 电子发烧友App
电子发烧友App


王帅琛, 黄倩, 张云飞, 李兴, 聂云清, 雒国萃。 2022. 多模态数据的行为识别综述。 中国图象图形学报, 27(11): 3139-3159.
摘要:行为识别是当前计算机视觉方向中视频理解领域的重要研究课题。从视频中准确提取人体动作的特征并识别动作,能为医疗、安防等领域提供重要的信息,是一个十分具有前景的方向。本文从数据驱动的角度出发,全面介绍了行为识别技术的研究发展,对具有代表性的行为识别方法或模型进行了系统阐述。行为识别的数据分为RGB模态数据、深度模态数据、骨骼模态数据以及融合模态数据。首先介绍了行为识别的主要过程和人类行为识别领域不同数据模态的公开数据集;然后根据数据模态分类,回顾了RGB模态、深度模态和骨骼模态下基于传统手工特征和深度学习的行为识别方法,以及多模态融合分类下RGB模态与深度模态融合的方法和其他模态融合的方法。传统手工特征法包括基于时空体积和时空兴趣点的方法(RGB模态)、基于运动变化和外观的方法(深度模态)以及基于骨骼特征的方法(骨骼模态)等;深度学习方法主要涉及卷积网络、图卷积网络和混合网络,重点介绍了其改进点、特点以及模型的创新点。基于不同模态的数据集分类进行不同行为识别技术的对比分析。通过类别内部和类别之间两个角度对比分析后,得出不同模态的优缺点与适用场景、手工特征法与深度学习法的区别和融合多模态的优势。最后,总结了行为识别技术当前面临的问题和挑战,并基于数据模态的角度提出了未来可行的研究方向和研究重点。
00 引言
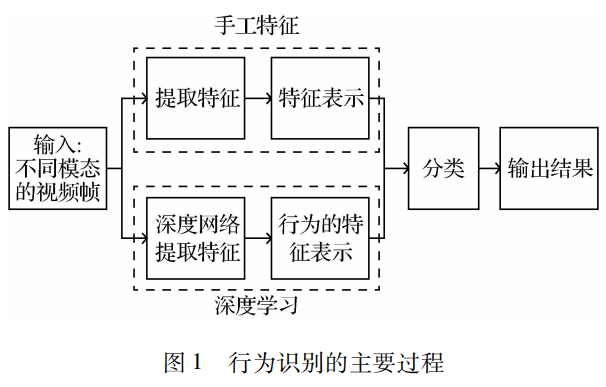
人体行为识别是计算机视觉、深度学习、视频处理和模式识别等学科交叉的研究课题,是当前计算机视觉的一个研究热点。行为识别是对包含人体动作行为的视频序列进行动作特征提取、特征表示和动作识别等操作的过程。由于视频采集传感器的成本降低和快速发展,使得行为识别有了广泛的应用前景,例如视频检索、人机交互、医学监测和自动驾驶等领域,都涉及行为识别的相关技术。行为识别属于视频理解的范畴,所以特征的提取和表示至关重要。这两个过程的好坏会直接影响最终的分类结果。特征可以通过手工制作和网络学习获取,图 1介绍了两种方法的基本过程。手工特征的方法利用图像和数学等知识,设计出一种表达动作的方式,通过表达动作的信息区分不同类别的动作。算法实现更简单,但是常常局限于某个数据集。深度学习网络自适应性更好,能够根据输入数据和设计的网络提取出侧重的特征,并能依靠反向传播等手段优化提取特征的过程,最终得到一个能高效提取动作特征和正确分类的网络模型。
从数据驱动的角度出发,可将行为识别方法分为基于RGB数据的方法、基于深度数据的方法、基于骨骼数据的方法和融合以上模态数据的方法,如图 2所示。每种数据的模态都有自身特性导致的优缺点,如RGB模态数据易采集但鲁棒性较差。因此提出了融合多模态的方法,以克服一些单模态存在的问题。本文相比较其他行为识别综述的贡献在于:1)本文的数据模态分类、方法分类和数据集分类一一对应,对初学者或者长期研究者都提供了一个结构清晰的介绍和对比;2)其他的行为识别综述通常注重单一模态下的论述,而本文更加全面地论述了多种数据模态和数据融合的行为识别;3)近年的行为识别综述只包含深度学习,缺少早期手工特征的方法,本文分析手工特征的思想优点和深度学习的优势,进而实现优势互补;4)讨论了不同数据模态的优劣性和动作识别的挑战以及未来研究方向。
01 行为识别数据集
在评价不同识别方法的性能时,数据集有非常重要的作用。目前有许多公开的行为数据集供研究人员使用。主流数据集的详细信息如表 1所示。
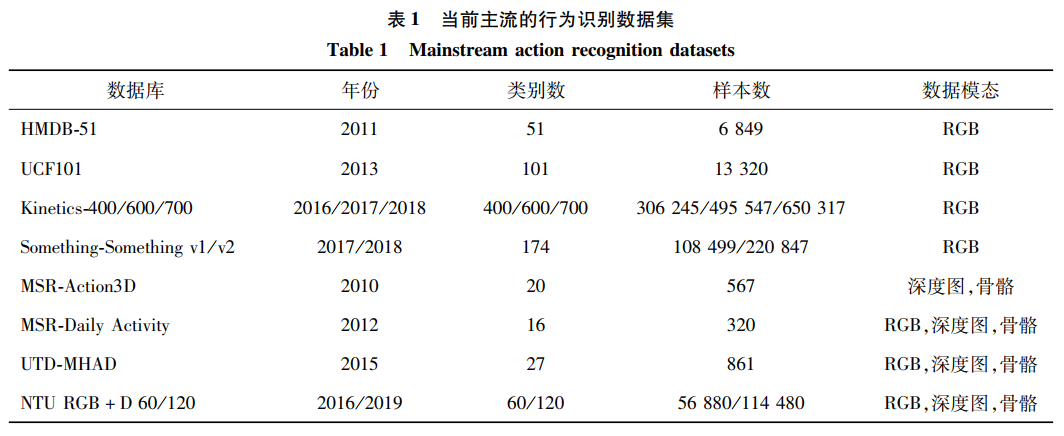
HMDB-51(human motion database)(Kuehne等,2011)中数字51代表类别数量。它是从各种互联网资源和数字化电影中收集形成,此数据集的动作主要是日常行为,如图 3所示。该数据集包含6 849个视频,分为51个动作类别,每种动作包含101个视频片段。该数据集的干扰因素主要是摄像机视角和运动的变化、背景杂乱、志愿者位置和外观的变化。

UCF101(Soomro等,2012)是由美国中佛罗里达大学计算机视觉研究中心发布的数据集,是UCF50数据集的扩展,收集自YouTube,提供了包含101个动作类别的13 320个视频样本数据。UCF101在动作方面提供了最大的多样性,在摄像机运动、对象的外观和姿态、对象规模、视点、杂乱的背景以及照明条件等方面有很大的变化。Kinetics(Carreira和Zisserman,2017)是一个大规模、高质量的YouTube视频数据集,其中包括各种各样的以人为中心的动作。该数据集由大约300 000个视频片段组成,涵盖400种动作类别,每个动作至少有400个视频片段。每个片段持续大约10 s,并标记为一个动作类别。所有片段都经过多轮人工标注,都是从一个独特的YouTube视频中获得。这些动作涵盖了广泛的动作类别,包括人与物的交互,如演奏乐器;以及人与人的交互,如握手和拥抱。发布者先后在2016年、2017年、2018年相继发布了Kinetics-400、Kinetics-600(Carreira等,2018)和Kinetics-700(Carreira等,2019)系列,代表视频中的动作可分为400、600、700个类别。Something-Something数据集(Goyal等,2017)是一个中等规模的数据集,它与一般数据集的最大区别在于,其内容定义的是原子动作,并且该数据集特别注重时序上的关系。第1版本和第2版本数据集由108 499个和220 847个视频组成,均可分为174个动作类别。MSR-Action3D(Li等,2010)是微软研究院利用Kinect深度相机捕获的动作数据集。它包含20种与人类运动相关的活动,如慢跑、高尔夫挥杆等。图 4为其中3个动作的深度图实例。这个数据集中的每个动作由10个人执行2~3次,总共包含567个样本。因为动作的高度相似性,该数据集具有一定的挑战性。

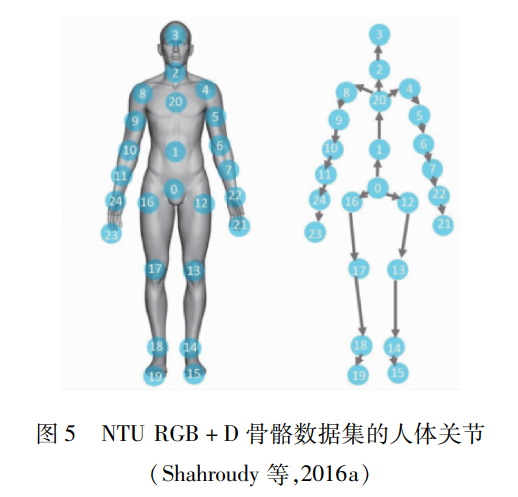
MSR-Daily Activity(Wang等,2012)是微软研究院(MSR)利用Kinect相机拍摄日常活动采集而成的数据集,共有16种动作类别,320个活动样本。其中,骨骼跟踪器提取的3维关节位置信息非常嘈杂,大部分活动都涉及人与物的交互。因此,动作的识别难度较大。UTD-MHAD(Chen等,2015a)数据集是美国得克萨斯大学达拉斯分校(The University of Texas at Dallas,UTD)发布的多模态人体行为识别数据集(MHAD),由8个表演者执行27个类别的动作组成。每个表演者重复动作4次,总共包括861个视频序列。该数据集包含RGB模态、深度模态、骨架模态和惯性传感器信号。NTU RGB+D(Shahroudy等,2016a)数据集由新加坡南洋理工大学创建,包含RGB模态和深度模态。它是迄今为止最大的动作数据集,包含56 880个样本数据和超过400万帧的视频。该数据集一共有60个动作类别,基于3台摄像机,在3个不同的视角,拍摄表演者的动作过程。这个数据集对于不同的视频序列具有可变的序列长度,并且表现出很高的类内变化。该数据集包含了RGB模态、深度模态和骨骼模态。骨骼模态的数据集包含了25个关节记录信息,图 5为人体的25个关节示意图。NTU RGB+D 120(Liu等,2020a)是NTU RGB+D数据集的扩展,添加了另外60个类别动作和57 600个视频样本,与之前的工作叠加形成120个动作类别和114 480个样本的大型数据集。
02 基于RGB数据的行为识别方法
RGB数据的优点在于成本低、易获取,缺点在于对外观的变化(如光线变化)缺少鲁棒性。当识别目标与背景具有相似颜色和纹理时,仅用RGB数据很难处理这个问题,这些局限妨碍了基于RGB数据的行为识别技术在复杂环境中的应用。基于RGB的行为特征的生成方式可分为手工制作和机器学习。
2.1 基于手工特征的方法
手工制作的目的是得到人体行为动作的运动和时空变化,包括基于时空体积的动作表示法、基于时空兴趣点的方法和基于骨骼关节轨迹的方法。基于时空体积的动作表示法利用3维的时空模板进行动作识别,关键在于匹配模板的构造和编码运动信息。Bobick和Davis(2001)提出了MEI(motion-energy images)和MHI(motion-history images)分别表示动作发生的空间位置和动作发生的时间过程,如图 6所示,MEI提取空间特征,MHI提取时间特征。在前期阶段,运动历史图和运动能量图十分相似,但在后期阶段两者有较大的区别。Klaser等人(2008)在2D HOG(histogram of oriented gradient)的基础上,拓展出3D HOG特征来描述人体行为,提高了识别准确率。上述文献的创新在于特征的表示,新颖的特征表示思想十分具有参考价值。但背景的噪声和遮挡会使特征提取十分困难,并且忽略了一些局部特征,对近似动作识别具有局限性。

基于时空兴趣点的方法较时空体积法对背景的要求降低,它通过提取运动变化明显的关键区域来表示动作,重点在于关键兴趣点的检测方法、描述的特征和分类方法。最常见的方法是基于3D-Harris时空特征点来检测关键区域。Chakraborty等人(2012)提出了一种改进后的3D-Harris方法,将局部特征检测技术从图像扩展到3维时空域,然后计算特征描述子,并利用描述行为的视觉词袋模型来构建视觉单词词汇表,用于加强对行为的描述。Nguyen等人(2015)提出了一种基于时空注意机制的关键区域提取方法,将密集采样与视频显著信息驱动的时空特征池相结合,构造视觉词典和动作特征。密集采样能更好地表示动作,但是增加了算法的复杂度,因此平衡采样密集度和算法复杂度的关系是时空兴趣点方法的重点之一。上述方法易受遮挡和相机视角变化的干扰,所以提出了基于骨骼和关节轨迹的动作表示方法,用于分析人体的局部运动信息。该方法从RGB图像中提取骨骼关键点或者跟踪人体骨骼运动的轨迹,根据关键点和轨迹判断动作的类别。该方法的关键在于使用何种算法和模型从RGB图像中提取关键点或者轨迹。Gaidon等人(2014)基于分裂聚类法表示局部运动轨迹,计算轨迹特征并用聚类结果表示不同运动类别。Wang和Schmid(2013)借鉴兴趣点密集采样的思想,通过采集密集点云和光流法跟踪特征点,获取密集轨迹(iDT),然后计算位移信息进行识别。RGB模态的骨骼和关节轨迹方法仍然存在背景和遮挡的干扰。但是识别动作的准确性提高,促使之后的科研人员依靠传感器采集骨骼模态形成数据集,从骨骼模态的角度研究行为识别。
2.2 基于深度学习的方法
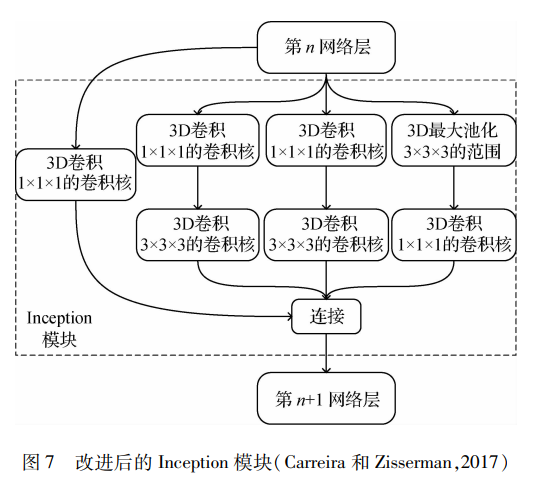
深度学习的崛起逐渐影响了行为识别领域。基于深度学习网络提取的高层次特征,信息量丰富、有区分性,优于传统手工特征,应用于行为识别领域取得了重大的突破。在2D-CNN的基础上,Carreira和Zisserman(2017)提出了一种I3D模型,将卷积从2维扩展到3维,并提出了双流3D卷积网络用于动作识别,双流网络也成为后人模仿借鉴的经典方法。图 7为I3D中改进后的Inception模块,其中大小为1的3D卷积作用为减少参数量,尺寸都为3的最大池化和3D卷积提取不同尺度的特征,同时残差连接输入与输出,保持模型的稳定性。同时Carreira和Zisserman(2017)提出了Kinetics数据集,将许多经典算法在此数据集上进行实验对比,分析各算法的优缺点。Zhu等人(2018)提出了一种名为隐式双流神经网络结构的CNN体系结构,将原始视频帧作为输入并直接预测动作类别,通过隐式捕获相邻帧之间的运动信息,使用端到端的方法解决了需要计算光流的问题。研究者通过改进卷积网络的模块和深度,行为识别的准确率大幅提升。虽然加深网络能更有效地提取特征,但网络也会变得臃肿和训练缓慢。为了保证时空流之间的可分辨性和探索互补信息,Zhang等人(2019)提出了一种新颖的协同跨流网络,该网络调查多种不同模式中的联合信息,通过端到端的学习方式提取共同空间和时间流的网络特征,探索出不同流特征之间的相关性,从中提取不同模态的互补信息。神经网络方便了特征提取的方法,但不能拘泥于网络深度等方面,更应该从多个角度(帧选择和跨流网络的想法)优化识别过程。为了解决光流的计算复杂度问题,Kwon等人(2020)用运动特征的内部信息和轻量级学习代替对光流的繁重计算,提出了一种名为MotionSqueeze的可训练神经模块,用于有效的运动特征提取。该模块即插即用,能插入任何神经网络的中间来学习帧间关系,并将其转换为运动特征,然后送到下一个网络层进行更好的预测。
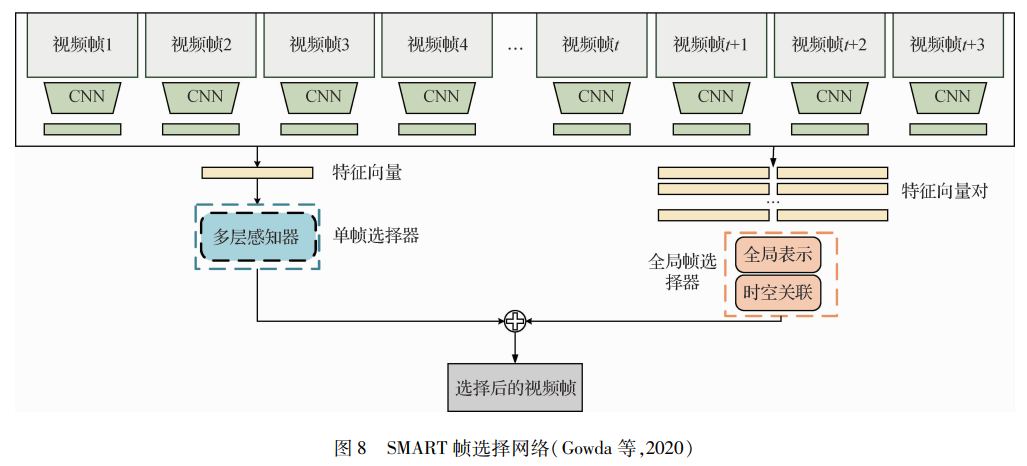
学者的创新曾经局限在提取特征的技术,Gowda等人(2020)从帧选择的角度出发,保留行为特征在时间序列上区别明显的“好”帧,剔除特征类似和无法分类的帧,提出一种名为SMART的智能帧选择网络,如图 8所示,综合考虑单个帧和多个帧的质量,而不是一次仅考虑一个帧。在降低计算量的同时,提高了识别准确率。Qiu等人(2019)注意到视频是具有复杂时间变化的信息密集型媒体,而神经网络中的卷积滤波器都是局部操作,忽略了视频帧之间的相关性,提出了一种新的基于局部和全局扩散的时空表示学习框架,并行学习局部和全局表示。每个块建模这两种表示方式,并且两者之间交换信息来更新局部和全局特征,多个块组成此网络结构,有效地保持了信息的局部性和整体性,获得了强大的特征学习方式。这些行为识别技术的革新都是在其他研究的基础上,保留优点,减弱负面影响或者解决存在的问题,最终实现行为识别技术的突破。
03 基于深度数据的行为识别方法
RGB数据受干扰性较大,促使了深度数据的产生。深度图中的纹理和颜色信息少,将图像采集器到场景中各点的距离(深度)作为像素值,对光照的鲁棒性强。深度传感器的产生极大地扩展了计算机系统感知3D视觉世界和获取视觉信息的能力。深度数据的信息与RGB数据本质上不同,它对场景的距离信息进行编码,而不是对颜色强度进行编码。因此,深度数据可以更简单精确地获取关键区域。但深度信息也不是一直具有鲁棒性,遮挡物和闪烁噪声可能会对行为识别造成误差。
3.1 基于运动变化和外观信息的方法
基于深度数据的行为识别方法主要利用人体深度图中的运动变化来描述动作。动作的特征由深度变化的外观或运动信息进行描述。Yang等人(2012)通过深度运动图(DMM)来投影和压缩时空深度结构,再从正面,侧面和俯视图形成3个运动历史图。然后,利用HOG特征表示这些运动历史图,并将生成的HOG特征串联起来以描述动作。除了计算运动变化来描述动作的方法外,另一种流行的方法是通过外观信息来描述动作。Yang等人(2012)基于深度序列构造一个超向量特征来表示动作,通过连接来自深度视频的局部相邻超曲面法线来扩展HON4D,联合局部形状和运动信息,引入了一种自适应时空金字塔,将深度视频细分为一组时空单元,以获得更具鉴别力的特征。为了剔除噪声影响,Xia和Aggarwal(2013)提出了一种新的深度长方体相似性特征,用来描述具有自适应支撑尺寸的3维深度长方体,从而获得更可靠的时空兴趣点。Chen和Guo(2015)通过分析前、侧和上方向的时空结构,提取时空兴趣点的运动轨迹形状和边界直方图特征,以及每个视图中的密集样本点和关节点来描述动作。深度模态较RGB模态多了深度这一信息,因此如何充分利用深度相关信息,如大小、变化等,是基于深度模态的行为识别的关键。这一思想不但适用于手工特征法,也适用于深度学习法。
3.2 基于深度学习的方法
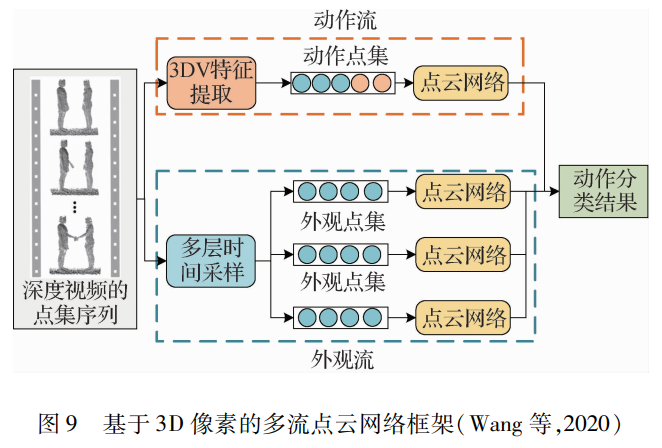
深度模态下基于深度学习的方法可分为两类:一类是深度特征图和卷积神经网络的结合;另一类是提取深度信息的点集与点云网络的结合。为了充分利用深度序列中的空间、时间和结构信息进行不同时间尺度的动作识别,Wang等人(2018a)提出了3种简单、紧凑而有效的深度序列表示方法,分别称为动态深度图像(DDI)、动态深度法线图像(DDNI)和动态深度运动法线图像(DDMNI),用于孤立和连续动作识别。其中,DDI记录了随时间变化的动态姿势,DDNI和DDMNI记录了深度图捕获的3维结构信息。然后将3种特征图输入神经网络,提取不同的特征。Trelinski和Kwolek(2019)提出了一种基于深度图序列的动作识别算法。首先,在单个深度图中提取描述人形的特征,然后,对每个类单独训练提取单个类的特征,同时对每个深度图中代表人形的像素计算手工的特征。最后,所有动作共用的手工特征和特定动作的特征连接在一起,形成动作特征向量。深度图和点云可以相互转换,并且点云的表示简单,有非常统一的结构,避免组合的不规则性和复杂性。因此,Wang等人(2020)提出了3维动态像素(3DV)作为新颖的3维运动表示。通过时间顺序池化将深度视频中的3维运动信息压缩成规则的3DV像素点集,每个可用的3DV像素本质上涉及3维空间和运动功能,然后将3DV抽象为一个点集。由于3维点集的不规则,常规的卷积神经网络不适合处理不规则的信息形状,将点集输入点云网络(PointNet++),保持了点集的置换不变形。如图 9所示,动作流提取3D像素表示的人体动作特征,外观流提取人体的外观特征,结合两个特征的信息进行行为识别。Wang等人(2015)将卷积网络与深度图结合起来,通过卷积网络来学习深度图像序列的动作特征。利用分层深度运动映射(HDMMs)来提取人体的形状和运动信息,然后在HDMMs上训练一个卷积神经网络进行人体动作识别。在此基础上,Liu和Xu(2021)设计一个端到端的几何运动网络(GeometryMotion-Net),分别利用点云网络提取运动特征和几何特征,而3DV PointNet不能进行端到端的训练。3DV PointNet并没有充分考虑时间信息,而GeometryMotion-Net将每个点云序列表示为一个虚拟整体几何点云和多个虚拟运动点云来明确时间信息。两项改进措施使得识别准确率有了较大提升。
04 基于骨骼数据的行为识别方法
该方法通过骨骼关节实时对3D人体关节位置进行编码,实现人体行为的动作识别。由于人体骨骼的运动可以区分许多动作,利用骨骼数据进行动作识别是一个有前景的方向。骨骼数据包含的时空信息丰富,关节节点与其相邻节点之间存在着很强的相关性,使得骨架数据不但能在同一帧中发现丰富的人体结构信息,帧与帧之间也存在着强相关性。同时考虑骨骼和帧序列、时域和空域之间的共现关系能准确地描述动作。
4.1 基于骨骼特征提取的方法
对现有的基于骨骼数据的特征提取方法进行分析,根据其所对应的识别位置可分为基于关节和基于身体部位的行为识别方法。Vemulapalli等人(2014)提出了一种新的骨骼表示法,利用3维空间中的旋转和平移来模拟身体各个部位之间的3维几何关系。人体骨骼作为李群中的一点,人的行为可以被建模为这个李群中的曲线,将李群中的动作曲线映射到它的李代数上,形成一个向量空间。然后结合线性支持向量机进行分类。Koniusz等人(2016)使用张量表示来捕捉3维人体关节之间的高阶关系,用于动作识别,该方法采用两种不同的核,称为序列相容核和动态相容核。前者捕捉关节的时空相容性,后者则模拟序列的动作动力学。然后在这些核的线性化特征映射上训练支持向量机进行动作分类。
4.2 基于深度学习的方法
Liu等人(2016)通过对骨架序列进行树结构的遍历,获得了空间域的隐藏关系。其他方法进行关节遍历只是把骨架作为一条链,忽略了相邻关节之间存在的依赖关系,而此遍历方法不会增加虚假连接。同时使用带信任门的长短期记忆网络(LSTM)对输入进行判别,通过潜在的空间信息来更新存储单元。Caetano等人(2019)提出了一种基于运动信息的新表示,称为SkeleMotion。它通过计算骨骼关节的大小和方向值来编码形成每行的动作信息和每列的描述时间信息,形成调整后的骨骼图像。然而,人类3维骨骼数据是一个拓扑图,而不是基于RNN或CNN的方法处理的序列向量或伪图像,而图卷积网络(GCN)具有天生处理图结构的优势,使得它在基于骨骼的行为识别技术取得了重大突破。基于图卷积的行为识别技术关键在于骨骼的表示,即如何将原始数据组织成拓扑图。Yan等人(2018)首先提出了一种新的基于骨架的动作识别模型,即时空图卷积网络(ST-GCN),该网络首先将人的关节作为时空图的顶点,将人体物理关节连接和时间作为图的边;然后使用ST-GCN网络进行信息的传递汇集,获取高级的特征图,并用Softmax分类器划分为对应的类别。在此基础上,Li等人(2019)提出的AS-GCN不仅可以识别人的动作,而且可以利用多任务学习策略输出对物体下一个可能姿势的预测。
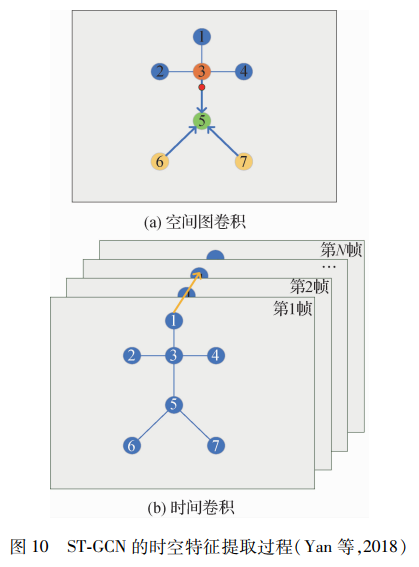
构造的拓扑图通过动作连接和结构连接的两个模块来捕捉关节之间更丰富的相关性。Shi等人(2020)提出了一种新的多流注意增强自适应图卷积神经网络来进行基于骨架的动作识别。模型中的图拓扑可以基于输入数据以端到端的方式统一或单独地学习。这种数据驱动的方法增加了图形构造模型的灵活性,使其更具有通用性,以适应各种数据样本。同时关节差值和帧间差值的数据构造多流网络,在决策阶段融合,实现识别率的进一步提升。Obinata和Yamamoto (2021)从另一角度注意到帧间的拓扑图,不仅仅在帧间同一关节对应的顶点之间进行连接,在帧间多个相邻顶点之间添加连接,并提取额外的特征,实现识别率的提高。改进拓扑图后的识别效果理想,使得后续的许多研究都着重于这一点,如设计动态可训练拓扑图(Ye等,2020)、各通道独享的拓扑图(Cheng等,2020a)以及结合全局和局部的拓扑图(Chen等,2021a)。如图 10所示,空间图卷积过程是离重心(3号下方的最小点)近的3号近心点和离重心远的6号和7号远心点通过骨骼连接向5号根节点传递信息,如此反复,获得提取空间特征;时间卷积是将同一关节在时间维度上进行信息汇集,即同一关节的部分帧序列进行信息汇集,得到时间特征。骨架序列的时空图表示是图卷积网络(GCN)的扩展,专门用于执行人类行为识别。首先,通过在人体骨架的相邻身体关节之间以及沿时间方向插入边来构造时空图。然后,应用GCN和分类器来推断图中的依赖关系并进行分类。
图卷积作为基于骨骼数据的行为识别的热点研究之一,其数据形式——拓扑图十分契合人体骨骼图,特征和信息的获取与传递在物理结构和语义层面都符合图结构,因此取得了较为理想的效果。但图结构也成为行为识别的限制,如坐标的分布会影响图卷积的鲁棒性,缺失一些重要的关节点会降低识别的效果。另外,图卷积将每个关节点视为图中的一个点,其复杂性和人数成正比,而现实中的许多动作涉及多人以及相关物体。成倍增加的计算消耗量使得图卷积难以在多人动作的任务上实现较好的应用。
05 基于数据融合的行为识别方法
RGB数据、深度数据和骨骼数据具有各自的优点。RGB数据的优点是外观信息丰富,深度数据的优点是不易受光照影响,骨骼数据的优点是通过关节能更准确地描述动作。所以,选择哪种模态进行行为识别也是研究人员权衡的方面之一。根据汇集的文献资料,本文总结了各类模态的特点和适用场景,如表 2所示。

由于单模态始终存在一些问题,研究者尝试使用多种方式进行特征融合,克服这些问题。
融合方式有3种:特征层融合、决策层融合和混合融合。不同的方式融合结果具有各自的优点,弥补缺点,得到对运动的动作有更好的描述。
5.1 基于RGB模态与深度模态的融合方法
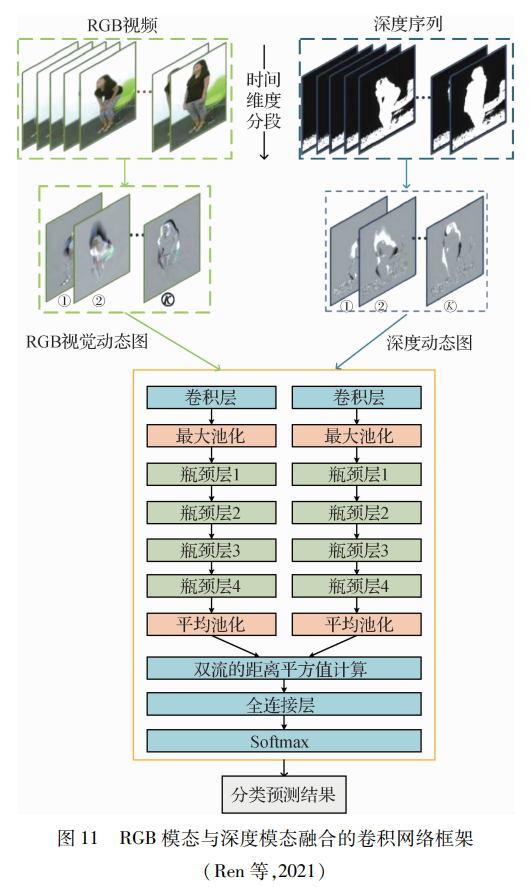
根据模态产生的时间顺序,RGB模态与深度模态的融合是最先提出也是最为普遍的组合方式。Jalal等人(2017)从连续的深度图序列中分割人体深度轮廓,并提取4个骨骼关节特征和一个体形特征形成时空多融合特征,利用多融合特征的编码向量进行模型训练。Yu等人(2020)使用卷积神经网络分别训练多模态数据,并在适当位置进行RGB和深度特征的实时融合,通过局部混合的合成获得更具代表性的特征序列,提高了相似行为的识别性能。同时引入了一种改进的注意机制,实时分配不同的权值来分别关注每一帧。Ren等人(2021)设计了一个分段协作的卷积网络SC-ConvNets)来学习RGB-D模式的互补特征,整个网络框架如图 11所示。首先将整个RGB和深度数据序列压缩成动态图像分别输入双流卷积网络中,再计算距离的平方值获得融合的特征。与先前基于卷积网络的多通道特征学习方法不同,这个分段协作的网络能够联合学习,通过优化单个损失函数,缩小了RGB和深度模态之间的差异, 进而提高了识别性能。
深度模态没有RGB模态的纹理和颜色信息,RGB模态比深度模态在空间上少一个深度信息的维度,因此两者的数据模态可以很好地互补对方缺失的特征信息。大量研究结果表明了此种融合方法的合理性和优越性。因此提取另一个模态缺少的信息,避免相同信息的冗余,是模态融合的重点和难点。
5.2 其他模态的融合方法
其他模态的关系,如骨骼模态与深度模态互补关系,稍弱于RGB和深度模态的互补关系。但不同模态仍有互补信息的存在,所以不同模态融合也是研究人员的研究方向之一。Elmadany等人(2018)使用规范相关分析(CCA)来最大化从不同传感器提取的特征的相关性。此论文研究的特征包括从骨架数据中提取的角度数据、从深度视频中提取的深度运动图和从RGB视频提取的光流数据,通过学习这些特征共享的子空间,再使用平均池化来获取最终的特征描述符。Rahmani等人(2014)提出一种称为深度梯度直方图的描述子,结合深度图像和3维关节位置提取的4种局部特征来处理局部遮挡,分别计算深度、深度导数和关节位置差的直方图,将每个关节运动量的变化并入全局特征向量中,形成时空特征,并使用两个随机决策森林,一个用于特征修剪,另一个用于分类,提高识别的精度。特征可以在初级阶段融合,也可以在高级阶段形成语义信息的时期融合。前者相当于对数据进行补充增广,后者形成新的语义信息。融合也可以发生在决策阶段,联合不同模态的预测结果后得到一个综合的预测结果。一般而言,越早期的模态融合需要的计算量越小,越后期的模态融合复杂度越大。研究者常常使用混合折中的方法,保持两者优势的同时,也克服了一些缺点。融合的具体方式及其优缺点如表 3所示。对于神经网络,不同模态的融合可以在特征提取阶段,可以将多流网络的输出汇集到单个网络中实现特征融合。融合的关键在于数据模态的选择和融合的时间。研究者需要思考一种模态融入另一种模态后的特征是否克服了原有模态的缺点,否则融合操作只会增加计算量。

06 行为识别方法对比
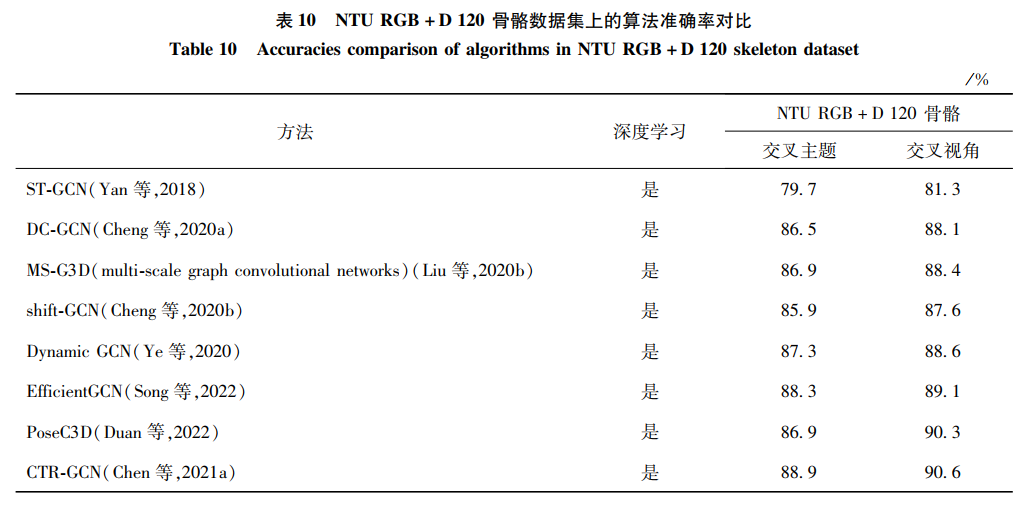
对不同数据模态下的行为识别方法进行比较,通过表格和柱状图等方式的对比,以期得出一些行为识别技术的结论。Top-1代表概率最大的结果是正确答案的准确率,Top-5代表概率排名前5的结果是正确答案的准确率。交叉主题(cross subject)和交叉视角(cross view)是NTU RGB+D 60数据集中训练集和测试集的划分。交叉主题将40个志愿者划分为训练和测试两个队伍。每个队伍包含20个志愿者,其中1,2,4,5,8,9,13,14,15,16,17,18,19,25,27,28,31,34,35,38为训练集,其余为测试集。交叉视角将3个视角的相机中,相机2号和3号作为训练集,相机1号为测试集。NTU RGB+D 120中的训练集和测试集划分方式包括交叉主题(cross subject)和交叉设置(cross setup)两种。交叉主题表示训练集包含53个主题,测试集包含另外53个主题。交叉设置表示训练集样本来自偶数编号,测试集样本来自奇数编号。6.1 RGB模态的方法对比
RGB模态数据集选取了经典的UCF101数据集和HMDB-51数据集,以及新颖的Something-Something数据集,对比了经典方法和新发表的效果最佳的方法,如表4和表5所示。
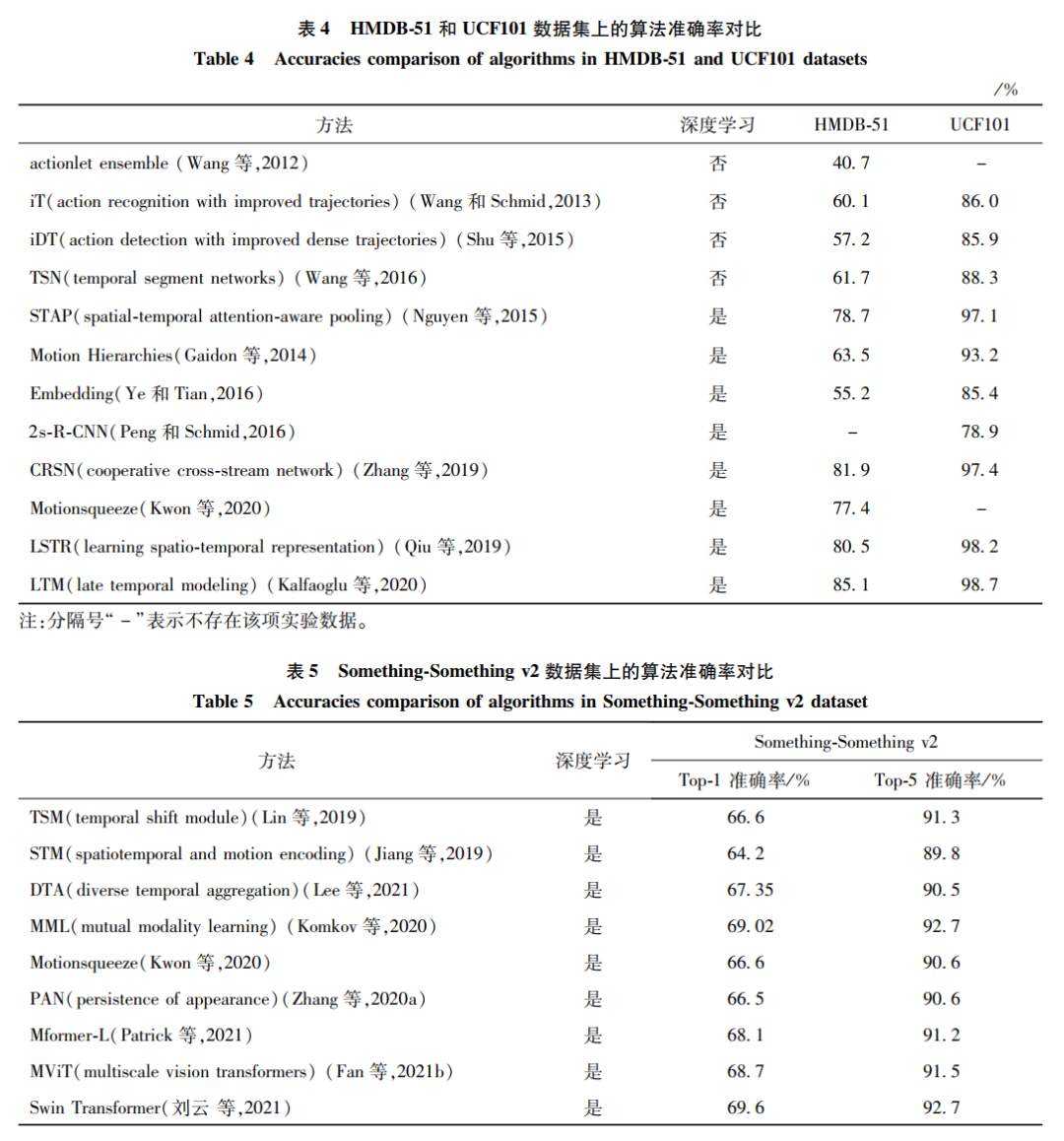
对于HMDB-51数据集,手工特征方法的准确率最高仅有61.7%,而深度学习方法的最低准确率是55.2%。基于深度学习的方法将该数据集的最高准确率提高到85.1%。对于UCF101数据集,手工特征方法的最高准确率88.3%,基于深度学习的方法将准确率提高到98.7%,已经基本符合应用的要求。在Something-Something数据集上,手工特征法鲜有研究,大都是基于深度学习方法的开展。原因是该数据集规模较大,手工制作的特征已经无法准确地描述动作。而且动作类别多,使得Top-1的最高识别率仅有69%,是RGB模态的行为识别方向下一个需要攻克的数据集。根据大量文献和实验的依据,本文总结了两类方法的优缺点如表 6所示。

本文将统计的数据绘制成柱状图,从图12中能明显观察出,基于手工特征的方法(灰色表示的柱状)基本低于深度学习方法的识别率(灰色以外的其他颜色),说明深度学习的方法一般具有更好的识别性能。类似的情况也发生在其他模态中。
6.2 深度模态的方法对比深度模态数据集选取了经典的MSR-Action3D数据集与当前主流的NTU RGB+D深度数据集,和RGB模态的实验思路相同,比较了经典算法和最新卓越方法,结果如表 7和表 8所示。
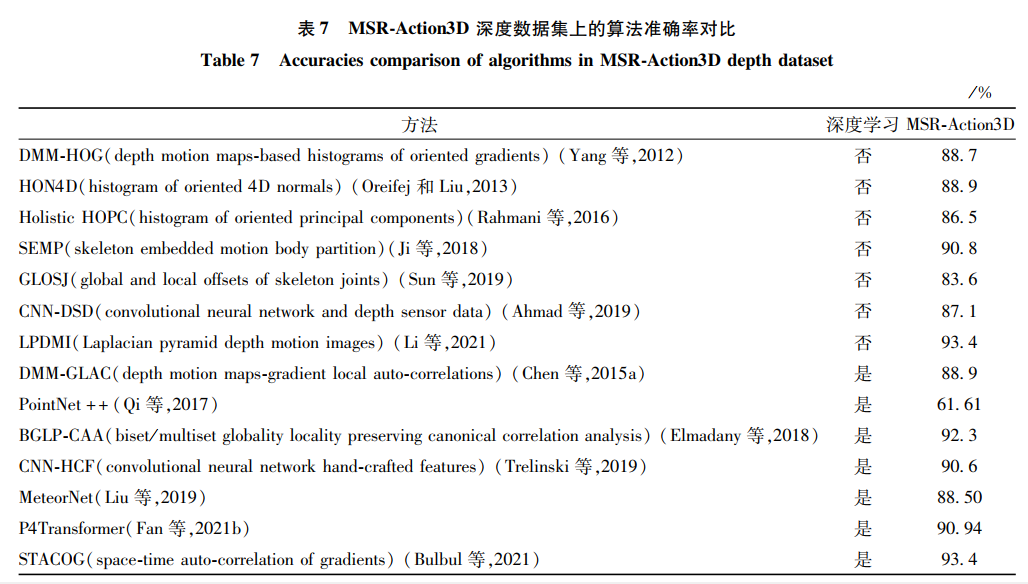
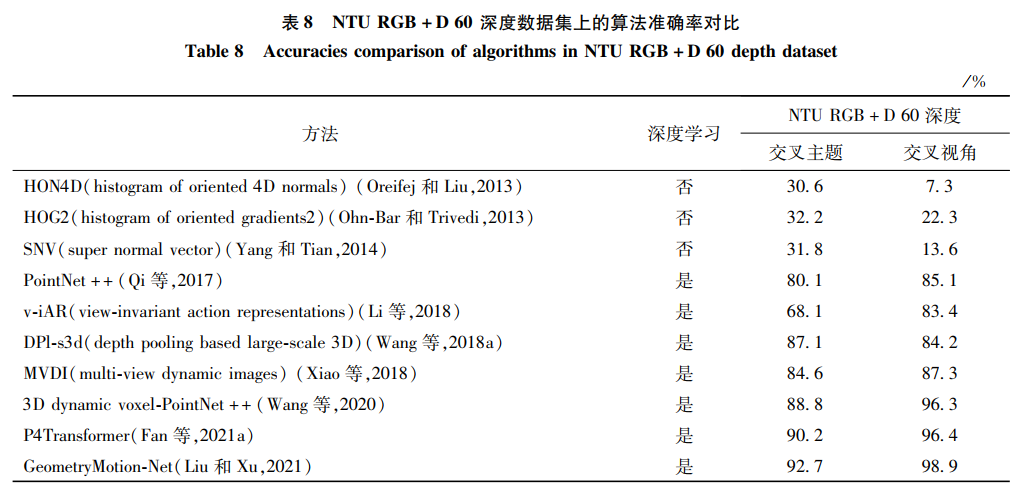
当前的多数方法已经在MSR-Action3D深度数据集上达到了90%的准确率,说明该数据集的大部分价值已被挖掘,但MSR-Action3D仍然是评价一个算法好坏的经典数据集之一。近期主流的数据集是NTU RGB+D数据集中的深度模态部分,深度数据模态的人体行为数据集相较其他两个模态发布较少,在这方面还有很大的进步空间。在NTU RGB+D数据集的深度模态部分,手工特征的方法在这个大型数据集上效果较差。原因与RGB模态的情况相似,该数据集规模大、样本多、类别多,手工制作的特征能表示部分动作信息,但难以覆盖整个数据集的动作范围。两个新发布的网络的变体:点云网络(PointNet++)和Transformer网络,在NTU RGB+D深度模态部分的识别率达到了近90%和90.2%的高度。研究者可以从不同的角度改进这两个网络,可能会达到新的性能高度。这也给了研究者另一种想法,通过移植或者改进领域外的新颖网络,适配到行为识别方向中,或许能取得意想不到的效果。
6.3 骨骼模态的方法对比
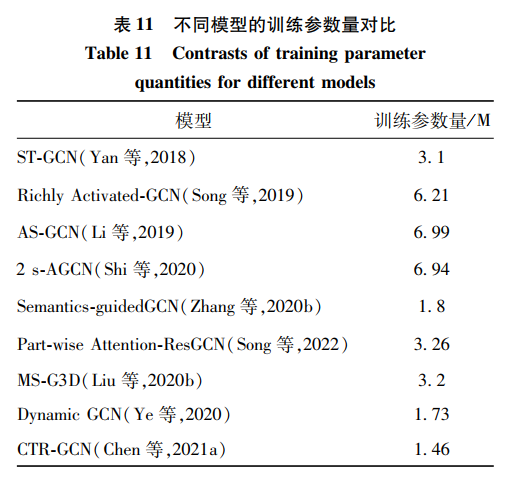
骨骼模态是近年越发流行的模态,本文选取了主流的NTU RGB+D skeleton骨骼数据集,对比了许多算法的差异。在NTU RGB+D 60和120数据集的实验设置下,手工特征和深度学习的方法对比如表 9和表 10所示。深度学习的方法全面超越了手工特征方法。从中可发现,基于深度学习的方法几乎占据了全部范围。其中,早期研究者多使用标准卷积网络将骨骼数据编码成像素排列的伪图像,借鉴图像分类和视频分类的思想提取特征。这种方式取得的效果并不理想,因为它割裂了骨骼内在的连接性。之后,提出了卷积网络的变体——图卷积。由于图的结构十分符合人体骨骼连接,取得了理想的效果,也促进了图卷积在行为识别领域中快速发展。本文发现,初期研究者往往仅考虑识别率的高低,忽略了算法和模型的复杂度。
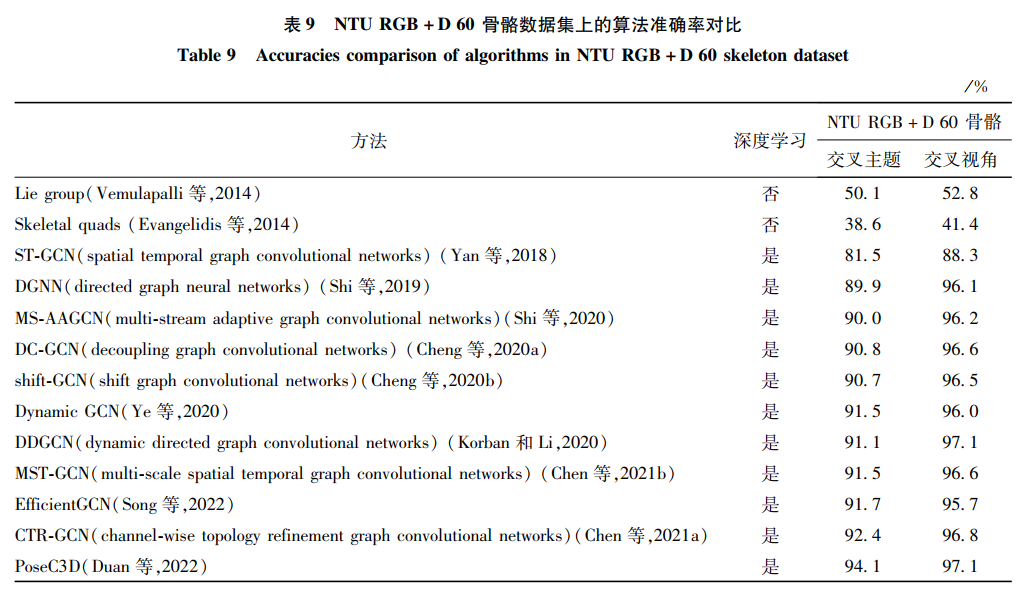
统计在骨骼模态上相关模型的训练参数量后如表 11所示。以ST-GCN为基础,科研人员通过加深模型层次和改进模型结构,设计出AS-GCN、2S-GCN等优秀模型。虽然提高了识别性能,但是模型越来越庞大,识别率也达到了瓶颈。意识到这一问题后,研究人员开始设计更轻量的网络,如MS-G3D、Dynamic GCN、CTR-GCN等。在达到相同识别效果的同时,设计了复杂度更小、训练速度更快的网络。从模型优化的角度进一步发展了行为识别技术。
图卷积的应用将NTU RGB+D 60骨骼数据库的交叉识别率从50%快速提升至88%。经过科研人员的不断努力研究,目前交叉主题和交叉视角的最高识别率已经达到94.1%和97.1%。在NTU RGB+D 60数据集上已经基本完成行为识别的任务。在NTU RGB+D 120数据集,动作类别数更多,更加有挑战性和难度。目前的最高识别率只有90%左右。所以,NTU RGB+D 120数据集是目前最全面和权威评价一个算法和模型好坏的数据集。希望相关人员能首先考虑以该数据集作为基准,通过数据驱动行为识别的进一步发展。本文发现,越高的识别率增长的幅度越小。这也从侧面反映了图卷积在行为识别领域达到了一定的瓶颈期。从本文数据模态的角度出发,有以下两点建议:1)融合其他模态的数据,补充骨骼数据的信息,进而获得更好的结果。2)使用一种新的方式代替拓扑图表示骨骼的信息,便于提取更多的动作特征。
6.4 多模态融合的方法对比
NTU RGB+D包括了RGB、深度和骨骼模态,选择该数据集作为基准对比不同的算法,结果如表 12所示。
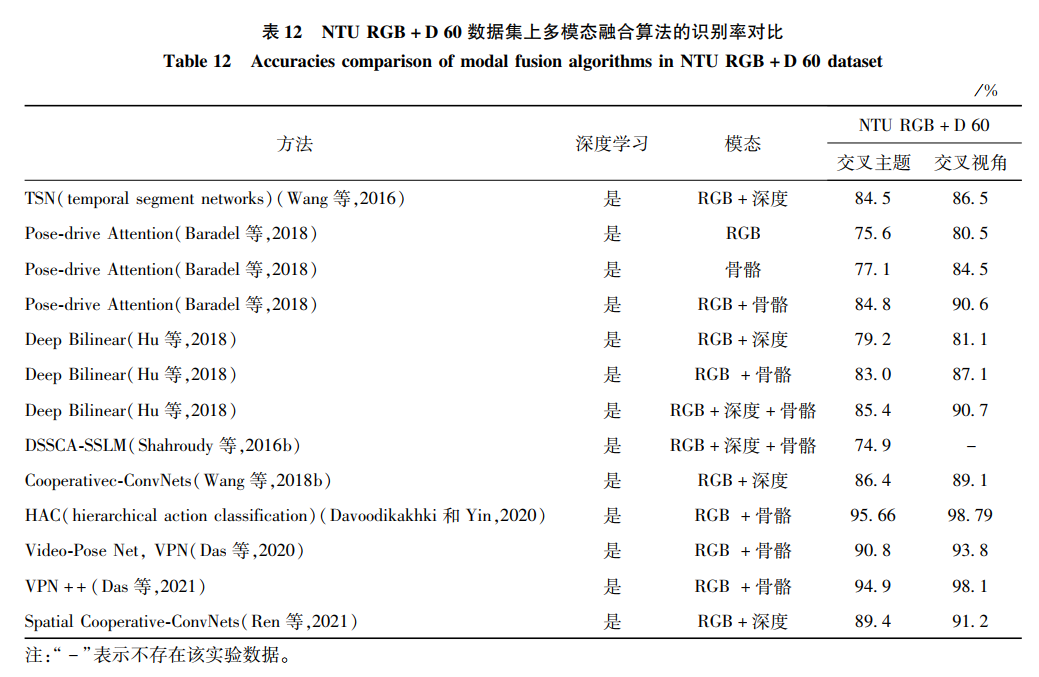
选取其中的两个方法Pose-drive Attention和Deep Bilinear作为代表,比较其在不同模态下的识别率。从表 13中可以清楚地观察到,对于Pose-drive Attention模型,RGB和骨骼模态融合的识别率明显高于RGB或者骨骼单个模态的识别率。对于Deep Bilinear模型,3个模态融合后的识别率高于两个模态融合的识别率。因此,融合多个模态的方法十分有利于行为识别的效果提升。
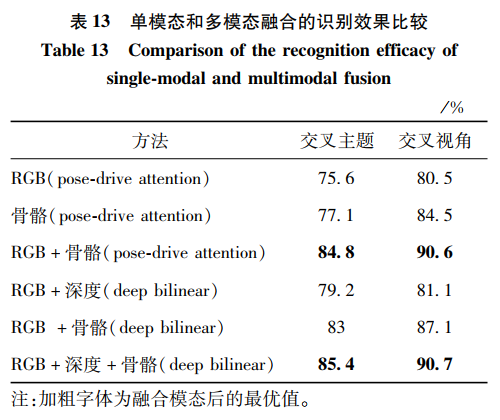
最常用的组合是RGB模态和深度模态,原因是由于深度模态比RGB模态多了深度信息,而RGB模态比深度模态多了颜色纹理信息,两者能较好地互补信息,从而提取到描述更好的特征,达到提高识别率的效果。其次是骨骼和其他模态的组合,由于骨骼数据在早期较难与其他模态融合,研究者一般都选择在高维特征阶段进行融合,实现信息的互补。最后,本文从各类模态内部比较和各类模态之间比较发现了一些规律和特点。骨骼模态数据和RGB模态数据是人体行为识别中使用较多的模态。在各类模态下,深度学习的方法一般都优于手工特征的方法,这是因为深度学习提取的特征基于数据集本身的数据信息,相较于手工特征,深度学习获得的特征更加准确地描述了动作。通过融合不同数据模态的特征或者决策层融合,实现信息互补,达到更优异的效果。
07 结语
目前,行为识别在一些数据集上的识别率已经很高,在日常生活中也有一些应用。但是行为识别仍然存在许多挑战。1)数据集的规模越来越大,环境越来越复杂,愈发符合现实场景。物体遮挡、视频的像素值和帧数、交互运动以及图像的多尺寸等因素,都会极大地影响识别过程。2)尽管目前有许多模态的数据,但并非所有模态的数据都易采集。RGB模态是能够利用一般相机直接获得,深度模态需要深度传感器(如Kinect相机)获得,而骨骼模态是从前两者模态中抽象得到的一种描述人体行为的模态数据。3)特殊动作的识别包括相似动作的识别、多人动作的识别以及高速动作的识别。对于这些挑战,研究者还需不断探索,寻找解决问题的方案。本文总结了一些行为识别领域在未来可行的研究方向:1)多模态融合是一个具有前景的研究方向。无论是在特征层的特征融合,或者在预测阶段的决策融合,都已经被证明是一个可行的方案。除了上述所提的主流模态外,一些模态(如红外线、声音)等信息也能够融合其中,实现信息补充,提高识别性能。2)深度学习网络已经成为主流,符合数据集规模增加的趋势。手工制作的特征并非完全舍弃。研究人员依然可以借鉴制作特征的思想,从视频中提取去除无关信息的手工特征后再输入深度学习的网络中,减少了网络参数,也提高了识别效果。3)设计和移植新型网络,增加注意力模块。自从2D卷积神经网络应用在行为识别领域,识别效果大幅提升。然后,3D卷积神经网络、图卷积网络的应用使识别效果又提升了一个层次。所以,设计新型的网络或者移植其他领域的网络是有参考价值的。同时,注意力模块在网络中愈发广泛应用。注意力模块能够较好地去除时间和空间特征中的无关信息,将重点放在显著区域,进而提升识别准确率。本文从多模态的角度对行为识别的研究进行了综述,整理了主流的数据集,全面分析了各类模态的行为识别方法,重点分析了特征的设计和网络的结构,最后对比不同算法或网络的效果,总结出一些存在的问题和未来可行的方向。本文的分类结构希望能给初学者提供一个完整的行为识别领域的知识,使相关研究人员能从中获得一些创新的思路和启发。
编辑:黄飞











 工商网监
工商网监
评论