一旦出现内存泄露往往较难排查。但造成内存泄露的本质原因只有一个,就是应当回收的对象没有正常被回收,变成了老生代中的常驻对象。好在借助一些常见的排查工具可以帮助我们定位内存泄露的具体原因:
v8-profiler
node-heapdump
node-mtrace
dtrace
node-memwatch
这里我们使用node-heapdump来在模拟访问的条件下生成堆内存的snapshot,并通过Chrome的开发者调试工具对生成的snapshot文件进行分析。通过对比服务刚启动时以及使用AB模拟并发访问一段时间后的heapdump信息可以比较容易的定位到内存泄露的问题点:是因为Juicer默认开启了cache,会默认对编译后的模板进行缓存,因此随着访问的增长和并发请求,cache对象会持续增长且不被回收,于是关闭cache并重新部署上线后线上恢复正常。
由于在浏览器的场景中运行时间短,且运行在用户的机器上,即便内存使用过多或者内存泄露,也只会影响到用户的终端。而且运行时间短,随着进程的退出,内存也会随之释放,几乎没有太多内存管理的必要。但在Node端同样的代码就可能会暴露出问题。
线上服务的运维和监控
前后端分离除了意味着代码仓库的分离、开发协作的分离之外,还涉及到线上服务的独立发布和单独部署。与之俱来的当然是前端如何更好地对线上服务进行更细粒度的运维和监控,我们的SA会更多的关注线上服务的整体指标和可用性,而前端更希望能够细粒度的了解线上Node的进程状态以及异常情况。
PM2是一款优秀且开源的Node进程管理工具。我们在PM2的基础上做了一些改造,同时在云端部署了数据收集、数据实时获取的服务,从而形成了我们目前已经应用到线上的Node部署监控平台PM2.5,它可以将线上Node服务进程级别的细粒度信息聚合在云端进行处理和可视化展现,PM2.5能够监控Node Server和进程的各项指标状态,且可以配置报警并在各终端(Web、iPhone、Apple Watch)展示。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%