 电子发烧友App
电子发烧友App



2023年,AI大模型实实在在地“从年头火到年尾”。自ChatGPT成为AI大模型的第一个“出圈”应用,以聊天机器人的形式展示出AI大模型应用的强大能力后,全球各大科技公司都在加速推动AI大模型的应用,当然也吸引了众多初创公司入局。一时间各种AI大模型涌现,无论是行业专用大模型还是通用认知大模型,都为更多创新的AI应用提供了技术支持。
但这种AI大模型背后的技术底层并不简单,它需要海量的数据、复杂的算法和强大的算力来支撑。其中,算力可以说是人工智能发展最大的瓶颈,也是当前AI大模型的核心竞争力之一。
如果有关注微软、谷歌、阿里巴巴、百度等国内外科技巨头的动态,你会发现这些企业去年都在大量订购GPU以及AI服务器等产品。有机构预计,AI大模型训练对于算力的需求未来将会以每3.5个月翻一番的速度增长,需求暴增驱动了芯片企业的更新迭代,算力芯片在近几年性能提升速度惊人。
去年11月,英伟达推出了当今全球最强的GPU芯片H200,Llama2 70B大模型训练的性能相比上一代提高近一倍。然而在大模型时代,受限于芯片制造的物理极限,晶体管密度的提升幅度越来越小,即使单颗GPU算力提升已经非常高,但远远无法满足大模型的训练要求。
在可预见的未来,先进封装以及芯片制造工艺所带来的芯片性能提升将越来越难满足AI大模型对算力的需求。于是在聚光灯下的算力芯片背后,高速互连技术开始被越来越多芯片企业和系统厂商所关注。
01. 高速互联技术——从“四路泰坦”到计算集群
相信资深的PC玩家大概率都听说过“四路泰坦”的传说,这是指在配备四个PCIe插槽的主板上使用了四块“泰坦”显卡(这是当时最强的旗舰级显卡型号),通过英伟达一种名为SLI的特殊互连技术将这四块显卡连接起来以大幅提升游戏图形性能。
后来AMD也推出了与SLI类似的CrossFire(交火)技术,可以将不同型号的AMD显卡连接起来,提升图形性能。这是在PC领域,单个GPU性能有限的情况下,所出现的一种解决方案之一,同时也是高速互连技术的应用之一。
后来,因为PC端游戏的性能需求,已经被快速迭代的GPU性能所满足,“多卡交火”在游戏中的实际性能也因为适配和性能损耗等问题提升不明显,这种玩法随后逐渐在消费级市场上被淘汰。
但前面我们也提到,尽管AI芯片算力近年提升神速,但在AI大模型训练中仍是微不足道。为了给大模型训练提供更强大的算力,业界所选择的解决办法是:类似显卡“交火”般,将多个AI加速卡连接起来。
在大模型训练应用中,往往会将几百个甚至是上千个AI加速卡连接在一起,形成一个整体的系统,才能够运行GPT、PaLM等大模型。
如此庞大的算力资源,首先遇到的瓶颈就是互连的通信效率。如果将AI算力系统看成一条工厂的流水线,那么互连技术就相当于流水线上的传送带。传送带移动速度太慢时,即使AI芯片产出的数据再多,都只会堆积起来,无法及时输送到下一颗芯片上,从而限制整个工厂的效率。
所以,要怎样将算力硬件连接起来,怎样将这些算力资源更好地进行分配,实现运算效率最大化?
问题的关键,首先要从单个服务器内部芯片的高速互连开始解决。
实际上,在计算机系统中,包含了CPU、GPU、内存、存储设备等组件,这些组件都无法各自独立运行,一般需要通过互连协议相互连接,进行通信和数据传输,才能够协同完成计算工作。
比如PCIe作为最常见的高速互连标准之一,被广泛用于CPU、GPU之间的高速互连。2003年PCI-SIG发布了PCIe 1.0规范,支持每通道传输速率为 2.5GT/s,最大总传输速率为4GB/s。在此之后的每一个版本迭代中,PCIe的传输速率都会以翻倍的速度增长,到2022年发布的PCIe 6.0规划中,每通道传输速率已经提高至64GT/s。
然而大规模计算集群的互连,对带宽、延迟、数据传输效率等都有更高要求,因此在PCIe之外,从2016年开始,各大芯片厂商都开始下场推出自家的服务器内部高速互连解决方案:英伟达在2016年推出了SLI的“高级版本”——NVLink,令多个GPU绕开PCIe直接进行互连,目前最新的NVLink 4.0已经可以实现900 GB/s的总双向带宽;AMD在2016年也推出了Infinity Fabric技术,外部带宽可以达到 800GB/s ;英特尔在2019年发布了基于PCIe协议的开放性高速互连协议CXL1.0,主要是打通了CPU和其他设备的内存共享,支持CPU与其他加速器之间的高速互连,满足异构计算要求,最新的CXL 3.0通过x16链路可以实现256GB/s的双向带宽。
可以发现,这些高速互连协议一般是由头部芯片企业主导,但问题在于,近年来随着算力需求的爆发,不断有新玩家投入开发GPU、AI加速卡等产品。有数据显示,全球范围内已经有上百家公司布局GPU、AI加速卡领域,仅在中国就有60多家公司推出了各自的AI加速卡产品。
从好的角度看,新玩家的加入能够为市场带来更多的产品选择,针对不同应用也能够更容易选择到合适的产品。但另一方面,AI算力系统与传统的CPU服务器的通用解决方案不同,AI算力系统本身是一种深度定制化的系统。
各种形态的AI加速卡背后,是各大厂商采用了不同技术路线、不同产品定义,这导致了这些AI加速卡无法兼容通用平台,需要各自定制硬件平台。深度定制带来的副作用就是,从芯片到算力系统,开发周期长、研发成本高,对于计算系统的高速互连拓扑架构设计、PCB设计以及制造工艺都要不断突破与创新,这为AI服务器的性能提升带来了不小的挑战。
正因为如此,在大模型时代,业界亟待有一个开放的AI芯片设计规范,在芯片端或是AI加速卡等算力硬件端开始进行定义,以支持更强的算力硬件互连,创造出更强的AI算力系统。
02. 卡间互连速率翻倍,OAM标准要一统AI服务器?
早在2019年,开放计算组织OCP就成立了OAI(开放式加速器基础设施)小组,包括Meta、微软、百度与浪潮信息等宣布联合制定OAM(OCP Accelerator Module开放加速模块) 标准,用于指导 AI 硬件加速模块和系统设计。
而OAM标准,就是为了解决上述提到AI加速卡硬件互相不兼容等一系列问题,提供一套指导AI硬件加速模块和系统设计的标准,定义了AI硬件加速模块本身、互连速率、互连拓扑、主板、机箱、供电、散热以及系统管理等系列设计规范。
在互连速率方面,基于OAM规范能够实现四阶脉冲调制方案(PAM4,4-Level Pulse Amplitude Modulation即四电平脉冲幅度调制)的单通道56Gbps高速信号互连速率。而在不归零编码 (NRZ, non-return-to-zero line code)码型下,PCIe 5.0最大只支持32Gbps的传输速率。
具体来说,OAM1.0规范下GPU之间支持多种高速互连通信协议,这些通信协议的物理层大多是基于以太网协议或者PCIe协议,其中基于以太网协议能够支持56Gbps的互连速率,基于PCIe则最高支持PCIe 5.0,也就是32Gbps。
OAM的出现,得到了业内众多企业的支持和参与,包括大家耳熟能详的英伟达、英特尔、AMD、微软、阿里巴巴、谷歌、浪潮信息等AI芯片企业、互联网企业、系统厂商等,大有一统AI服务器的趋势。 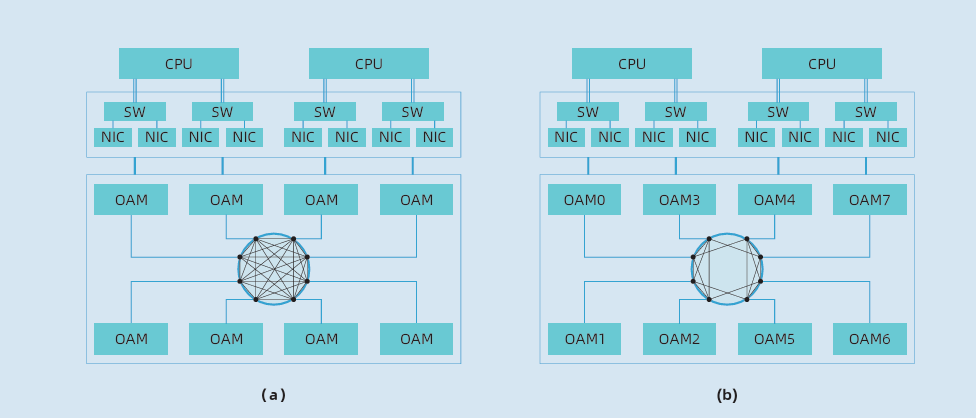
开放加速计算节点系统架构: 主流OAM互连拓扑 (a) FC (b) HCM
值得一提的是,其中作为系统厂商中的一员,浪潮信息第一个实现了符合OAM规范的8卡互连的AI系统,首次提供了全互连(Fully-connected)和混合立体互连HCM (Hybrid Cube Mesh)两种互连拓扑。
业界主流AI服务器大多为8卡互连,主要采用的拓扑架构有全互连和混合立方互连两种。根据不同的神经网络模型应用,两种互连拓扑各有优势,但针对大模型应用,全互连拓扑会更有优势。
简单来说,我们将单一服务器中的加速卡标号为0到7,全互连拓扑架构中每一张加速卡互相之间都能够进行通信,比如0号跟1号到7号加速卡都能直接进行通信;混合立方互连拓扑架构中,0号到7号加速卡之间通过组成一个或者多个双向环的方式进行通信,加速卡彼此之间都只能跟附近两张加速卡进行通信,比如0号可以跟7号和1号直接进行通信,7号可以直接跟6号和0号进行通信。
从上面的描述中很容易能够感知到全互连拓扑会相对复杂,事实也确实如此。相比其他厂商采用的混合互连拓扑架构,全互连的拓扑设计在同样的PCB材料叠层内,高速信号的总线长度是其他混合互连结构的一倍,这对PCB的设计和制造,带来了新的挑战。
03. 从56G到112G,高速互连带来的新挑战
在OAM标准实现了高速互连系统的各种设计规范后,基于OAM规范,更复杂的拓扑设计,更高的互连速率,都给PCB的设计、选材和制造工艺带来了挑战。目前业界在探索OAM规范下从56G提升到112G的互连技术,而更高的信号速率,意味着信号在PCB中传输时,信号完整性和信号质量更容易受到干扰。
在服务器一般应用的PCB中,一般采用十层以上甚至数十层的设计,以承载复杂的电路拓扑。而要实现一个可支持8张OAM互连的基板,则需要20~30层的PCB。同时为了保证信号传输质量,又需要采用长度相等、相位相反的互补信号来传输同一个信号,以减少噪音和EMI(电磁干扰),也就是说所有走线的数量需要翻倍。同时走线的宽度和间距需要由始至终保持一致,如果在连接路径上有其他的布线或者焊盘、过孔等阻碍,就需要从PCB有限的空间内找到合适的路径,给设计能力带来很大挑战。
对于高速互连的PCB,实际上连接器的设计也会对系统性能造成很大影响,比如高速信号经过连接器时造成的损耗等,会降低信号完整性。据了解,为了保证112G高速信号完整性,浪潮信息的工程师根据更低损耗的连接器的各项SI特性,优化了信号走线布局,提高了连接器整体带宽。同时通过对背板连接器、网络接口,甚至线缆等进行仿真优化,有效保障了112G信号设计的可靠性。
为了实现112G高速互连,还需要在PCB的材料上下功夫,需要寻找更低损耗的树酯、玻璃纤维及更平滑的铜箔,以确保这些材料加工之后能够符合信号设计可靠度的规范。为此,浪潮信息调研了业界几乎所有的PCB板材,建立了一套完善的PCB材料电性数据库,包括针对铜箔平坦度、表面拉力、高温影响性、蚀刻制程误差、介电损耗等汇整了3000多笔宝贵的测试数据。
而基于这些测试数据,可以更有针对性地优化高速信号设计,最终损耗性能可优化提升8%,为112G高速互连技术的落地打下基础。
112Gpbs高速互连技术既需要科学的发散,也要做到工程的收敛:通过科学的发散寻找创新的可能性,通过工程的收敛寻找“可行性”。创新的可能性空间包括了材料、工艺、方法、管理运营等等,而可行性则是寻找“最大化或最小化”,是寻找最优解的过程。
04. 写在最后
算力系统就像由长短不一的木板组成的木桶,每个部件的发展程度各不相同,难免会出现一些短板。特别是应用于AI大模型的算力集群中,单一的算力芯片可能能够发挥100%的性能,但在系统中可能只能发挥80%。当将无数颗算力芯片看成一个整体时,这样的性能损耗叠加起来是巨大的,而高速互连技术,能够在很大程度上补足这方面的短板,激活算力硬件100%的性能。
可以说,在AI大模型的需求下,高速互连技术已经成为算力系统的新瓶颈之一,更高效的互连技术将有机会令算力集群达到前所未有的高度。当然,算力产业可能也会找到更加创新的算力解决方案。但毋庸置疑,高速互连技术在产业中占有的重要地位,未来将不亚于单一的AI芯片,高速互连技术加持的高性能算力集群能够持续推动AI大模型应用普惠,让AI应用落地变得更加轻松。
审核编辑:黄飞



















 工商网监
工商网监
评论