Netflix数据管道的演进历程
大小:0.3 MB 人气: 2017-10-11 需要积分:1
数据是Netflix的中心,很多的商业决策和产品设计都是依据数据分析而做出的决定。在Netflix,数据管道的目的是对数据进行收集归纳和处理,几乎我们所有的应用都会用到数据管道。下面我们先来看看有关Netflix数据管道的一些统计数据:
每天约5000亿个事件,1.3PB的数据高峰时段约每秒800万个事件,24GB数据
我们用另外的Atlas系统来管理运营相关的数据所以它并没有出现在上面的列表中。
由于需求的变化和技术的进步,过去几年我们的数据管道发生了很大的改变。下面我们就来介绍一下。
V1.0 Chukwa数据管道
最初数据管道唯一的目的就是把事件信息上传到Hadoop/Hive。如下图中所示,整个架构是比较简单的。Chukwa收集事件信息并将sequencefile写入亚马逊S3,之后大数据平台部门会进一步处理并写入Hive。从事件发生到以Parquet格式写入Hive整个过程不超过十分钟,对于每小时甚至每天才运行一次的batch job来说已经足够了。

V1.5 能够进行实时处理的Chukwa数据管道
随着Kafka和Elasticsearch等技术的发展,公司内部对于实时分析的需求愈加强烈,我们必须保证处理所需时间在一分钟之内。
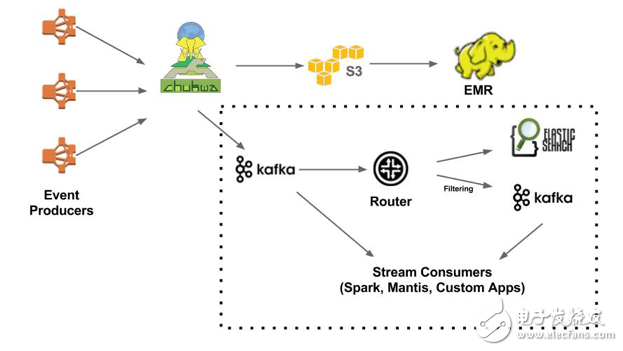
除了将数据写入S3,Chukwa还可以将数据发送到Kafka,新的实时分支(虚线框住的部分)处理的事件大约占到总事件的30%。处于实时处理分支中心位置的是事件路由模块,它负责将数据从Kafka传递到Elasticsearch和下一级Kafka(进行数据的筛选)。终端用户可以自由选择趁手的工具进行分析,比如Mantis、Spark或其他定制工具。
Elasticsearch在Netflix的应用过去两年经历了爆炸式的发展,现在共有约150个集群和约3500个节点,总数据量约1.3PB,而这其中大部分数据都是通过我们的数据管道采集处理的。
数据路由的部分是由我所在的小组管理的,下面是一些我们碰到过的问题:
Kafka high level consumer会丧失消息分区的所有权并停止读取一些分区,唯一的解决办法是重启。有时部署代码之后high level consumer在rebalance时会出错。我们有几十个集群用于事件路由,运营上的开销正持续增长,所以对于路由job的管理还要想个更好的办法。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
下载地址
Netflix数据管道的演进历程下载
相关电子资料下载
- 如何利用神经网络改善Netflix视频质量 260
- 智能制造——现代工厂如何打造“会思考的机器”? 727
- 亚马逊开源视效工具,Netflix、HBO都在使用 456
- 在哪里可以找到Netflix代码 756
- Netflix 宣布将投资 1 亿美元来提高其萤幕人才的多样性 1489
- 分析师:苹果公司最大的战略错误在于没有收购Netflix 1350
- 苹果最大的战略错误或是没有收购Netflix 1098
- Netflix或将推出Downloads For You功能 1514
- Netflix 表示:目前没有测试 AirPods Pro 和 AirPods Max 的空间音频支持 2362
- 谷歌 YouTube 和 Netflix 未来将支持 AV1 硬件解码 1911