一种新闻关键信息的提取算法
大小:0.87 MB 人气: 2017-12-13 需要积分:0


标签:提取算法(6816)
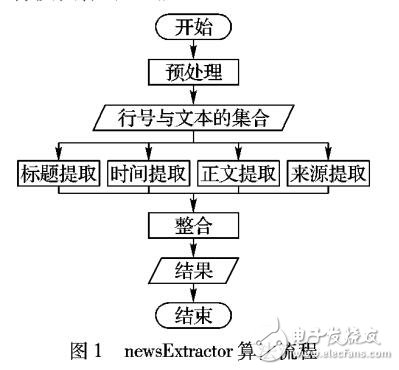
针对网页正文提取算法缺乏通用性,以及对新闻网页的提取缺乏标题、时间、来源信息的问题,提出一种新闻关键信息的提取算法newsExtractor。该算法首先通过预处理将网页转换成行号和文本的集合,然后根据字数最长的一句话出现在新闻正文的概率极高的特点,从正文中间开始向两端寻找正文的起点和终点提取新闻正文,根据最长公共子串算法提取标题,构造正则表达式并以行号辅助判断提取时间,根据来源的格式特点并辅以行号提取来源;最后构造了数据集与国外开源软件newsPaper进行提取准确率的对比实验。实验结果表明,newsExtractor在正文、标题、时间、来源的平均提取准确率上均优于newsPaper,具有通用性和鲁棒性。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
下载地址
一种新闻关键信息的提取算法下载
相关电子资料下载
- 分享一种基于深度图像梯度的线特征提取算法download 1001
- 面板AOI检测之ROI自动提取算法解析 3373
- 面向SLAM鲁棒应用提出了基于RGB特征点提取算法 949
- 折叠缺陷检测提取算法 989
- 剖析彩色视频运动目标自适应在线聚类提取算法 1307
- 一种使用快速行进水平集方法进行距离变换的三维中轴提取算法 2348
- 基于视频速度应用在FPGA上实现的结构光中心线提取算法 1254
- HanLP 关键词提取算法分析 374
- FPGA二值图像边界提取算法实现 3732
- HOG特征以及提取算法的实现过程 17599