什么样的PCB板才叫高频板?什么样的PCB板才叫HDI板?他们跟普通的双面板有什么样的区别? 还有就是什么叫普通双面板?
2023-04-06 16:00:57
在不远的未来,借助传感器、3G无线和云计算技术,实现无时不在的人体健康监控。位于北京海淀区知春路希格玛大厦五层,在微软亚洲研究院朝东的一个办公区域内,微软资深高级研究员朱文武博士,带领一个6人小
2019-10-29 07:33:15
现在的机器人的电源网络架构都是什么样的呢?大家都有什么奇思妙想的方案,机器人如何才能向人类一样自己获得能量,这种学习能力如何培养?@lileinetnet @xiaoliu241
2016-10-11 10:43:03
视觉系统的发展趋势怎么样?3D视觉系统应用在哪些方面?未来的机器人3D视觉系统将会发生什么样的变化?
2021-05-11 06:40:14
FPGA功能如此强大,请问用FPGA能实现或者比较适合实现什么样的算法?
2024-05-26 20:18:05
FreeRTOS中断优先级和任务优先级架构:Cortex-M3版本:FreeRTOS V9.0.0前言:最开始,我并没有搞清楚什么是中断优先级和任务优先级,但看了部分资料后发现这两个并没有半毛钱关系
2022-02-08 06:36:37
Giga ADC目前已经广泛的应用于数据采集、仪器仪表、雷达和卫星通信系统;随着采样速率和精度的进一步提高,Giga ADC架构 是什么样的? Giga ADC中的输出杂散的形成原因是什么?有什么样相应的优化措施了?
2021-04-06 06:38:13
了解一下JavaScript的未来——ECMAScript5
2020-05-25 09:46:19
KVM延长器是什么样的设备?
2017-04-20 15:06:56
缓存,而 SL3另外还可在局域 L2 高速缓存中进行缓存。 为向软件执行提供快速通道,外部存储器同内部共享存储器一样,通过同一存储器控制器进行连接,而并非像在嵌入式处理器架构上所进行的传统做法那样
2011-08-13 15:45:42
LabVIEW串口 接收的信号是什么样的
2013-05-09 09:52:47
我想了解LabVIEW可为LAN提供什么样的接口与协议,与其他设备(如PLC,第三方测试仪器) 实现通讯,然后完成图形显示和数据存储的功能。麻烦大家啦
2012-09-09 11:37:40
Modules environment是什么样的软件?
2021-06-21 06:17:52
STM32异步通信帧格式是什么样的?
2021-12-16 07:56:12
STM32时钟管理是什么样的?
2021-11-23 07:29:32
while的三种使用形式是什么样的?
2021-11-02 08:35:34
【作者】:王敏建;【来源】:《电视技术》2010年02期【摘要】:介绍了FCSAN和IPSAN两种存储架构在全台网环境下构建存储局域网所能发挥的不同优势和特性,结合未来技术的发展方向,提出选择存储
2010-04-23 11:22:24
是基于os层来聊的。那么,在赤裸裸的单片机下的堆和栈是什么样的分布呢?以下是网摘:刚接手STM32时,你只编写一个int main(){while(1);}BUILD://Prog...
2022-01-25 07:07:39
未来的单片机将会呈现什么样的发展领悟?将会应用到什么?
2017-04-03 13:06:18
SSD是摒弃传统磁介质,采用电子存储介质进行数据存储和读取的一种技术,突破了传统机械硬盘的性能瓶颈,拥有极高的存储性能,被认为是存储技术发展的未来新星。
2019-10-16 08:13:50
基于SDN的OTN网络架构怎么样?
2021-05-24 06:43:01
大家好!一直在做基于RT-Thread的多任务程序开发,但是对于多任务的优先级该如何分配,并没有太多的经验。所以想问一下大家,在进行多任务程序的开发的时候,一般遵循什么样的原则?我目前的程序,任务
2023-02-10 14:14:44
`大家心目中的三防手机是什么样的,大家讨论一下,有什么样的功能要求和设计上的要求,求建议,QQ:2469053522 手机:***`
2015-12-28 14:03:23
如何为未来的系统选择最好的本地数据存储?
2021-05-17 06:31:18
我是初学者,实验板需要选择什么样的啊?
2012-11-20 13:17:50
射频(RF)采样的架构是什么样的?
2021-05-20 06:57:40
如何从异常中断返回?异常中断处理程序结构什么样?何为异常中断向量表?哪一种异常中断优先级最高?
2021-12-14 07:40:24
收发函数封装是什么样的?
2022-01-27 07:07:59
处理、存储和网络带宽要求。对于数据密集型工作负载现状(例如大数据、快数据、分析、人工智能和机器学习)而言,“大而全”的方法已不再适用。目前面临的挑战是,如何能够更好地实现资源融合,以实现存储和网络带宽可以独立扩容。最终目标是构建灵活且可有机组合的基础架构,能实现混合并且弹性部署。
2019-07-29 06:28:17
数字控制环路的智能电源解决方案使从电网电力到能源存储的AC/DC能源转换,以及将存储能源或太阳能板采集到的能源转换为AC负载的DC/AC能源逆变系统受益。全新器件将有可能实现高效双向的能源转换。未来,楼宇将安装
2019-03-11 06:45:06
你碰到过的最难调试的 Bug 是什么样的?
2020-06-10 13:32:04
机甲大师机器人是什么样的?
2021-11-22 06:27:24
单片机编程,C语言简单,明白,汇编运行快点,不过这个优势应该越来越弱了,以后学汇编还有用吗?能适用什么样的场合啊?
2012-08-25 22:42:00
最近两年,不知道是不是受疫情的影响,好像每个人都在聊物联网,聊无接触,聊各个行业的物联网解决方案,聊物联网硬件,它的未来趋势到底怎么样,会更倾向于哪个方面
2021-08-21 09:58:20
最近两年,不知道是不是受疫情的影响,好像每个人都在聊物联网,聊无接触,聊各个行业的物联网解决方案,聊物联网硬件,它的未来趋势到底怎么样,会更倾向于哪个方面
2021-08-24 09:57:27
电脑电源怎么样啊,什么样的最好?
2015-01-15 17:17:27
电脑电源怎么样啊,什么样的最好?
2015-01-16 10:34:13
蜂窝手机音频架构的未来发展趋势是什么
2021-06-08 06:31:58
请问OLED、QLED究竟什么样?
2021-05-31 06:10:11
` 本帖最后由 gk320830 于 2015-3-8 16:13 编辑
这由LM324组成的放大电路,是什么样的放大电路,和一般的放大电路有点不同,求各位大侠指点,这是如何执行放大工作的`
2013-02-02 10:18:37
HBase是什么?HBase的存储结构究竟是怎样的呢?面向列的HBase存储结构究竟有什么样的不同之处呢?
2021-06-16 06:52:03
越来越多的电子产品利用高速信号技术来进行数据和语音通信、音频和成像应用。尽管这些应用类别处理的信号具有不同带宽,且相应使用不同的转换器架构,但比较候选ADC(模数转换器)及评估具体实施性能时,这些应用具有某些共同特性。想请教大牛,高速ADC的交流特性是什么样的? (eechina)
2021-04-06 08:24:40
什么样的示波器适合你?示波器自从问世以来,它一直是最重要、最常用的电子测试仪器之一。由于电子技术的发展,示波器的能力在不
2009-07-01 15:57:31 995
995 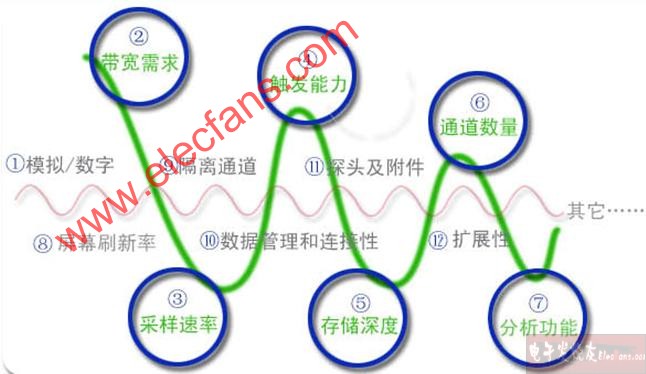
3g手机是什么样 3g手机是什么样的手机 还有现在说的3G是什么...3g手机是支持WCDMA、CDMA2000和TD-SCDMA其中一个制式的手机 支持视频通话、高速上网 3G,全称
2010-01-20 09:46:221691
家庭影院选择什么样的投影屏幕好?
2010-02-06 14:03:542329 什么样的冰箱没有霜
什么样的冰箱比较容易结霜,什么样的冰箱在这方面就会好些?使用中要注意哪些问题呢?
风冷冰箱不易结霜
2010-02-21 17:56:352272 未来环保汽车会是什么样?
一汽-大众
2010-04-07 09:08:531996 
ISO是什么样的组织?
ISO是一个国际标准化组织,其成员由来自世界上100多个国家的国家标准化团体组成,代表中国参加ISO的国家机构是
2010-04-13 17:14:152543 ARM与英特尔x86架构之间的战争不断升温,英特尔x86地位难以撼动,但ARM架构有着明显的功耗优势,什么样的CPU最适合未来的需求?
2013-03-14 11:31:372477 
云存储(或数据存储即服务)是对接口后的存储的抽象,可在该接口内按需管理存储。此外,接口抽象化存储的位置,这样一来,不管存储是在本地还是远程(或混合)都无关紧要。云存储基础架构引入新的架构,能够支持为
2017-10-11 16:44:58 6
6 我是 Github 的一名高级工程师。我不是要找工作,只是一直在思考领导能力的问题,思考在我多年共事过的诸多领导之中,我最欣赏的特质是什么。受到 Chad Fowler 的文章《我想雇什么样的员工》的启发,我也开始留意我想为什么样的领导工作,即——理想的领导是什么样。
2018-07-25 15:04:002782 。AI未来将如何变革工厂?在未来的工厂会有哪些用例?理想与现实的差距在哪里?工厂实施AI应该采取什么样的策略?
2018-05-19 10:25:5211563 现如今人们不论各个行业都是争先恐后的去学习编程进去 IT 但是 IT 行业到发展前景如何,今天就给大家带来:IT 行业的未来是什么样。
2018-08-02 09:44:078442 造成的拖累,跨越“存储墙”对于芯片性能提升的障碍已成为半导体行业广泛探讨的话题。而当“存储优先架构”(SFA)解决方案被提出来,我们似乎找到了开启未来AI芯片性能提升的金钥匙。
2018-12-26 16:19:172182 动驾驶汽车未来感十足,尽管人们耳熟能详,但在日常生活中还不常见。在博鳌亚洲论坛2019年年会举办期间,一汽、百度等公司亮出各自的自动驾驶技术,同台竞技。乘坐自动驾驶汽车到底什么感觉?未来的汽车会是什么样的?
2019-04-01 15:13:491693 RFID未来发展趋势是什么样的
2019-08-20 09:56:395381 现在在全球,工业机器人的市场正在蓬勃发展,根据预测,到2020年全球工业机器人年销量将增至231.8亿美元。那么在未来工业机器人会有什么样的发展趋势呢,今天我们来分析一下。
2019-09-11 10:30:411637 5nm工艺问世,CPU工艺与性能是一种什么样的关系
2020-01-09 14:03:045428 中国人发明的代码,你知道是什么样的吗?
2020-01-13 16:48:076815 未来网络架构会是什么样的呢?可能乍听之下与我们普通人的生活没有那么大的关系。
2020-03-16 16:26:333397 未来的教室会是什么样子?它将如何工作?通过物联网和相关技术框架连接教育设备和空间是未来学习环境的重要组成部分。未来学校朝着更具协作性和丰富性的教育体验的方向发展,这将有利于所有人。
2020-05-27 10:12:351297 电子发烧友网站提供《太赫兹技术在安检中有什么样的应用.pdf》资料免费下载
2020-11-26 10:27:001 蓄电池修复这一行到底能不能干?什么样的电池可以修复?什么样的电池不能修复? 电动车电池报废的原因多种多样: 1、与生产厂家的制造水平有关; 2、蓄电池配合的设备质量好坏也不同程度的影响蓄电池性能
2020-09-08 14:52:143494 
未来的存储技术会是什么样子呢?对于基于NVMe的传统Flash技术,我们应该继续期望更高的容量。
2020-09-18 14:39:121599 今天来给大家谈谈人工智能能给我们带来什么样的好处?又有怎样的危害?
2020-10-18 11:10:5134232 今天,未来已来,科技赋能智慧生活的社区和城市,已经成为梦想成真的入口。 未来城市是什么样的?可能大大超出了我们的想象,近日举办的中国科技第一展第22届中国国际高新技术成果交易会(下文简称高交会)上
2020-11-23 14:44:476642 电子发烧友网站提供《MEMS在未来会面临什么样的挑战.pdf》资料免费下载
2020-11-26 01:42:005 电子发烧友网站提供《深度学习技术在医疗图像诊断中有什么样的应用.pdf》资料免费下载
2020-11-26 05:47:0016 和PCIe,走过近30年时光。其中Host发现与查找设备的方式却一脉沿袭,今天我们先来聊一聊PCIe设备在一个系统中是如何发现与访问的。 首先我们来看一下在x86系统中,PCIe是什么样的一个体系架构
2021-01-12 16:50:165624 本文档的主要内容详细介绍的是神经网络的介绍和在GIS中有什么样的应用说明。
2021-01-21 14:28:2919 你心目中的未来汽车是什么样?能够提供更丰富的沉浸式娱乐体验,可以更加智能地感知路况,拥有安全智能的自动驾驶功能……这些关于未来汽车的构想,都在逐渐成为现实。 数字座舱,坐拥未来 汽车已经成为工作
2021-06-18 18:12:333824 未来机器视觉有哪些方向? 随着技术的发展,机器视觉技术发展的趋势是什么样的呢?下面我们简单的分析下器未来可能发展的几个方向。 1、3D成像和机械手应用将继续扩大 工业自动化正在推动工厂生产线变得更加
2021-07-28 15:51:514293 激光雷达市场呈现什么样的发展特征?车厂对什么样的激光雷达供应商感兴趣?如何在激光雷达市场进行创业? 转载声明 本文转载自至《中国电子报》原创作者李佳师 不久前,位于底特律全球排名前五的某汽车制造商将
2021-10-15 11:55:408379 芯片是集成电路,它是一种微型电子期间或部件,很多人都好奇它是什么样的?接下来一起了解下:
2021-12-13 17:29:5237314 区存储系统业务单元市场主任张畅、安富利现场应用工程师刘浚 将解读高性能存储解决方案如何助力工业应用智能升级的话题。 究竟什么样的存储方案可以满足工业需求呢? 《英飞凌高性能存储在工业应用的全面解决方案》研讨会给你答案! 扫描
2023-04-06 23:25:051132 
只有在堆内存里面才会发生内存泄漏的问题,在栈内存中不会发生内存泄漏。因为栈内存在自动分配空间之后,还会自动释放空间。 什么是堆内存?存储方式是什么样的呢? 首先我们先来介绍一下堆内存在 C 代码中
2023-06-22 10:29:001733 
点击“阅读原文”,了解更多华为数据通信资讯! 原文标题:交换机星品汇:强到飞起!未来网络需要什么样的核心交换机? 文章出处:【微信公众号:华为数据通信】欢迎添加关注!文章转载请注明出处。
2023-07-19 18:15:02953 
Chiplet的未来会是什么样子呢?它们可能会改变半导体行业的结构,将其从摩尔定律的束缚和少数代工厂的霸权中解放出来吗?或者,就像之前的薄膜混合物和multi-die封装一样,可能会分散到几个应用领域,风险和成本都是可控的。
2023-08-03 09:01:521591 一、高压开关长什么样?有什么种类?
二.高压开关有什么功能?
三、为什么断路器是高压开关中的No.1?
2023-10-13 10:29:461194 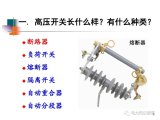
介绍倒装芯片封装选择什么样的锡膏?
2023-10-31 13:16:131615 
在存储信息时,对于动态存储器,行地址首先将RAS锁存于芯片中,然后列地址将CAS锁存于芯片中,当WE有效时,写入数据则被存储于指定的单元中。
2024-03-29 15:32:148491 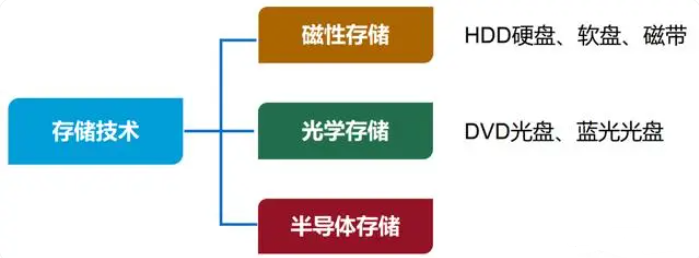
几个月前写了一篇文章“如何写出难以维护的代码”,从中能大概了解到不好维护的代码是什么样,有哪些坏味道,那肯定有人会反问,难以维护的代码见的太多了,也知道长什么样,但是对于好维护的代码是什么样的比较
2024-09-09 16:30:42919 
 电子发烧友App
电子发烧友App








 工商网监
工商网监
评论