2-13-数据库介绍及MySQL安装
2019-08-01 10:45:56
Delphi中数据库引擎BDE介绍Delphi对数据库的支持十分丰富,Delphi的数据库接口是数据库引擎BDE(Borland Database Engineer),它是应用程序存取数据的中介层
2009-05-10 11:09:21
是my_database}StoredProc1.StoredProcName:='my_proc';{数据库my_database 中存储过程的名称是my_proc }StoredProc1.Params.Clear
2009-05-10 11:09:47
一、H2数据库介绍 常用的开源数据库有:H2,Derby,HSQLDB,MySQL,PostgreSQL。其中H2和HSQLDB类似,十分适合作为嵌入式数据库使用,而其它的数据库大部分都需要安装
2021-12-17 08:03:38
1、HarmonyOS数据库篇之轻量级数据存储HarmonyOS中的数据库存储主要分为3种形式:1. 轻量级数据存储2. 关系型数据库的数据存储3. 对象关系映射数据库的数据存储2
2022-03-28 11:13:41
还可以打开SQL Server中的相应表并验证数据有没有更新成功。 图5七.总结: 本文向大家介绍了存储过程的基本知识以及在.NET数据库应用程序中如何结合
2008-12-31 16:54:53
采集电压数据,采样率为每通道1000点每秒,差不多100个通道,连续实时采集数据,然后同时要一秒存储一次数据,那么是采用access数据库方式存储,还是用利用tdms格式文件存储比较好?我个人觉得
2014-04-26 09:54:15
各位大神,我用labview的database对ACCESS数据库进行操作,我数据在数据库中存的太多想按日期删除,删除之后不是还得压缩数据库才可以释放数据库的存储空间。请问怎么用labview对数据库进行压缩?小弟在此非常感谢。
2013-11-15 09:29:45
运行周期非常快,当发送数据库写入命令后底层可能还没有执行完数据的存储,但由于运行周期太快所以已经到了读数据的指令,就会造成读取的数据不对。正确的办法是在数据库中存储了数据后不断检测0008的高字节,如果高字节清零了代表底层已经执行完了数据库的写入。再执行下一步,写数据库指令如下:`
2018-05-07 10:54:51
VI"(图2)将其转换为2进制流后存入数据库。但我在做从数据库调用数据(图3)时会比较慢,比如我存储的数据总量为大概80万条,那么我从数据库调用这些数据的时候处理处理时间可能会达到20秒以上。2.我的问题是:在存取大量的数据时,应该如何对数据处理后再存入数据库,以便使数据存取用时尽量的快?
2021-09-22 17:21:53
型数据库管理系统,它作为 Microsoft office组件之一,安装和使用都非常方便,并且支持 SQL 语言,所以本文将基于Access 来介绍LABVIEW在数据库中的的操作。 在利用NI公司
2014-06-29 21:08:48
1. 介绍轻量级偏好数据库是轻量级存储,主要用于保存应用的一些常用配置。它是使用键值对的形式来存储数据的,保存数据时,需要给这条数据提供一个键,读取数据时再通过这个键把对应的值取出来。说明轻量级偏好数据库
2021-10-09 14:43:12
用Delphi做数据库开发的介绍通过使用Delphi中BDE连接SQL数据库,掌握Delphi环境中数据库操作的最基本的方法和Delphi下数据库应用程序的开发方法。1、Delphi中数据库引擎
2009-05-10 11:09:03
请教:Labview采集的数据如何存储到GE Historian数据库中?刚接触NI Labview,烦请哪位高人指点一下,谢谢!
2016-11-01 11:10:58
时,数据库是灵活的,自治的,能快速从从故障中恢复过来。总结一下,现阶段,客户对数据库的要求是,弹性,低成本,高性能,业务永续性。 在新时代,数据是实时在线产生,收集,清洗,存储,分析的(即
2018-05-30 16:58:08
(2.2.0) 数据库的工具。ODX 是格式标准化的诊断数据库文件,我们在诊断不同的车或者不同的 ECU 时,加载适配这个车型或 ECU 的 ODX 文件即可,而无需对诊断
2022-03-30 13:48:44
创建数据库是实施数据库应用系统的第一步,创建合理结构的数据库需要合理的规划与设计、需要了解数据库物理存储结构与逻辑结构。数据库是表的集合,数据库中包含的各类对
2009-05-09 11:08:56 0
0 【摘 要】 介绍数据库复制在分布式数据库系统中的应用、设计和管理,给出了设计步骤和设计时考虑的因素。对设计和应用中出现的冲突问题进行了分析并给出了解决办法。对
2009-05-11 19:35:28 867
867 什么是关系型数据库
关系型数据库简介
关系型数据库以行和列的形式存储数据,以便于用户理解。这
2009-06-17 07:38:089324 什么是支持数据库
软硬件系统是否需要数据库支持,及所能支持的数据库类型,如SQL,Oracle,exchange。
什
2009-06-17 08:09:471077 数据库,数据库是什么意思
数据是当今信息社会的一种极为重要的资源,人们的一切活动都离不开数据。如学校中的学生档案、学习成绩记录、学
2010-03-18 15:05:225282 数据库已经在信息技术领域有了广泛的应用,我们社会生活的各个部门,几乎都有各种各样的数据库保存着与我们的生活息息相关的各种数据。作为数据库的一个分支,数据仓库概念的提出,
2011-02-16 18:02:483677 在JSP项目中,经常需要从数据库中取出数据把它显示在网页上,或者将网页上填写的数据输入到数据库中。但是在实际工作中,软件设计者常遇到数据库连接失败问题。由于设计者对数
2011-05-03 17:07:190 利用_NetApp_存储改善数据库环境
2016-12-28 11:13:110 对于公有云计算平台来说,只有计算、网络与存储这三大服务往往是不太够的,在目前互联网应用百花齐放的背景下,几乎所有应用都使用到数据库,而数据库承载的往往是应用最核心的数据。此外,在大数据分析越来越盛行
2017-10-11 16:42:460 有四大NoSQL类型:键值存储(key-value store),文件存储(document store),列导向的数据库(Column-Oriented Database)和图形数据库(graph
2017-10-12 17:24:372 嵌入式数据库无需安装,体积小巧,速度又很快,在很多场合可以替代目前流行的MySQL, SQLServer等大中型数据库。本文介绍两种嵌入式数据库产品:Berkeley DB和SQLite,并着重讨论
2017-11-06 14:05:320 经过一段时间的学习,也对数据库有了一些认识。数据库基本是由表,关系,操作组成;对于初学者首先要学的:1.数据库是如何存储数据的.表,约束,触发器2.数据库是如何操作数据的. insert,update,delete T-sql 函数 存储过程 触发器. 3.数据库是如何显示数据的.select
2017-11-28 17:36:144975 
hbase和关系型数据库的区别就是对于传统数据库,增加列对于一个项目来讲,改变是非常大的。但是对于nosql,插入列和删除列,跟传统数据库里面的增加记录和删除记录类似
2017-12-27 15:51:3715718 
本文主要介绍了目前流行的数据库以及构建数据库系统的流程。可以把数据库定义为数据的集合,或者说数据库就是为了实现一定的目的而按某种规则组织起来的数据的集合。数据库管理系统就是管理数据库的系统,即对数据库执行一定的管理操作。
2018-02-04 11:22:107426 数据库是指长期存储在计算机内有组织的、可共享的数据集合。数据库中的数据按一定的数据模型组织、描述和存储,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
2018-02-05 09:02:0714522 本文主要介绍了几种常见数据库的特点和区别。简单来说是本身可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据进行新增、截取、更新、删除等操作。以一定方式储存在一起、能为多个用户共享、具有尽可能小的冗余度的特点、是依照某种数据模型组织起来并存放二级存储器中的、与应用程序彼此独立的数据
2018-02-05 11:25:5528350 数据库引擎是用于存储、处理和保护数据的核心服务。利用数据库引擎可控制访问权限并快速处理事务,从而满足企业内大多数需要处理大量数据的应用程序的要求。 使用数据库引擎创建用于联机事务处理或联机分析处理数据的关系数据库。
2018-02-24 13:56:1222376 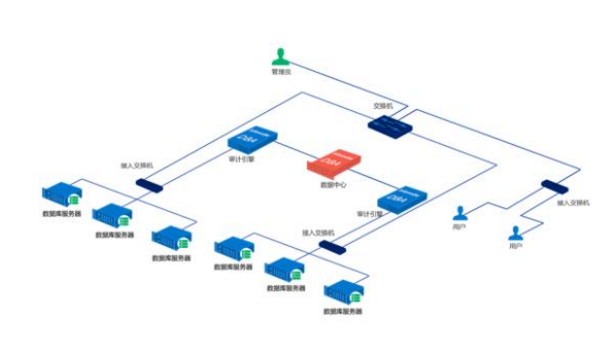
数据库引擎是用于存储、处理和保护数据的核心服务。利用数据库引擎可控制访问权限并快速处理事务,从而满足企业内大多数需要处理大量数据的应用程序的要求。 使用数据库引擎创建用于联机事务处理或联机分析处理数据的关系数据库。
2018-02-24 14:43:4612023 
本文开始介绍了数据库的原理与数据库特点,其次阐述了数据库的基本结构与数据库的数据种类,最后介绍了数据库的应用领域及常见的几种数据库。
2018-03-06 12:19:04122040 通常, 我们采用数据库来实现对数据的存储、检索等功能。像MySQL这类基于C/S结构的关系型数据库系统, 虽然代表着目前数据库应用的主流, 却并不能满足所有应用场合的需要。很多的应用,仅仅利用
2018-06-05 11:00:003176 关于数据库和区块链,总会有很多的困惑。区块链其实是一种数据库,因为他是数字账本,并且在区块的数据结构上存储信息。数据库中存储信息的结构被称为表格。但是,区块链是数据库,数据库可不是区块链。
2018-08-10 09:40:055876 
很多管理任务,利用一些常用的系统存储过程可以很方便的查看、操作数据库对象。系统存储过程的命名通常以”sp_”作为前缀,并且存储于Master数据库中,如果用户拥有足够的权限,就可以在任何数据库中调用这些存储过程。
2018-09-26 15:15:063 创建数据库的第一步是制订计划,该计划可在实现数据库时用作指南;也可以在数据库实现完成后,用作数据库的功能说明。数据库设计的复杂性和细节由数据库应用程序的复杂性和大小及用户数确定。
2018-09-27 15:32:445 本文档的主要内容详细介绍的是数据库教程之数据库的创建与管理详细资料免费下载。内容包括了:SQL Server数据库概述, 创建数据库,修改数据库,删除数据库,分离和附加数据库的资料免费下载
2018-10-19 10:41:1619 本文档的主要内容详细介绍的是数据库教程之如何进行数据库设计内容包括了:1 数据库设计概述 ,2 数据库需求分析 ,3 数据库结构设计 ,4 数据库行为设计 ,5 数据库实施,6数据库的运行和维护
2018-10-19 10:41:0021 本文档的主要内容详细介绍的是数据库学习教程之数据库的发展状况如何数据库有什么新发展主要内容包括了:1 数据库技术发展概述2 数据库发展的3个阶段3 数据库系统发展的特点4 数据库技术发展趋势
2018-10-25 16:29:285 本文档的主要内容详细介绍的是数据库系统概论之如何进行数据库编程的资料概述主要内容包括了:1、嵌入式SQL 2、存储过程3、ODBC编程
2018-11-15 15:12:2813 本文档的主要内容详细介绍的是数据库教程之关系数据库标准语言SQL的详细资料介绍主要内容包括了:1 SQL概述2 学生-课程数据库3 数据定义4 数据查询5 数据更新6 视图
2018-12-18 15:07:237 本文档的主要内容详细介绍的是数据库设计开发案例教程之数据库设计的资料介绍主要内容包括了:1 数据库设计概述,2 需求分析,3 概念结构设计,4 逻辑结构设计,5 数据库的物理设计,6 设计实例
2019-01-11 11:20:0017 逻辑存储结构是从逻辑的角度来分析数据库的构成的,是数据库创建后利用逻辑概念来描述Oracle数据库内部数据的组织和管理形式。在操作系统中,没有数据库逻辑存储结构信息,而只有物理存储结构信息。数据库的逻辑存储结构概念存储在数据库的数据字典中,可以通过数据字典查询逻辑存储结构信息。
2019-01-24 11:34:4713 本文档的详细介绍的是数据库教程之数据库的设计过程资料说明主要内容包括了:1 概念综述 ,2 定义任务陈述和任务目标 ,3 分析当前的数据库 ,4 建立表结构,5 码的概念 ,6 字段说明 ,7 表联系,8 业务规则 ,9 视图设计和集成,10 物理数据库设计
2019-02-20 14:05:4610 本视频主要详细介绍了数据库管理系统的功能,分别是数据定义、数据操作、数据库的运行管理、数据组织、存储与管理、数据库的保护、数据库的维护、通信。
2019-02-22 15:52:247029 本文档的主要内容详细介绍的是数据库教程之PHP访问MySQL数据库的理论知识详细说明包括了:1.phpMyAdmin的安装和使用,2.PHP操作数据库,3.MySQL的存储过程、触发器、游标和视图
2019-06-17 17:06:4615 数据库安全,是指以保护数据库系统、数据库服务器和数据库中的数据、应用、存储,以及相关网络连接为目的,是防止数据库系统及其数据遭到泄露、篡改或破坏的安全技术。
2019-06-24 17:23:502172 SQL Server CE 中的数据库是存储结构化数据的表集合。在可以存储数据库之前,必须创建数据库。在创建数据库之后,可以创建保存数据的表。
2019-09-19 11:28:375 实时数据库其实并不单单只是一个数据库,而是一个系统,包括对各类工业接口的数据采集,海量监测数据的压缩、存储及检索,基于监测数据的反馈及控制功能等。
2019-11-09 10:17:218852 云数据库是指优化和部署在云端的数据库,阿里云和腾讯云都提供云数据库,云数据库和自己搭建的数据库有什么区别?有必要使用云数据库吗?
2020-11-20 16:26:525255 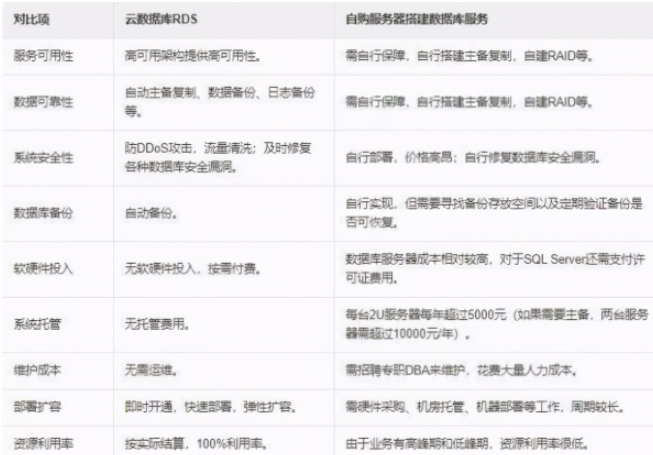
关于数据库和区块链,总会有很多的困惑。区块链其实是一种数据库,因为他是数字账本,并且在区块的数据结构上存储信息。数据库中存储信息的结构被称为表格。但是,区块链是数据库,数据库可不是区块链。
2020-12-25 18:55:131118 电子文件柜。在存储电子文件的地方,用户可以添加、截取、更新。并且以一定方式存储在一起,以及能够给予多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。 而数据库管理系统,则是为管理数据库而设计的电脑软件系统
2022-01-20 11:24:591320 MySQL端口可以从MySQL数据库中存储和检索数据。 概览 建立连接后,端口读取数据库中存在的表/视图(table/view)列表。通过选择一个可用的表并从该表中选择列来创建输入或输出映射。端口
2022-02-15 14:07:292175 数据库这个软件,名字中有个“库”字,会让人觉得它主要是为了存储的。其实不然,数据库实现的重要功能有两条:计算、事务!也就是我们常说的 OLAP 和 OLTP,数据库的存储都是为这两件事服务的,单纯的存储并不是数据库的目标。
2022-04-14 09:27:512059 写入的“一夫”节点性能大幅提升,如使用更快的CPU,增加更多的内存,使用将内存当做磁盘用的傲腾存储,使用IB网络(InfiniBand network)等。 但个体设备的配置提升,会遇到天花板。于是近年来有人提出将数据库进行分库分表,增加写入节点的数量而提升
2022-05-25 11:29:491442 数据库的规范与介绍
2022-06-16 14:12:510 数据库数据恢复环境:
某品牌存储存放大小约80TB的SQL SERVER数据库,数据库包含两个LDF文件,每10天生成一个500GB大小的NDF文件。
数据库故障&分析:
存储损坏,SQL SERVER数据库不可用。对数据库文件进行恢复后发现有几个NDF文件大小变为0KB。
2022-09-29 11:39:191972 
(for MySQL)为辅。 MySQL数据库是全球最受欢迎的一种数据库,它是属于 Oracle旗下的一款产品,MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大
2022-10-27 11:06:482225 华为云更可靠,技术强、创新快、资源多的特点。华为云采用了最新的DFV分布式存储技术,架构方面使用了计算存储分离架构,存储还最高支持128TB的海量存储,可以实现超百万级QPS吞吐,还支持跨AZ部署,故障秒级切换,既拥有商业数据库的性能和可靠性,又具备开源数据库的灵
2022-10-27 14:56:432048 MongoDB数据库存储方式是将文档存储在集合之中,而不是像Oracle、MySQL一样的关系型数据库。
MongoDB数据库是开源数据库,也提供具有附加功能的商业版本。
2022-12-06 11:46:191874 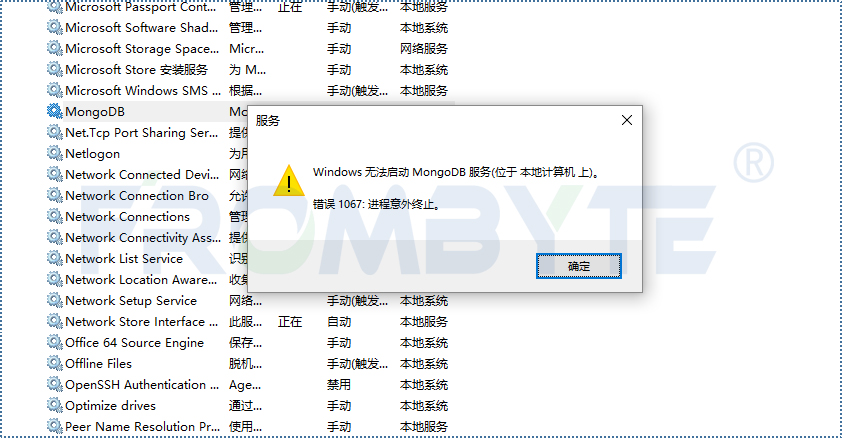
如今参与信息化的企业大多离不开数据库,但很多人对什么是数据库并没有一个清晰的认识。那么数据库到底是什么?传统数据库是根据某种数据类型组织起来并存放在二级存储器中的数据集合。但传统数据库存储量级有限
2022-12-27 16:52:311682 
数据库技术是贯穿信息技术发展的核心技术。数据库技术可为大数据的应用提供高效的存储和查询服务,可为大数据的应用提供可靠和安全的大容量信息。
2023-02-14 09:41:441424 列式数据库基于表存储,但没有严格的列格式。列式数据库不要求每一列都有值,而且可以组合包含不同数据格式的行段和列段。
2023-03-15 11:34:201566 电子存储和数据处理。数据库使数据管理变得容易。数据库示例:在线电话簿使用数据库来存储人员、电话号码和其他联系方式的数据。我们的电力服务提供商使用数据库来管理计费、与客户相关的问题、处理故障数据等。 数据库有哪些类
2023-05-10 16:35:521172 服务器和数据库之间的基本区别在于,服务器是运行以向其他计算机程序或设备提供服务的计算机程序。另一方面,数据库是以有组织的形式存储数据并且可以由用户在查询的帮助下检索的应用程序。在本文中,小编将和大家一起讨论服务器和数据库之间有何区别?
2023-05-26 17:28:323049 华为云数据库 GaussDB 是一款高性能、高安全性的云原生数据库,在数据库领域处于领先地位。而在 GaussDB 中,存储过程是一个不容忽视的重要功能。本文将深入介绍 GaussDB 存储过程
2023-05-30 09:52:292248 大数据时代的数据库
--数据采集、数据清洗和分析、数据可视化:提供决策依据
openGauss是一款高性能、高安全、高可靠的企业级开源关系型数据库,目前只支持Linux系统
GaussDB(for MySQL),是华为自研的最新一代企业级高扩展海量存储分布式数据库(云数据库)
2023-06-09 16:10:370 ,越来越多的企业采用数据库进行数据存储,进而实现数据的高效存储和管理。本文以MySQL数据库为例,介绍如何通过虹科OVL(OgammaVisualLoggerforO
2022-05-24 16:35:474150 
MongoDB的数据模型是针对文档的。所谓文档是一种类似JSON的结构。可以简单理解,MongoDB存储在数据库中的各种JSON,在MongoDB中称为“BSON”。 PetaExpress云数据库
2023-07-14 10:06:051089 数据库是一个存储关键数据的文件系统。利用数据库管理系统建立每个人的数据库可以更好地提供安全。 数据库建立|数据库创建的方法? 数据库是现代计算机技术中极其重要的组成部分。数据库是存储结构化数据的集合
2023-07-14 11:15:011976 分布式数据库是一种存储在不同物理位置的数据库。与单个数据库系统的并行系统不同,分布式数据库系统由不共享物理组件的松耦合站组成。分布式数据库具有可扩展性好、容错性强等优点,广泛应用于大型互联网企业或
2023-07-17 13:33:091124 云数据库和普通数据库区别? 一、云数据库和普通数据库的特点 1、云数据库的特点 它通过冗余存储和故障转移技术确保数据库在线和稳定运行。 2、普通数据库的优点 确保您的数据始终保持一致、原子性、隔离性
2023-08-01 17:13:091682 ,本文主要介绍如何激活虹科物联网HMI/网关的数据库功能。操作步骤根据产品软硬件方案的不同,数据库功能的激活方式也各不相同,接下来分别介绍虹科硬件方案(HMI/网关)
2023-08-01 00:05:401113 向量数据库是一种以向量嵌入(高维向量)方式存储和管理非结构化数据(如文本、图像或音频)的数据库,以便于快速查找和检索类似对象。
2023-08-16 10:13:083710 
SQLite数据库的特点 SQLite数据库简单介绍 SQLite数据库是一种轻型的嵌入式数据库,其最主要的特点在于其开源、免费和可嵌入的特性。SQLite既是一种嵌入式、关系型数据库,又支持SQL
2023-08-28 16:40:536465 SQLite数据库与python的区别 SQLite是一种轻量级关系型数据库管理系统,是一个嵌入式的数据库引擎。Python是一种高级编程语言,主要用于快速、简洁、易读的编写脚本、GUI应用程序
2023-08-28 16:41:221550 ,获取数据库中的数据,并对数据进行增删改查等操作。本文将详细介绍Python如何连接数据库、读取数据库数据以及如何进行查询操作。 一、Python连接数据库 Python连接数据库一般需要
2023-08-28 17:09:182658 数据库之前,您需要确定数据库的名称和使用的存储引擎。存储引擎是数据库系统中用于存储和检索数据的组件。 以下是使用SQL代码创建数据库的步骤: 1. 打开MySQL命令行。在Windows下,您可以使用Start菜单中的“MySQL Command Line Client”或运行MySQL.exe文件。
2023-08-28 17:09:433409 讨论MySQL数据库的管理和应用。 管理MySQL数据库 在管理MySQL数据库之前,我们需要了解基本的数据库概念和操作语言。MySQL使用SQL(Structured Query Language)语言进行操作。 1. 创建数据库 为了在MySQL中存储和管理数据,我们需要创建一个数据库。在MySQ
2023-08-28 17:15:261681 和管理的一项重要应用,其优点不仅可以提高工作效率,还可以保证数据的安全性和可靠性。本文将详细介绍数据库应用及其特点,同时探讨数据库数据的基本特点。 一、数据库应用的概述 数据库是指以某种特定方式组织管理、存储和检
2023-08-28 17:22:253745 对于大多数项目,用 MySQL 等关系型数据库来存储数据就足够了。但关系型数据库不是银弹!在某些场景下,比如要存储的数据间没有关系时,它并不是最佳的选择。
2023-10-13 10:20:371583 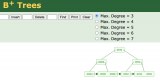
在数据库领域,Access是由Microsoft开发的一款基于Windows平台的关系型数据库管理系统(RDBMS)。它提供了一个使用简便的用户界面,可用于创建、管理和查询数据库。
2023-10-26 16:23:4916 MongoDB数据库是文档数据存储库,将文档存储在集合之中,不是像MySQL一样的关系型数据库。
2023-11-08 15:04:211471 
的基础知识,包括其架构、数据类型、表操作、查询语句和数据导入导出等方面。 MySQL 数据库架构 MySQL 数据库由多个组件组成,包括服务器、存储引擎和客户端等。MySQL 服务器是数据库的核心,它负责处理客户端的请求,并将数据存储在数据库中。存储引擎负责实际的
2023-11-21 11:09:531728 数据库。不管它是“nonSQL”的缩写,还是“notonlySQL”的缩写,大多数人都同意,NoSQL数据库是以关系表之外的格式存储数据的。NoSQL数据库之所以如此
2023-11-26 08:05:21995 数据库中decimal是一种用于存储精确小数的数据类型。在数据库中,decimal常用于存储货币金额、科学计算和需要精确计算的场景。本文将详尽、详实、细致地探讨decimal的定义、存储机制、应用场
2023-11-30 11:02:197293 MySQL是一个流行的关系型数据库管理系统,经常用于存储、管理和操作数据。在本文中,我们将详细介绍MySQL的基础命令,并提供与每个命令相关的详细解释。 登录MySQL 要登录MySQL数据库,可以
2023-12-06 10:56:411273 Idea的数据库被存储在许多不同的地方,取决于应用程序和使用的技术。下面将详细描述一些常见的存储Idea数据库的地方。 关系型数据库(RDBMS):关系型数据库是最常见的一种存储Idea数据的方式
2023-12-06 14:15:041709 数据仓库与数据库是两个在信息技术领域中常见的概念,它们在数据管理和分析方面发挥着重要作用。尽管它们在某些方面有相似之处,但它们在设计、目的和功能上存在显著差异。本文将介绍数据仓库与数据库之间的主要区别
2024-07-05 14:57:161465 一个运行在存储上的SQLServer数据库,有1000多个文件,大小几十TB。数据库每10天生成一个NDF文件,每个NDF几百GB大小。数据库包含两个LDF文件。
存储损坏,数据库不可用。管理员
2024-10-31 13:21:431099 
云数据库是一种部署在虚拟计算环境中的数据库,它融合了云计算的弹性和可扩展性,为用户提供高效、灵活的数据库服务。云数据库主要分为两大类:关系型数据库和非关系型数据库(NoSQL数据库),以下是UU云小编对两大类数据库类型的介绍:
2025-01-07 10:22:09858 数据库是现代信息技术中存储和管理数据的核心组件。字符串作为最常见的数据类型之一,在数据库中的存储方式对其性能和可扩展性有着重要影响。 数据类型 固定长度字符串 :如CHAR类型,它为每个字符串分配
2025-01-07 15:41:591338 关系型数据库和非关系型数据库在多个方面存在显著差异,主机推荐小编为您整理发布关系型数据库和非关系型区别,以下是它们的主要区别。
2025-01-10 09:58:351540 分布式存储数据恢复环境:
16台某品牌R730xd服务器节点,每台服务器节点上有数台虚拟机。
虚拟机上部署Hbase和Hive数据库。
分布式存储故障:
数据库底层文件被误删除,数据库不能使用。要求恢复hbase和hive数据库。
2025-04-17 11:05:58597
 电子发烧友App
电子发烧友App




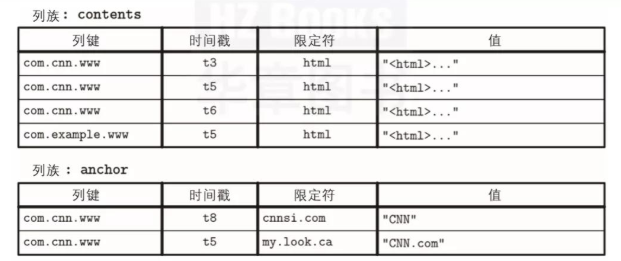





 工商网监
工商网监
评论