 XLNet和Bert比,有什么不同?要进行改进吗?
XLNet和Bert比,有什么不同?要进行改进吗?
1. XLNet和Bert
首先讲讲我对XLNet和Bert比,有什么异同?有什么模型方面的改进?的理解
1.1 自回归语言模型
第一次听到自回归语言模型(Autoregressive LM)这个词。我们知道一般的语言模型都是从左到右计算某个词出现的概率,但是当我们做完型填空或者阅读理解这一类NLP任务的时候词的上下文信息都是需要考虑的,而这个时候只考虑了该词的上文信息而没有考虑到下文信息。所以,反向的语言模型出现了,就是从右到左计算某个词出现的概率,这一类语言模型称之为自回归语言模型。像坚持只用单向Transformer的GPT就是典型的自回归语言模型,也有像ELMo那种拼接两个上文和下文LSTM的变形自回归语言模型。
1.2 自编码语言模型
自编码语言模型(Autoencoder LM)这个名词毫无疑问也是第一次听到。区别于上一节所述,自回归语言模型是根据上文或者下文来预测后一个单词。那不妨换个思路,我把句子中随机一个单词用[mask]替换掉,是不是就能同时根据该单词的上下文来预测该单词。我们都知道Bert在预训练阶段使用[mask]标记对句子中15%的单词进行随机屏蔽,然后根据被mask单词的上下文来预测该单词,这就是自编码语言模型的典型应用。
1.3 两种模型的优缺点对比
自回归语言模型没能自然的同时获取单词的上下文信息(ELMo把两个方向的LSTM做concat是一个很好的尝试,但是效果并不是太好),而自编码语言模型能很自然的把上下文信息融合到模型中(Bert中的每个Transformer都能看到整句话的所有单词,等价于双向语言模型),但自编码语言模型也有其缺点,就是在Fine-tune阶段,模型是看不到[mask]标记的,所以这就会带来一定的误差。XLNet将二者的上述优缺点做了一个完美的结合,在自回归语言模型中自然地引入上下文信息,并且解决自编码语言模型两阶段保持一致的问题。
2. XLNet是怎么做的
XLNet的思路采用的是自回归语言模型,根据上文来预测下一个单词,但是在上文中添加了下文信息,这样就既解决了[mask]带来的两阶段不一致问题和无法同时引入上下文信息的问题。改进之后,取了个新名字:Permutation Language Model。举个例子:输入句子为x1->x2->x3->x4,假设我们要预测的单词是x3,那我们需要在x3的上文x1和x2的位置看到x4的信息,这样才能解决同时引入上下文的问题。那就可以这么做了:随机排列组合x1、x2、x3、x4的顺序,并从中随机选择一部分作为新的句子输入。比如选择了x2->x4->x3->x1,那这个时候预测x3的时候是不是就能看到上文x2和下文x4的信息了呢,这就是XLNet的基本思路。就是通过排列组合的方式将一部分下文单词放到上文单词的位置,但实际形式还是一个从左到右预测的自回归语言模型。
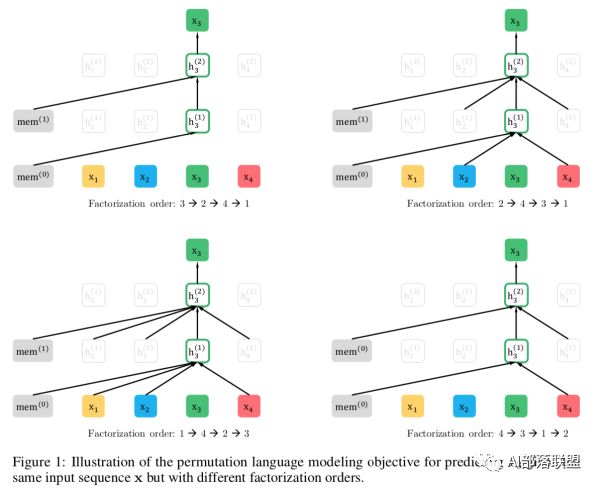
但是我们在Fine-tune的时候总不能也随机组合输入的句子吧,那这和加了[mask]有啥区别呢?别急,继续往下看。XLNet在输入阶段并没有改变输入顺序,随机打乱输入句子的顺序这个过程是在Transformer中通过Attention mask实现的,就是随机掩盖掉序列中的一些单词,并将未掩盖掉的单词作为预测单词的上文。拿原文中的一个图举例:
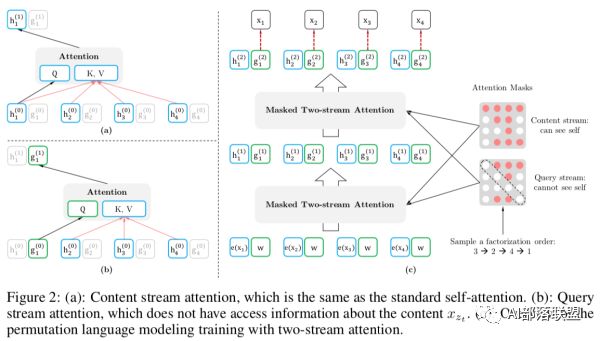
右图的红色矩阵就是Attention Mask矩阵,1->2->3->4的输入序列在Attention Mask的作用下变成了3->2->4->1,Attention Mask也分为两种,一种是能看见自身的Content stream和Query stream。对于1来说3,2,4就是1的上文,所以第一行全是红色;对于2来说上文就只有3,所以对应位置为红色;对于3来说没有上文,所以全为白色...以此类推。那这样就实现了在输入侧不改变单词顺序,在Transformer内部实现了输入的随机排列了。
-
语言模型
+关注
关注
0文章
547浏览量
10365 -
nlp
+关注
关注
1文章
489浏览量
22142
原文标题:讲讲我理解的XLNet
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
J-BERT N4903A高性能串行BERT手册
介绍XLNet的原理及其与BERT的不同点
BERT模型的PyTorch实现
谷歌大脑CMU联手推出XLNet,20项任务全面超越BERT
简化版的XLNet在PyTorch Wrapper实现
XLNet vs BERT,对比得明明白白!
BERT再次制霸GLUE排行榜!BERT王者归来了!

改进版BERT——SpanBERT,通过表示和预测分词提升预训练效果!
语言建模中XLNet比BERT好在哪里
什么是XLNet,它为什么比BERT效果好
比Bert体积更小速度更快的 TinyBERT
如何使用BERT模型进行抽取式摘要





 工商网监
工商网监
评论