 电子发烧友App
电子发烧友App


"不可纠正的内存错误是数据中心的主要故障原因之一"
本文利用今日头条服务器集群中3个主要的双内联存储模块( dual inline memory module,DIMM )制造商的大规模现场数据,对可纠正错误( corrected error,CE )和不可纠正错误( uncorrectable error,UE )进行了实证研究。与以往的研究不同,本文的研究首次理解了CE和DIMM部件号的错误比特信息之间的关系。与传统的芯片失效纠错码( Chipkill Error Correction Code,ECC )不同,在当今的Intel服务器平台中,ECC被削弱,无法容忍单个芯片的某些错误位模式。利用可获取的粗粒度ECC知识,本文从错误比特信息中推导出一个新的指标:Risky CE。从数据中,本文表明新指标在测试来自不同制造商的DIMM的未来UE发生时具有一致的高灵敏度和特异性。
背景
一、数据收集
研究中使用的DRAM错误数据来自字节跳动的一个服务器集群。在服务器农场,大约有10万台服务器采用SkyLake或Cascade Lake架构,即英特尔最新的服务器架构。包括互联网服务、在线数据馈送、离线数据分析等在内的各种工作负载混合在服务器上运行。服务器上的DIMM来自三星、海力士和美光。
DRAM错误数据主要通过Linux检错纠错驱动程序采集。同时获取每个CE的微观地址信息,即channel、rank、bank、row和column。通过引用驱动程序日志中记录的读取重试寄存器来提取每个CE的错误位信息。数据收集时间为2021年1月至8月。期间未启用硬件保护技术(例如,部分缓存行空闲、行空闲、行空闲或片空闲)和软件保护技术(例如,操作系统中的页面裁剪)。值得注意的是,在这项研究中,特别感兴趣的是过去CE历史中未来UE发生的线索。对于具有一个UE的DIMM,本文将其误差日志限制为其第一个UE出现的时间(即只保留UE之前的CE历史)。在此期间,超过1万个DIMM上观测到超过800万个CE。在574个DIMM上观测到UE。
特别要注意的是,本文使用的数据集和先前工作中有两点是比较特殊的:
1、对于每个CE,能够知道哪些比特是错误的。这使得可以基于CE的错误比特模式进行进一步的分析,以更好地理解与UE的相关性。
2、对于每个DIMM,记录其部分编号。这样可以看到,某种分析是否可以推广到来自制造商的不同零件编号,或者与特定零件编号相关。
表中给出了DRAM故障数据集关于不同DIMM厂商和零件编号的特征。
新的风险指标
一、Risky CE
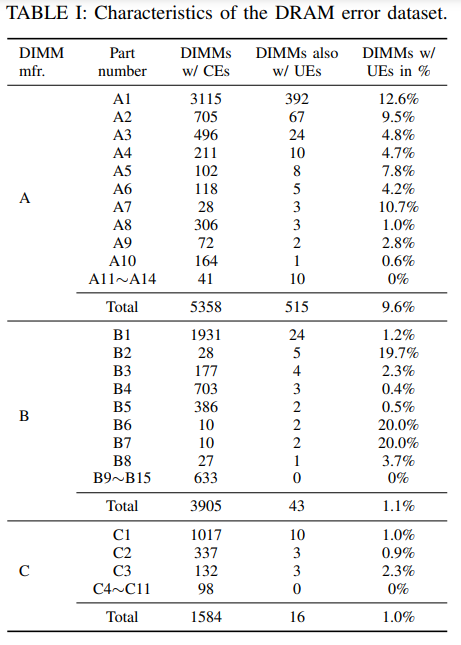
与Chipkill ECC不同,当代英特尔服务器平台上的ECC并不能保证完全覆盖单个芯片在访存过程中数据位上的所有可能错误。虽然精确的ECC算法是高度机密的,并且从未公开过,但英特尔确实概述了一些粗粒度的错误位模式,这些错误位模式被保证是完全可纠正的。如果一个错误的实际错误位模式不能被其中任何一个完全可以纠正的模式所覆盖,则该错误有小概率是不可纠正的。
如图所示,假设将两种完全可纠正模式具象化为图(a)和(b)。图(d)和图(e)所示情况即为完全可纠正的比特错误模式,因为其错误的比特被完全可纠正模式完全覆盖,但是图(c)既不能被(a)覆盖,也不能被(b)覆盖,因此可以被认为存在概率不可纠正,当出现这种情况的CE时,就被认为是Risky CE。
二、新指标
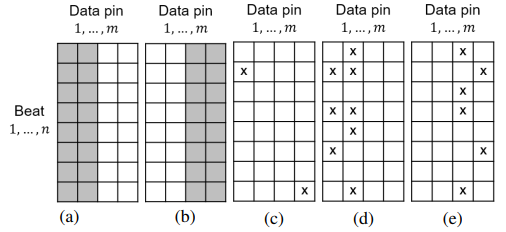
将每个制造商的DIMM分为两个互斥的种群,仅有CE的DIMM和同时有UE的DIMM。图中的 ( a )、( b )和( c )分别比较了来自制造商A、B和C的两个种群的风险CE数的累积分布函数( CDF )。在所有3个DIMM制造商中一致的观察是CDF在风险CE数1处显著偏离。对于仅含CE的DIMMs,80 %以上的风险CE数为0。相比之下,约80 %的DIMMs同时具有UEs,则风险CE数至少为1。这表明风险CE的发生是两个人群之间的一个突出的判别器。值得注意的是,风险CE数大于1并不能提供更好的区分度,因为风险CE数越大,两个CDF的散度就越小。
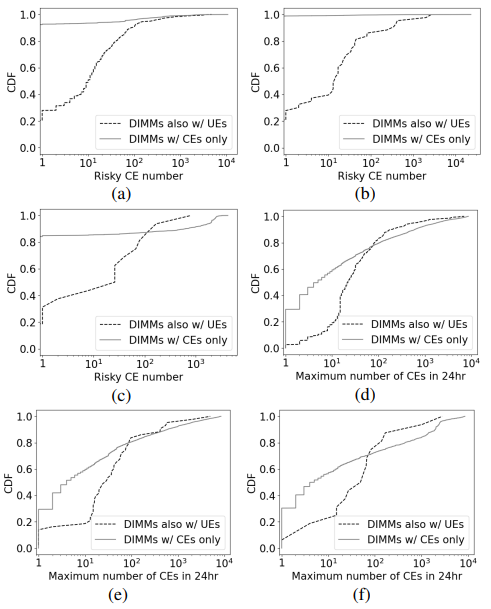
考虑到CE数量作为未来UEs 的常用指标,为了进行比较,分别在图3 ( d )、( e )和( f )中绘制了来自制造商A、B和C的两个种群的最大CE率(即CE历史中过去24小时内的最大CE数)的CDF。两个种群的CDF更接近。无论选择哪种CE速率,它都不能从3个DIMM制造商中的任何一个中提供两个群体之间令人满意的区分。这表明CE率的区分度要低得多。
三、新指标的应用
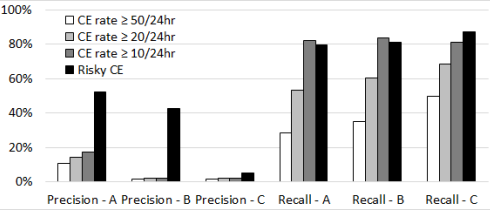
图中显示了直接使用新的风险CE指标对3个制造商的DIMM进行UE预测的准确率和召回率。为了比较,以最常用的预测因子,CE率预测因子的不同参数作为基线。虽然传统的CE率预测器可以达到与低阈值(即过去24小时内有10次CEs)相当的召回率,但其精度明显低于新的风险CE预测器。值得注意的是,即使是来自C厂商的DIMMs,虽然风险CE预测器的精度很低( 5.3 % ),但仍远高于基线( < 2 % )。
四、使UE预测更加精确
1、用于UE预测的学习决策列表
[Part_number:] Risky_CE [∧()]→UE.()
简单的讲,决策列表就是从现象推导到结果。其中,端口号和故障位置是可选的。用于将故障推广到同一厂商的同一端口或者同一故障位置。
文章提出通过迭代识别有信心的预测规则,以精确驱动的方式学习决策列表。在每次迭代中,执行两个步骤。第一步是根据当前的训练数据枚举不同的规则并选择最有信心的(即,精确)规则。第二步是从训练数据中移除新识别规则覆盖的正负训练样本。文章不限制迭代次数。相反,在最佳候选规则的置信度下降到预定义的阈值θ confidence之前,继续决策列表的扩展。通过选择最自信的规则,关注每次迭代中的精度。通过多次迭代扩展列表,逐步提高召回率。
Precision and Recall:
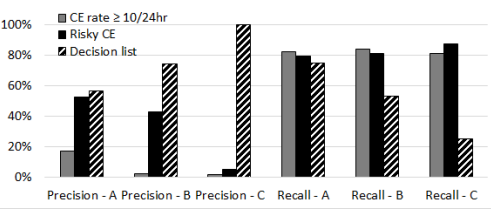
图中显示了新的决策列表方法在在线UE预测中的准确率和召回率。在图中,还将使用新的风险CE指标和性能最好的CE率预测器的UE预测结果进行比较。可见,结合风险CE指标、微观故障指标和DIMM零件编号信息,3个主要厂家的DIMM UE预测精度均得到提高。这种改进对于来自制造商B和C的DIMM来说尤为显著。为了达到更高的精度,召回率变得相当低。
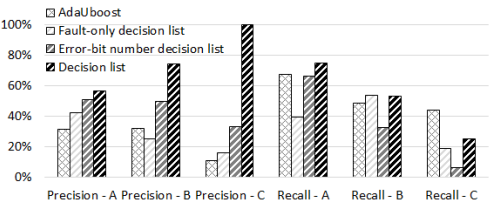
Comparison with Other Baselines:
五、分析
1、How the Decision Lists Look Like:

图中展示了学习到的一些典型的决策列表示例。注意,对于每个制造商的DIMM,从10次交叉验证中学习到10个列表。由于不同运行中训练集的差异,这些列表之间存在较小的差异。这里挑选那些决策列表,它们的规则在许多其他列表中都能观察到。针对不同厂家DIMM的决策列表也存在较大差异,说明针对不同厂家DIMM预测UE需要不同的预测机制。
2、Precision-Recall Trade-off:
在先前图中,第三条规则比第一条规则更具一般性,即任何适用于第一条规则的数据样本也适用于第三条规则。然而,第一条规则以较高的置信度得分。如果将θconfidence (选择规则的置信度阈值)设置为较高的值0.5,则不会选择第三条规则。10折交叉验证的准确率提高了63.1 % ( vs.56.7 % ),召回率降低了32.8 %。这表明提高θ置信度限制了决策列表中选择的规则,从而以较低的召回率换取较高的准确率。
3、Vital Role of the Risky CE Indicator and the DIMM Part Number Information:
由表可知,对于制造商C的DIMM,无论是默认的风险CE指标,还是其与DIMM零件编号信息的简单组合,在UE预测中的表现均不准确。但是,在给定银行故障指示器就位的前提下,将DIMM部件号和风险CE指示器结合在一起提高了精度。

相比之下,去除其中的任何一个都表现得不够好。(注意,在分析单个规则的性能时,使用特定DIMM制造商的所有数据,而不是交叉验证中的测试数据。)实际上,对于制造商C的DIMM,在所有的交叉验证运行中,只学习到了零件编号为C1的DIMM特有的规则。对于其他部件编号的DIMM,数据非常稀疏,即使我们已经在10折交叉验证中使用了90 %的数据进行训练,也无法识别出置信度高于θ confidence的可靠的UE预测规则。
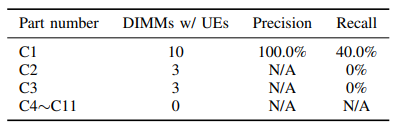
表中给出了不同DIMM部件编号的预测结果,可以看出,对于部分部件编号为C1的DIMM,由于成功识别了UE易发故障,UE预测具有很高的精度( 100 %精度)。该预测覆盖了相当一部分( 40 %召回率)的零件编号的DIMM,但没有覆盖其他零件编号的DIMM。这表明识别出的UE易发故障是特定于某个DIMM部件号的。
4、Importance of Generalization across Different Part Numbers:
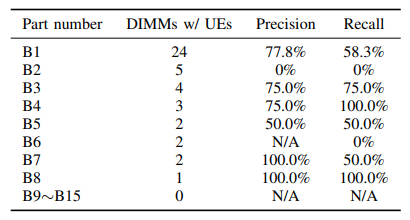
虽然有时DIMM零件编号信息很重要,但在某些情况下,在规则的前提下使零件编号可选,从而允许在同一制造商的不同零件编号之间进行泛化。对于厂商B的DIMM,在10折交叉验证学习到的规则的前提条件中,只看到DIMM零件编号B1的存在。然后将预测结果分解为表中不同的DIMM零件编号。虽然部分编号B3、B4、B5、B7和B8不在学习到的规则的前置条件中,但是一些更通用的规则提供了不错的性能。这表明UE易发故障可以通用于某个DIMM制造商。
编辑:黄飞

















 工商网监
工商网监
评论