 电子发烧友App
电子发烧友App


如何利用神经网络预测闪存尾端延迟的发生
由于用户对低且稳定的延迟(微秒级)的需求越来越大,人们对SSD的百分比延迟越来越关心,即SSD有99%的概率可以提供低且稳定的延迟,但有1%的概率产生几倍于正常情况的延迟,而这1%的高延迟被称为尾端延迟。尾端延迟有什么影响?如何降低尾端延迟的影响?如何在存储环境下利用神经网络?这些疑问,本文将一一解答。
尾端延迟与Hedged Request
百分比延迟
也许你已经查了维基百科中”百分比延迟“的定义,但我想对大多数人而言有点晦涩难懂,下面我将举一个简单的例子以帮助你理解。
首先,我们先列举出一系列收集到的延迟:
23,20,21,20,23,20,45,21,25,25
对它们排序:
20,20,20,21,21,23,23,25,25,45
接下来可以选择前x%的延迟,例如假设我们想要得到50th百分比延迟,则选择前5个延迟:
20,20,20,21,21
然后选择这一组延迟中最大的那个——即21——就是这一组延迟中的50th百分比延迟(也可以写作p50),同理,p90是25。
尾端延迟
尾端延迟就是百分比延迟中末尾的(通常p99之后)那些延迟。看起来尾端延迟占比并不多,但当系统处理的请求达到10^6个数量级,可能足足有104个请求处理延迟远高于正常情况——你不会想成为那不幸的1%,对吗?
分析SSD的内部行为后,本文作者认为尾端延迟的产生源自SSD内部日益复杂的内部活动,如垃圾回收、负载均衡等,和用户请求的冲突。为了降低尾端延迟或者降低尾端延迟的影响,业界提出的方案分为两大类:
白盒子方案
此时SSD内部的行为可知,通过改进SSD内部架构来降低尾端延迟。这种方式无疑是直接而强有效的,但是不利于推广到市场。
灰盒子方案
此时不需要修改SSD的内部架构,但是需要修改上层的软件栈。
黑盒子方案
以各种预测为代表,既不需要修改上层软件栈,也不需要修改SSD内部架构,是目前最流行的解决方案。其中一个经典的方案是Hedged Request,它的原理和应用环境将在下文中介绍。
Hedged Request
为了保证数据安全、实现负载均衡,现代的存储系统通常存在一定冗余,而多个不同的SSD的内部行为同时和用户请求产生冲突的概率非常低。基于这样的思考,Hedged Request将一个请求发给一个SSD后,若等待请求完成的时间超过了阈值,则重发请求到另一个可用的SSD。如下图所示:
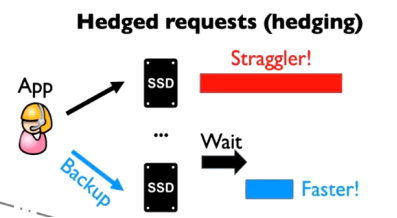
然而,传统Hedged Request中,快SSD需要等待一段时间(等待慢SSD处理的时间超过阈值)后才能处理请求,对于微秒级SSD而言,这个等待时间是致命的。如果可以学习SSD的特征,预测将要变慢的SSD而及时将请求重发到快SSD中,则可以节约出等待的时间,从而降低闪存组的尾端延迟——这就是LinnOS完成的工作,如下图所示,用户发送请求后,若经过LinnOS网络预测得知该SSD将变慢,则提前告知用户重发请求,随后请求将被送到下一个SSD,减少了Hedged Request中的等待时间。
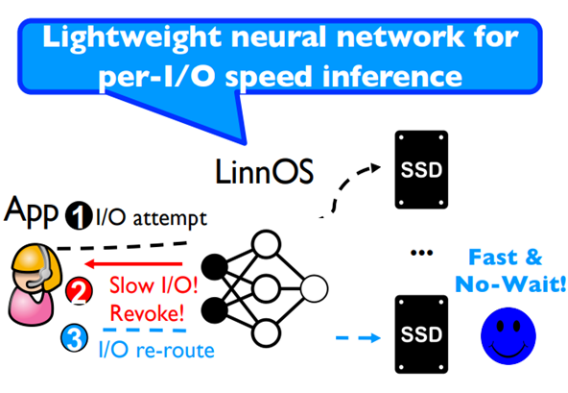
LinnOS的三大挑战
设计LinnOS存在三大挑战,接下来将一一阐述。
对用户输出什么结果?
需要输出具体的延迟(如120μs)吗?虽然这样更灵活,但是一方面,对用户而言,120μs或者125μs其实区别不大,另一方面,如此精确的输出意味着准确率低,并不划算。那么如果输出一个延迟范围,如80~100μs、100~120μs呢?此时准确率稍高了些,但不够(仅60%-70%),处于区间交界处的延迟往往预测不准确。回顾Hedged Request的原理,其实对用户而言,知道SSD是”快“或者”慢“就足够了!所以LinnOS使用简单的二分类模型。
使用什么信息进行预测?
看起来一系列信息都和SSD快或慢有关:读写请求?请求的块内偏移?长期的写入历史?然而,作者发现这些请求都对提高精确度没有明显帮助。首先,由于当前SSD常有内置写缓存,写之后的读延迟常常没有明显提高,更为常见的其实是数据从缓存”冲“(flush)入SSD后,读延迟会更高。其次,一组I/O请求会通过条带均匀地写入各个通道或者芯片,它们写入同一个芯片的概率很低,所以块内偏移这个特征其实并不重要。最后,GC或者flush通常发生时间短,短期写入历史足矣预测。
因此,可以使用SSD当前I/O队列长度来预测SSD快或者慢:一个直观的感受是,当I/O队列较长时,SSD处理通常比较慢。但是这样并不能体现SSD的内部活动的发生,因此额外增加了历史四条请求进入SSD时的队列长度和完成请求的时间。若某个请求进入SSD时队列短而完成请求的时间长,意味着SSD内部行为可能和用户请求冲突了。
如何最小化预测错误的影响?
作者分析发现,若将一个快的SSD预测为慢的从而错误地重发了,将带来微秒级延迟,而若将一个慢的SSD预测为快,将带来毫秒级延迟,比第一种情况严重许多,所以作者在训练时对第二种情况施加了更加严重的惩罚以减少它们的发生。此外,还补充了hedged request以减少预测失败的损失。
实验结果与总结
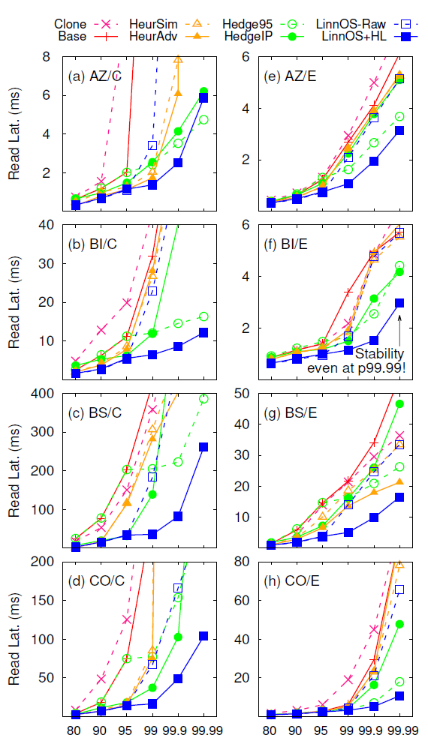
作者上层使用了不同的软件产生负载,底层使用同构的消费级SSD阵列或者异构企业级SSD阵列测试它们的表现,以读延迟为指标展示结果。总共比较了7种不同的方案:
Base:无优化
Clone:同时发送两份请求,选择先返回的SSD的结果返回给用户
Hedge95:等待p95之后重发请求
Hedge IP(inflection point):和上一个相比,使用针对负载优化后的等待时间
HeurSim:队列较长时重发请求
HeurAdv:队列较长、且考虑历史信息(和LinnOS一样)后决定重发请求
LinnOS-Raw:没有hedged补偿的LinnOS
LinnOS+HL:最终的LinnOS方案
实验结果如下图:
审核编辑:刘清









 工商网监
工商网监
评论