算法优化的方法:避开鞍点
大小:1.3 MB 人气: 2017-10-11 需要积分:2
标签:算法优化(6215)
凸函数比较简单——它们通常只有一个局部最小值。非凸函数则更加复杂。在这篇文章中,我们将讨论不同类型的临界点( critical points) ,当你在寻找凸路径( convex path )的时候可能会遇到。特别是,基于梯度下降的简单启发式学习方法,在很多情形下会致使你在多项式时间内陷入局部最小值( local minimum ) 。临界点类型
为了最小化函数f:Rn→R,最流行的方法就是往负梯度方向前进∇f(x)(为了简便起见,我们假定谈及的所有函数都是可微的),即:
y=x−η∇f(x),
其中η表示步长。这就是梯度下降算法(gradient descentalgorithm)。
每当梯度∇f(x)不等于零的时候,只要我们选择一个足够小的步长η,算法就可以保证目标函数向局部最优解前进。当梯度∇f(x)等零向量时,该点称为临界点( critical point),此时梯度下降算法就会陷入局部最优解。对于(强)凸函数,它只有一个临界点(critical point),也是全局最小值点(global minimum)。
然而,对于非凸函数,仅仅考虑梯度等于零向量远远不够。来看一个简单的实例:
y=x12−x22.
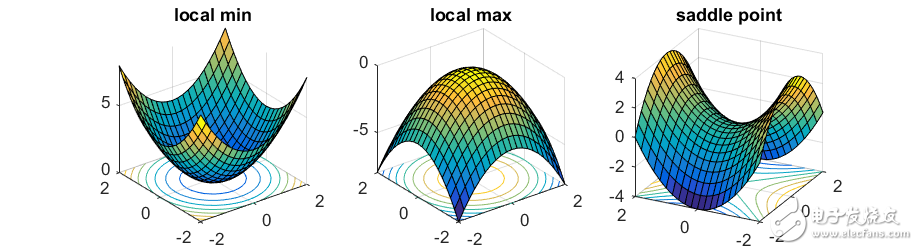
当x=(0,0)时,梯度为零向量,很明显此点并不是局部最小值点,因为当x=(0,ϵ)时函数值更小。在这种情况下,(0,0)点叫作该函数的鞍点(saddle point)。
为了区分这种情况,我们需要考虑二阶导数∇2f(x)——一个n×n的矩阵(通常称作Hessian矩阵),第i,j项等于
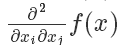
。当Hessian矩阵正定时(即对任意的u≠0,有u⊤∇2f(x)u 》 0恒成立),对于任何方向向量u,通过二阶泰勒展开式
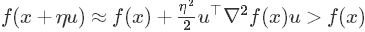
,可知x必定是一个局部最小值点。同样,当Hessian矩阵负定时,此点是一个局部最大值点;当Hessian矩阵同时具有正负特征值时,此点便是鞍点。
对于许多问题,包括 learning deep nets,几乎所有的局部最优解都有与全局最优解(global optimum)非常相似的函数值,因此能够找到一个局部最小值就足够好了。然而,寻找一个局部最小值也属于NP-hard问题(参见 Anandkumar,GE 2006中的讨论一节)。实践当中,许多流行的优化技术都是基于一阶导的优化算法:它们只观察梯度信息,并没有明确计算Hessian矩阵。这样的算法可能会陷入鞍点之中。
在文章的剩下部分,我们首先会介绍,收敛于鞍点的可能性是很大的,因为大多数自然目标函数都有指数级的鞍点。然后,我们会讨论如何对算法进行优化,让它能够尝试去避开鞍点。
对称与鞍点
许多学习问题都可以被抽象为寻找k个不同的分量(比如特征,中心…)。例如,在 聚类问题中,有n个点,我们想要寻找k个簇,使得各个点到离它们最近的簇的距离之和最小。又如在一个两层的 神经网络中,我们试图在中间层寻找一个含有k个不同神经元的网络。在我 先前的文章中谈到过张量分解(tensor decomposition),其本质上也是寻找k个不同的秩为1的分量。
解决此类问题的一种流行方法是设计一个目标函数:设x1,x2,…,xK∈Rn表示所求的中心(centers),让目标函数f(x1,…,x)来衡量函数解的可行性。当向量x1,x2,…,xK是我们需要的k的分量时,此函数值会达到最小。
这种问题在本质上是非凸的自然原因是转置对称性(permutation symmetry)。例如,如果我们将第一个和第二个分量的顺序交换,目标函数相当于:f(x1,x2,…,xk)= f(x1,x2,…,xk)。
然而,如果我们取平均值,我们需要求解的是
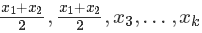
,两者是不等价的!如果原来的解是最优解,这种均值情况很可能不是最优。因此,这种目标函数不是凸函数,因为对于凸函数而言,最优解的均值仍然是最优。
所有相似解的排列有指数级的全局最优解。鞍点自然会在连接这些孤立的局部最小值点上出现。下面的图展示了函数y = x14−2x12+ X22:在两个对称的局部最小点(−1,0)和(1,0)之间,点(0,0)是一个鞍点。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%