详解OpenStack虚拟机的资源调度错误排查
大小:0.8 MB 人气: 2017-10-11 需要积分:1


本文将基于OpenStack最新release的liberty版本,分析OpenStack的虚拟机资源调度服务nova-scheduler的调度流程,并逐步说明OpenStack管理员在进行资源调度的错误排查过程中的尴尬境遇,然后提出一个OpenStack资源调度错误排查的改进方案,最后,本文会为大家展示IBM PRS(Platform Resource Scheduler)基于此方案的实现版本。
OpenStack虚拟机的资源调度
OpenStack对虚拟机的资源调度由nova模块的nova-scheduler服务实现,根据调度策略的不同,有两个插件:基于filter的调度和基于随机策略的调度,其中基于随机策略的调度仅对正在服务的host随机选择,不进行任何资源审查,在实际生产环境中基本上不会用到,所以本文仅就OpenStack的默认的调度策略:基于filter的调度进行分析。如图1所示,该策略主要通过三步完成虚拟机的资源调度返回候选host:

图1.基于filter的调度workflow
Step 1: 获取所有host的信息,如果调度请求中要求忽略一些host(ignore hosts),就将这些host从本次的候选host中删除掉(一种特殊的情况是如果调度请求中要求虚拟机只能调度到一些host或者节点上,则只保留这些host作为候选host,不会对这些host做进一步额外的资源审查即step 2便直接返回)。
Step 2: 将第一步中返回的host列表依次迭代地通过scheduler_default_filters配置的所有filter的host_passes处理函数,该函数会过滤掉不满足相应filter条件的host。
Step 3:对第二步返回的host列表根据scheduler_weight_classes配置的weigher对候选host进行排序。
至此调度服务完成对虚拟机的资源调度,nova-conductor服务将会向调度服务选出的host所对应的nova-compute服务发出虚拟机部署请求。由于OpenStack调度服务固有的race condition,当虚拟机在compute节点部署失败时,相应nova-compute服务将会向nova-conductor服务发送重新部署对应虚拟机的请求,用户可以通过scheduler_max_attempts配置最多可以容忍compute部署失败的次数,该reschedule机制如图2所示:
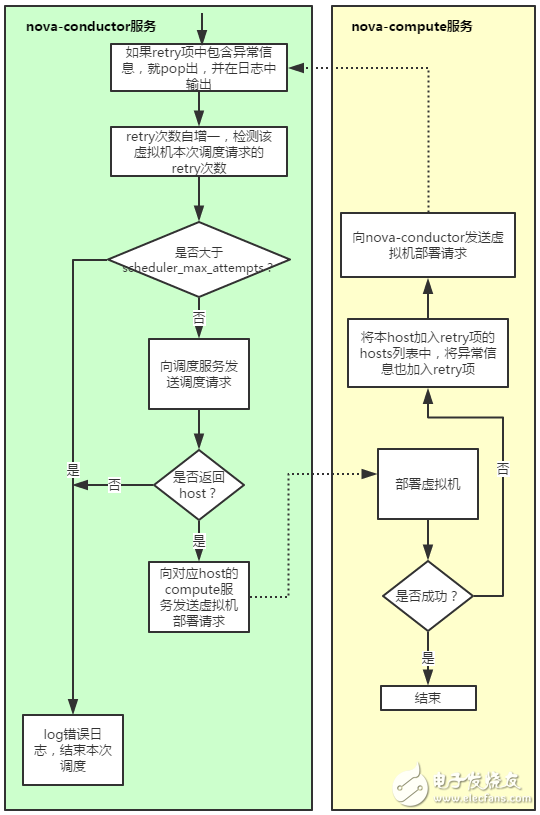
图2.OpenStack资源调度的reschedule机制
由上可知,当我们在部署一个虚拟机的时候,本质上有两类型的错误可能导致部署失败:第一是调度服务发现没有host可以满足虚拟机的资源需求,第二是虚拟机在调度服务选出的目标host上部署时因为某种原因部署失败(如卷请求超时或者网卡创建失败等等)。我们在虚拟机部署失败的错误排查时,需要从这两类错误类型逐一排查。怎么查呢?当然是看日志(其实也可以首先通过nova show命令查看fault项,但基本上通过这个信息是看不出错误所在的),从图2可以看出,我们应该从nova-conductor的日志开始,然后根据对应错误信息决定下一步该看nova-scheduler的日志还是对应nova-compute的日志。下面举一个最简单的由第一种错误导致虚拟机部署失败的错误排查的例子来说明一下OpenStack原生资源调度的错误排查是如何让管理员望而生畏的。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%