 电子发烧友App
电子发烧友App


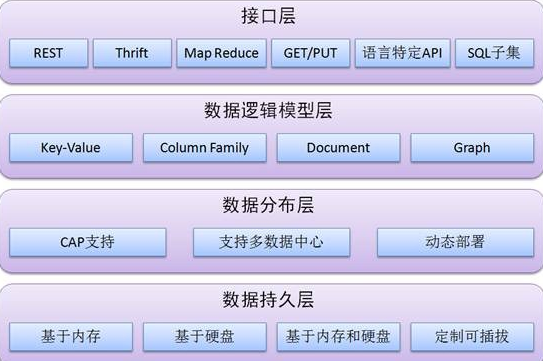
设计中存储资源的使用
不同的用户可能需要不同容量的RAM来构建他们的特定应用。所以FGPA底层的RAM基块大小就是一个有意思的话题。如果太大,则不够灵活,难以满足小容量的应用,当然可以直接用大容量RAM来实现小容量应用,但这难免造成大量的资源浪费;如果基块太小,则中等或者大型RAM应用会需要大量的小型RAM来构成,小型RAM为了普适性,也会配备同样的信号输入接口,这样一来则会大大消耗FPGA内部的布线资源,甚至会造成布线拥挤和时序问题。
几乎所有在 FPGA 中构建的设计都需要使用一定大小的内部存储器资源来存储系数、缓冲数据以及各种其他用途。典型系统需要小型、中型和大型存储器阵列的组合来满足它们的所dfe有要求,存储器的整体功耗因此成为设计的主要关注点。
在设计FPGA时,重要的是要创建满足大多数客户需求的器件。如果 FPGA是用适合一个 应用的小型、中型和大型存储器资源构建的,那么该解决方案对于某些客户来说将是最佳的,而其他想要使用相同部件的客户可能需要做出相当大的取舍。
试图从他们的 FPGA 中获得最佳价值的用户可能会担心大容量RAM 中的资源浪费。但是,构建更精细、更小的 RAM基块需要额外的连线,这是有代价的。本文解释了权衡取舍:为什么更精细的RAM基块的成本通常更高。
图 1 显示了 FPGA 中小型、中型和大型存储器块的理论分布(未按任何特定比例绘制)。
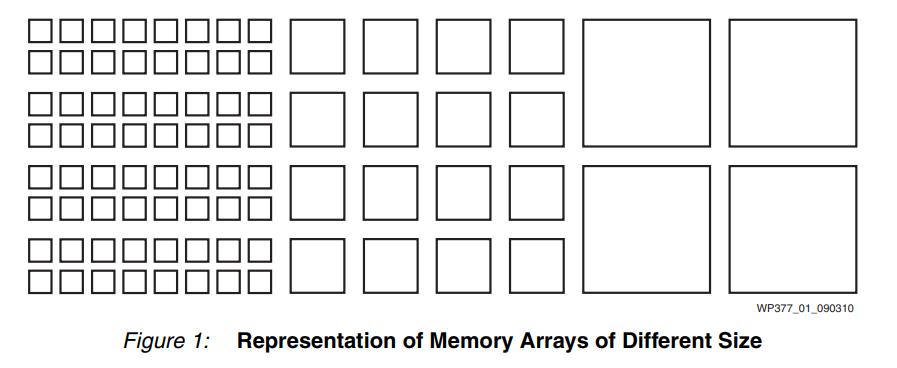
恰好需要这种块组合的设计能够完美地利用可用资源(参见图 2)。
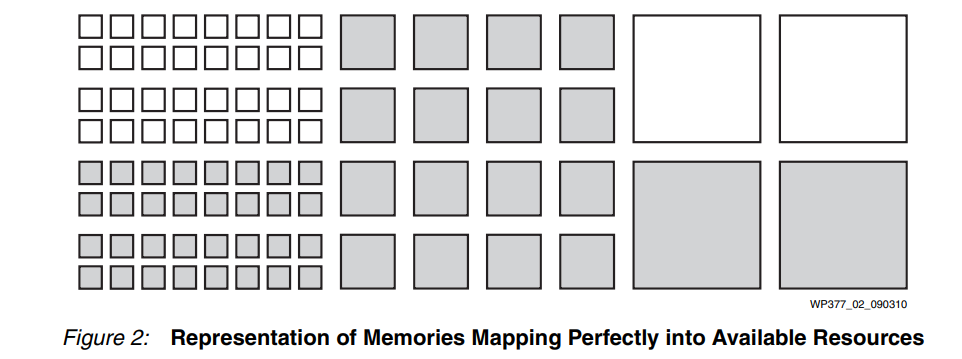
然而,想象一个场景----用户只需要另外四个中等大小的资源。
一种方法是用大量小组件构建中型内存阵列,这会消耗大量资源并导致将它们连接在一起的复杂性。另一种选择是使用一个大块作为中块,使大块中的所有剩余资源不可用,同时保持它们通电,因此会消耗功耗(参见图 3)。
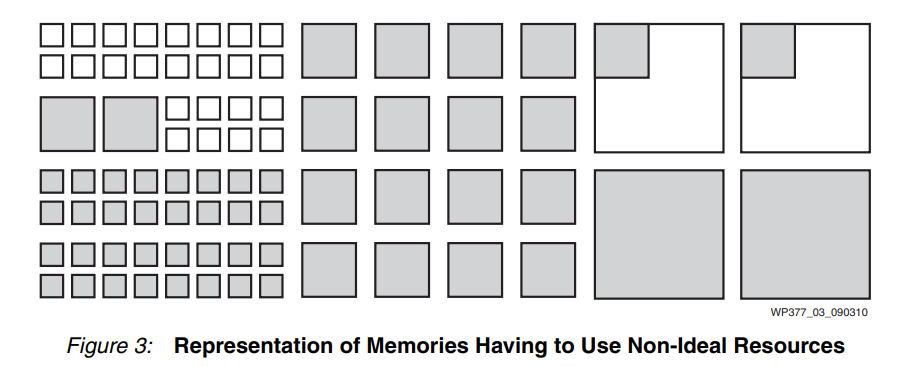
FPGA 制造商面临的挑战是构建具有最灵活的内存资源组合的设备,让所有用户能够将他们所需的内存阵列大小安装到设备中,同时实现所需的性能且不会浪费大量的资源和功耗。
FPGA 中的存储资源 这一章是对BRAM资源的讲述,更详细的内容可以看这里:从底层结构开始学习FPGA----Block RAM(BRAM,块RAM)
Xilinx FPGA 使用各种存储资源,以提供最好的灵活性和低成本组合。包括 Artix-7、Kintex-7 和 Virtex-7 系列在内的所有 7 系列 FPGA 都使用相同的内存块,从而能够从一个 7 系列 FPGA 系列完美迁移到另一个系列。
显然,构建存储资源以满足每个用户的需求是一项艰巨的挑战。Xilinx 7 系列 FPGA 中实现的解决方案是创建称被为 块RAM 的基块(参见图 4),这些块基块可以组合在一起形成更大的阵列,也可以分割形成更小的阵列。将块 RAM 与 FPGA 逻辑中的 6 输入查找表 (LUT) 组合成小型存储器阵列的能力为用户提供了最灵活的资源来创建各种大小的存储阵列。
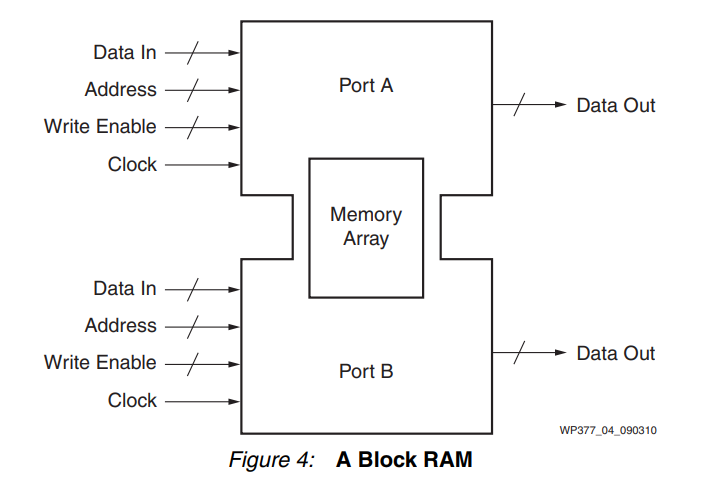
块 RAM 每个 7 系列 FPGA 有 135 到 1880 个双端口块RAM,每个 块RAM 能够存储 36 Kb数据,其中 32 Kb 分配给数据存储,在某些内存配置中,额外的 4 Kb 分配给奇偶校验位。每个 Block RAM 都有两个完全独立的端口,它们只共享存储的数据。
每个端口可以配置为:
32K x 1 16K x 2 8K x 4 4K x 9(或 8) 2K x 18(或 16) 1K x 36(或 32) 512 x 72(或 64) 每个 Block RAM 可以分为两个完全独立的 18 Kb Block RAM,每个 RAM 可以配置为从16K x 1 到 512 x 36 的比例。当一个 36K 块 RAM 被分成两个独立的块 RAM,两个独立的块RAM 中的每一个的行为都与一个 36 Kb 块 RAM 完全相同,只是大小变成了一半。
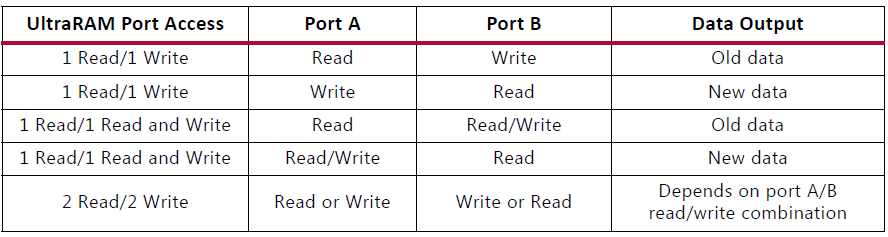
相反,如果用户需要更大的存储器阵列,则可以将两个相邻的 36 Kb 块 RAM 配置为一个级联的 64K x 1 双端口 RAM,而无需任何额外的逻辑与资源。Xilinx 7 系列 FPGA 中的 Block RAM 组件可以配置为单端口、简单双端口或真双端口模式。此外,可以通过以下三种方式之一从 Block RAM 读取数据:READ_FIRST、WRITE_FIRST 或 NO_CHANGE 模式。
拆分块RAM 如果用户只需要单端口存储器,而不是实现完全真正的双端口功能,则可以将块 RAM 分成更小的内存阵列。当 Block RAM 处于真双端口模式(默认模式)时,端口 A 和端口 B可以通过将 ADDRA 地址总线的最高有效位连接到VCC(高电平)来实现单独的、独立的延迟线存储器、单端口存储器或 ROM和 ADDRB 地址总线的最高有效位接地,因此创建两个单端口块 RAM。
例如,一个 RAMB36E1,36K 块 RAM 原语,可分为两个18K单口存储器,RAMB18E1可分为两个9K单口存储器。使用这种方法,可以在 7 系列 FPGA 中为每个 Block RAM 阵列创建四个延迟线存储器。要以这种方式在 Block RAM 中实现延迟线,必须使用 READ_FIRST 或 Read-Before-Write 模式。
如果实现单端口存储器,则允许的模式没有这样的限制;可以使用任何支持的模式(READ_FIRST、WRITE_FIRST 或NO_CHANGE),并且一个块 RAM 中的不同存储器可以具有不同的端口宽度。由此产生的存储器方案在每个时钟周期为每个端口执行一个操作,因此每个时钟周期每个块 RAM 执行四个操作。
同步操作 每次访问内存,无论是读取还是写入,都由时钟控制。所有输入、数据、地址、时钟使能和写使能都已寄存。没有时钟什么都不会发生。输入地址始终被时钟控制,在下一次操作之前保留数据。一个可选的输出数据流水线寄存器允许更高的时钟速率,但代价是额外的延迟周期。在写入操作期间,数据输出可以反映先前存储的数据、新写入的数据或保持不变。
字节宽写使能 Block RAM 的字节写使能特性提供了一次写入输入数据的八位(一个字节)的能力。真双端口 RAM 最多有四个独立的字节宽写使能输入。每个字节范围的写使能与一个字节的输入数据和一个奇偶校验位相关联。当使用块 RAM 与微处理器接口时,此功能很有用。
错误检测和纠正 Xilinx 7 系列 FPGA 中的每个 64 位宽块 RAM 可以生成、存储和利用 8 个额外的汉明码位(Hamming-code),并在读取过程中执行单位错误校正和双位错误检测 (ECC)。当写入或读取外部 64/72 位宽存储器时,也可以使用 ECC 逻辑。这适用于简单的双端口模式,不支持 read-during-write。
FIFO控制器 Xilinx 7 系列 FPGA 中用于单时钟(同步)或双时钟(异步或多速率)操作的内置 FIFO 控制器增加内部地址并提供四个握手标志:已满、空、几乎满和几乎空。几乎满和几乎空的标志是可自由编程的。类似于 块 RAM,FIFO 宽度和深度是可编程的,但写入和读取端口始终具有相同的宽度。首字直通模式呈现第一甚至在第一次读取操作之前,在数据输出上写入字。读完第一个字后,此模式与标准模式没有区别。
分布式内存(DRAM) Xilinx 7 系列 FPGA 的逻辑由 6 输入 LUT 等元素组成。LUT 以四个为一组排列,并组合成一个Slice。7 系列 FPGA 有两种Slice----SLICEM 和 SLICEL。SLICEM 中的 LUT 占 7 系列 FPGA 中 Slice 总数的 25-50%,可以实现为称为分布式 RAM 元素的同步RAM 资源。每个 6 输入 LUT 可配置为一个 64 x 1 位 RAM 或两个 32 x 1 位 RAM。SLICEM 中的 6 输入 LUT 可以级联以形成更大的元素,在简单的双端口配置中高达 64 x 3 位或在单端口配置中高达 256 x 1 位。请参见图 5。
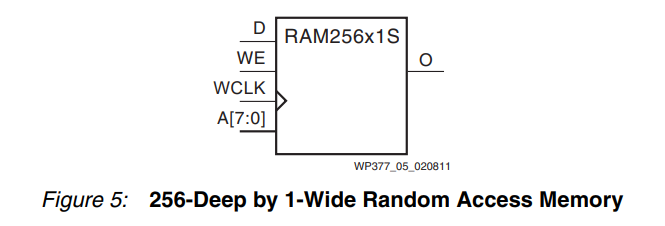
分布式 RAM 模块是同步(写入)资源。可以使用同一片中的存储元件或触发器来实现同步读取。通过放置这个触发器,分布式 RAM 性能通过减少触发器时钟输出值的延迟而得到改善。但是,会增加额外的时钟延迟。分布式元件共享相同的时钟输入。对于写操作,由 SLICEM 的 CE 或 WE 引脚驱动的写使能 (WE) 输入必须设置为高电平。
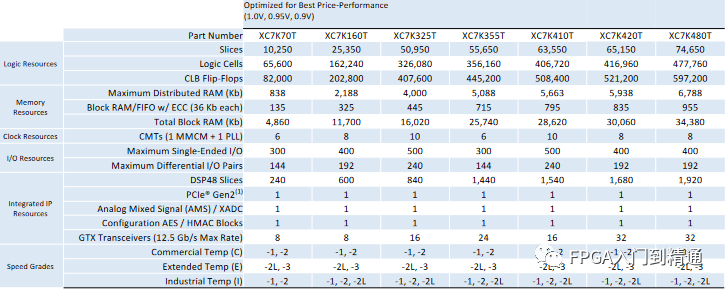
典型的用户设计利用 表 1 显示了针对 Kintex-7 XC7K410T FPGA 的典型存储高利用率设计中的资源映射。此数据基于关注比特浪费的用户的真实示例。

多个不同的资源利用了以不同大小配置块 RAM 资源的能力。
无穷小基块的代价 确定赛灵思 FPGA 架构提供了多种不同的存储器深度/宽度粒度后,了解向架构添加更精细基块所涉及的权衡非常重要。例如,如果 7 系列 FPGA 中的 36K 块 RAM 不仅分成两个 18K 块,而且可以进一步分成四个 9K 真双端口块,但这需要付出代价。将单个 Block RAM 中的唯一存储器数量加倍意味着要进出每个 Block RAM 的最大信号数量也需要加倍,这反过来又需要将互连资源(或块)的数量加倍以适应约 400 个信号的路由布线。 例如,一个 8K 块 RAM 可以配置为 16 位宽和 512 位深,总共需要 25 个输入信号----16 条数据线和 9 条地址线。然后 8K 块 RAM 分为两个 4K 块 RAM。这些块 RAM 中的每一个都可以配置为 16 位宽和 256 位深。此配置每个块 需要16 条数据线和 8 条地址线,每个 4K 块 RAM 总共有 24 个输入信号或总共 48 个信号。48 个信号大约是 8K 块 RAM 所需的 25 个输入信号的两倍。与每个关联的互连块数量增加一倍的效果 块 RAM 将硅面积增加了 25% — 无论使用何种配置,所有块都会受到惩罚。因此,每个 Block RAM 能够配置为四个 9K 块的能力意味着每个块从四个区域单元增加到五个区域单元。从积极的方面来说,它允许较小的存储器利用较小的块大小(参见表 2)。
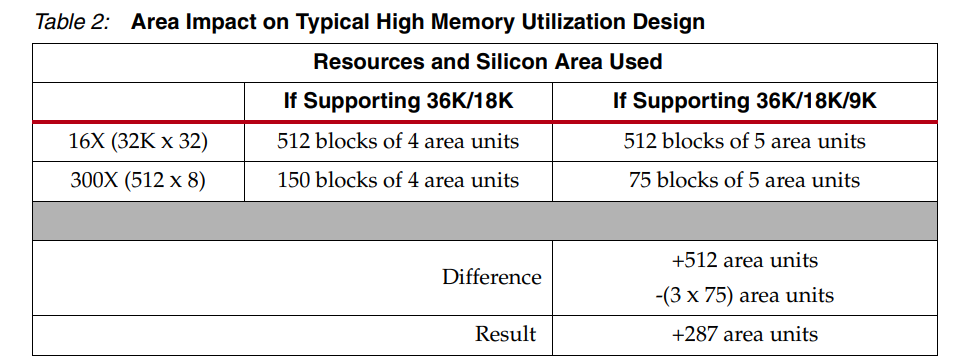
参考相同的设计示例,如果能够将较小的 512 x 18 内存有效地打包到相邻的 9K 块中,则其影响相当于消耗更少的资源。然而,较大的块都变大了 25%,增加了显着的面积损失。因此,如果 Kintex-7 FPGA 中的 Block RAM 可以划分为四个独立的存储器,并且用户设计可以充分利用这些更小粒度的块,那么这种典型设计仍然比当前的 36K/18K 配置占用更大的面积。然而,由于试图将如此多的信号连接到一个总线上的布线拥塞,设计不可能通过将四个独立的 9K 真正双端口存储器打包到同一个 36K 块 RAM 中来充分利用它们。因此,表 2 中的面积乘法是最好的情况;实际上,并非所有 36K 块 RAM 都将由四个 9K 存储器填充。
对设备资源的影响 块 RAM 资源大小增加的影响可能会在整体设备资源的中产生以下三种影响之一:
保持设备大小相同并丢失块 RAM 位 保持 Block RAM 的位数相同,减少其他资源的数量,即 CLB 让所有资源保持原样 让设备变得更大这些选择中的每一个都有明显的惩罚:
丢失块 RAM 位并不理想,因为大多数用户正在使用大部分可用内存。如果块 RAM 全部增加 25%,Kintex-7 XC7K410T FPGA 中的块数从 795 减少到 636,相当于从 28,620 Kb 减少到 22,896 Kb块 RAM 大小增加 25% 意味着每块 RAM 列损失一列 CLB。Kintex-7 XC7K410T FPGA 有 12 个块 RAM 列,因此在这种情况下,它会从设备中丢失 12 列 CLB,相当于丢失 4,200 个 CLB,这相当于大约 54,000 个逻辑单元。这将产生将 Kintex-7 XC7K410T FPGA 从 406,720 个逻辑单元减少到 352,720 个逻辑单元的影响,从而以相同的成本生产出功能更差的设备。保持所有资源相同并允许增加硅面积有几个缺点。显而易见的第一个问题是,更大的设备意味着更昂贵的设备,但物理上更大的硅片也会对功耗产生重大影响。Block RAM 阵列的功率优化 功耗的重要性 功耗在大多数现代应用中至关重要,降低系统内的功耗对每个设计人员来说都是一项挑战。降低功耗的方法有很多种,但很多都会伴随明显的性能损失。借助 7 系列 FPGA,Xilinx 采用了一种创新方法来降低与 Block RAM 存储器阵列相关的功耗。降低功率的两种主要方法是:
识别不必要地消耗功耗的区域并采取行动 提供在降低功耗与略微降低最大性能之间进行权衡的能力 未使用的 Block RAM 所有 Block RAM 组件在上电时都会消耗功率,无论它们是否在设计中使用。Xilinx 7 系列 FPGA 中的一项独特功能使软件能够自动识别未使用的 Block RAM。识别出未使用的Block RAM后,它们会自动禁用并进入零功耗状态,从而显着降低 FPGA 的整体功耗。
使用 XST(xilinx synthesis tools) 推断 RAM 模块 如果读取地址寄存在内,XST 会推断块 RAM。相反,如果 RAM 网络使用异步读取操作,则推断为分布式 RAM。ram_style 属性可用于指定是使用块 RAM 还是分布式 RAM。当 RAM 网络大于一个基块的大小时,可以使用多个 Block RAM。默认策略是针对性能进行优化。在此策略中,小型 RAM 使用分布式 RAM 实现。RAM 网络也可以针对功率和面积进行优化;这些在本文的使用 CORE Generator 软件构建 RAM 部分中进行了描述。任何小于 128 位深度或 512 位深度 x 宽度的东西都在分布式 RAM 中实现,除非用户使用 ram_style 属性另外指定。为了确保最有效地使用Block RAM 和分布式 RAM 资源,XST 首先在 Block RAM 中实现最大的 RAM, 如果仍有可用的块 RAM 资源,则将较小的 RAM 放入块 RAM。XST 还可以将小型单端口 RAM 打包到单个块 RAM 中。
可以在 XST 中启用降低 Block RAM 功耗的技术。它们是由功耗降低 (POWER) 综合选项控制的更大优化集的一部分,并且可以通过 RAM 样式 (RAM_STYLE) 约束专门启用。XST 中的 RAM 功率优化技术主要旨在减少设备上同时活动的 Block RAM 的数量。它们仅适用于需要分解多个 Block RAM 原语的推断存储器,并利用 Block RAM 资源的启用能力。创建额外的启用逻辑以确保仅同时启用一个用于实现推断存储器的 Block RAM 原语。为适合单块 RAM 原语的推断存储器激活功率降低技术没有效果。启用后,将结合区域和速度优化目标寻求降低功率。通过 RAM 样式 (RAM_STYLE) 约束可以进行两种优化权衡:
模式 block_power1 实现了一定程度的功耗降低,同时对电路性能的影响最小。在这种模式下,会保留默认的、面向性能的 Block RAM 分解算法。XST 只是添加了块 RAM 启用逻辑。根据内存特性,功率只能以有限的方式受到影响。 模式 block_power2 提供更显着的功耗降低,但可能对性能产生轻微影响。也可以引入额外的切片逻辑。此模式使用不同的 Block RAM 分解方法。该方法首先旨在减少实现推断内存所需的块 RAM 原语的数量。然后通过插入 Block RAM 使能逻辑来最小化活动 Block RAM 的数量。还创建了多路复用逻辑以从活动块 RAM 中读取数据。如果设计的主要关注点是降低功耗,而速度和面积优化是次要的,那么赛灵思建议使用 block_power2 模式。 ROM 可以通过使用大的 case 语句来推断。XST 还可以在 Block RAM 中实现有限状态机 (FSM) 和逻辑,以最大限度地利用可用的逻辑资源。
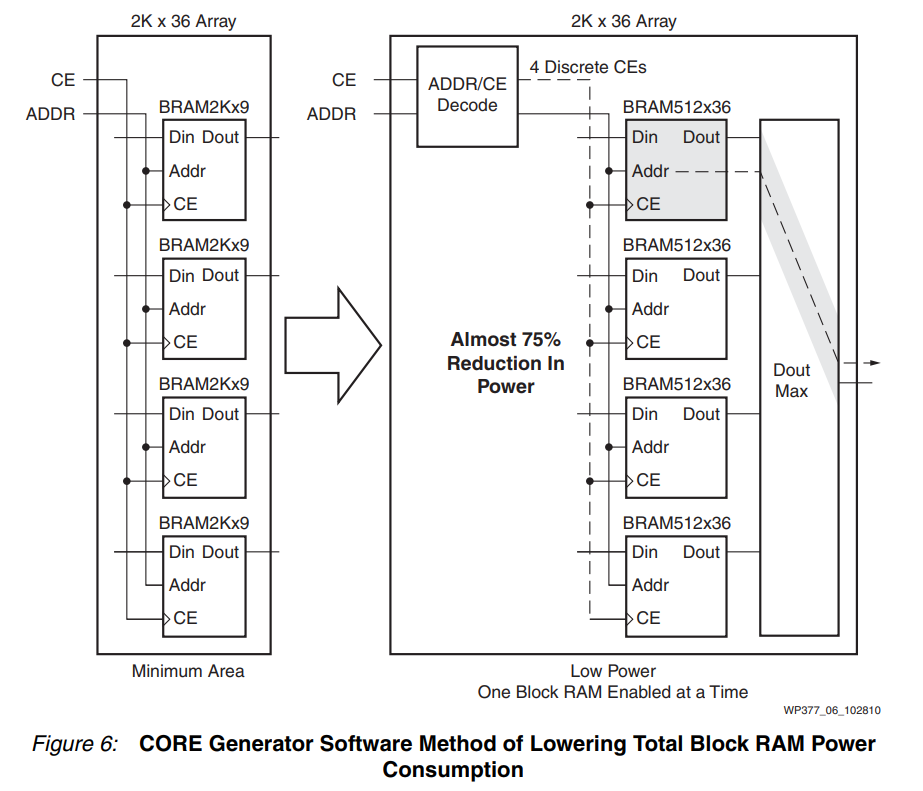
使用 CORE Generator 构建 RAM CORE Generator 工具具有三种算法,可用于优化 Block RAM 网络。最小面积方案使用尽可能少的资源(块 RAM),但也最大限度地减少了输出多路复用,以在最小面积上保持最高性能(参见图 6)。低功耗方案可以使用更多资源,但确保在每次读写操作期间启用的块最少。这可能会在使能信号上产生少量额外的解码逻辑,但与所节省的功率相比,这是一个小的面积损失。在此模式下运行时,CORE Generator 工具在 RAM_STYLE = block_power2 模式下执行与 XST 相同的功能。请注意,如果 Block RAM 网络非常大,使用低功耗方案进行拆分可能会导致需要路由许多额外的信号,这可能会耗尽设计其他部分的路由资源。
第三种优化方案是 Fixed Primitive,用户可以在其中选择一个特定的基元,例如 4K x 4,从中构建他们的 RAM 网络。由用户决定哪个原语最适合他们的应用程序。CORE Generator 工具还提供了一个选项来寄存 RAM 网络的输出以提高性能。如果网络中使用了多个 Block RAM,用户可以选择是在每个 Block RAM 原语的输出还是在内核的输出上进行寄存。
结论 组合块ram,可以配置在各种数据宽度/深度与分布式RAM的组合来支持更小的内存阵列提供最灵活的方式以最低的成本建立不同大小的存储内存。向组件添加额外的功能,例如向块RAM,如果准确的功能是正确的,最初可能是最好的解决方案必需的。然而,组件和它的组件都有区域惩罚用于添加新特性的相应互连。这些区域处罚有一个对设备资源影响较大。多年的开发经验构建FPGA嵌入式存储器已经导致了广泛的高效解决方案范围的应用程序
审核编辑:汤梓红
















 工商网监
工商网监
评论