 NLP界的“神话”并没那么神?
NLP界的“神话”并没那么神?

曾经狂扫11项记录的谷歌NLP模型BERT,近日遭到了网友的质疑:该模型在一些基准测试中的成功仅仅是因为利用了数据集中的虚假统计线索,如若不然,还没有随机的结果好。这项研究已经在Reddit得到了广泛的讨论。
NLP神话被质疑。
自去年谷歌发布BERT以来,这个曾狂破11项纪录、全面超越人类的NLP模型就备受关注,热度不减。
然而,近日一位Reddit网友却对此抛出质疑:BERT在一些基准测试中的成功仅仅是因为利用了数据集中虚假的统计线索。若是没有它们,可能还没有随机的结果好。
Reddit地址:
https://www.reddit.com/r/MachineLearning/comments/cfxpxy/berts_success_in_some_benchmarks_tests_may_be/
这项论文是由***成功大学的研究人员完成。

论文地址:
https://arxiv.org/pdf/1907.07355.pdf
研究人员表示:
我们惊讶地发现BERT在参数推理理解任务中的峰值性能达到77%,仅比平均未经训练的人类基线低3个点。但是,我们表明这个结果完全是通过利用数据集中的虚假统计线索来解释的。
我们分析了这些线索的性质,并证明了一系列模型都在利用它们。该分析报告了一个对抗性数据集的构造,所有模型都在该数据集上实现随机精度。
Reddit网友lysecret对此研究表示:

他认为这是一种非常简单而有效的方法来表明这类模型是不能正确地做到“理解”的,智能利用(不好的)统计线索。然而,对于大多数人(除了埃隆·马斯克)来说可能都会认为,像BERT这类模型的就是这么做的。
BERT在论证理解方面真的学到什么了吗?
论证挖掘是确定自然语言文本中的论证结构的任务。例如,哪些文本段代表claim,并且包括支持或攻击这些claim的reason。
对于机器学习者来说,这是一项具有挑战性的任务,因为即使是人类也很难确定两个文本段何时处于争论关系中,正如对论证注释的研究所证明的那样。解决这个问题的一个方法是专注于warrant(权证)——一种允许推理的世界知识形式。
考虑一个简单的论点:“(1)正在下雨;因此(2)你应该拿一把伞。” Warrant“(3)弄湿是不好的”可以许可这个推论。知道(3)有助于得出(1)和(2)之间的推论联系。
然而,很难在任何地方找到它,因为warrant通常是隐含的。因此,在这种方法中,机器学习者不仅必须使用warrant进行推理,还要发现它们。
论证推理理解任务(ARCT)推迟发现warrant的问题,并侧重于推理。提供了一个包含claim C和reason R的论点。该任务是在分心器上选择正确的warrant W,称为备选warrant A。
该备选方案的书写方式是R∧A→¬C。之前例子的另一种保证可能是“(4)湿是好的”,在这种情况下我们有(1)∧(4)→“(¬2)你不应该拿伞。”数据集中的一个例子如图1所示。

图1:ARCT测试集中的一个数据点示例以及如何读取它。从R和A到¬C的推论是通过设计得出的。
ARCT SemEval共享任务,验证了该问题的挑战性。即使提供warrant,学习者仍需要依赖进一步的世界知识。
例如,为了正确地对图1中的数据点进行分类,至少需要知道消费者选择和网络重定向如何与垄断概念相关,并且Google是搜索引擎。除了一个参与系统之外,所有参与共享任务的系统的准确度不能超过60%(二进制分类)。
因此,令人惊讶的是,BERT以其最佳运行(表1)实现了77%的测试集精度,仅比平均(未训练的)人类基线低3个点。如果没有为这项任务提供所需的世界知识,那么期望它表现如此之好似乎是不合理的。这就激发了一个问题:BERT在论证理解方面学到了什么?
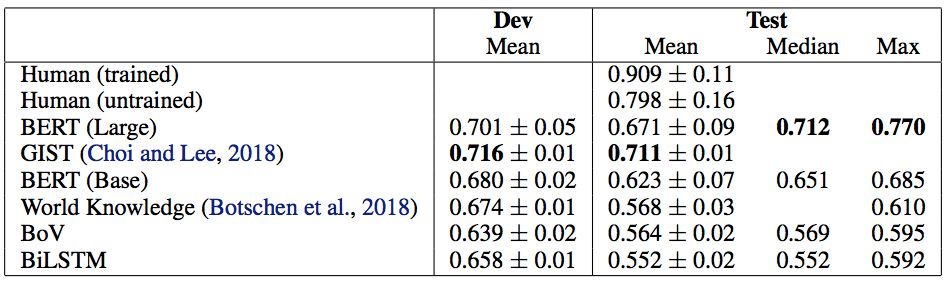
表1:基线和BERT结果。我们的结果来自20个不同的随机种子(±给出标准偏差)。BERT Large的平均值受到5/20随机种子的影响而不能训练,这是Devlin等人提出的一个问题。因此,我们认为中位数是衡量BERT平均表现的更好指标。BERT(大)的非退化运行的平均值为0.716±0.04。
为了研究BERT的决策,工作人员研究了数据点,发现在多次运行中很容易分类。对SemEval提交进行了类似的分析,并且与他们的结果一致,发现BERT利用了warrant中提示词的存在,特别是“not”。通过探索旨在隔离这些影响的实验,研究人员在这项工作中证明了BERT在利用虚假统计线索方面的惊人之处。
但是,结果表明ARCT是可以消除主要问题的。由于R∧A→¬C,我们可以添加每个数据点的副本,其中claim被否定并且标签被反转。
这意味着warrant中统计线索的分布将反映在两个标签上,从而消除了信号。在这种对抗性数据集上,所有模型都是随机执行的,BERT实现了53%的最大测试集精度。
因此,对抗性数据集提供了对参数理解的更可靠的评估,并且应该被用作该数据集的未来工作的标准。
实验表明:BERT并不能做出正确“理解”,只能利用统计线索
如果一个模型正在利用标签上的分布线索,那么如果只训练warrant(W),它应该表现得相对较好。
同样的道理也适用于仅删除claim、保留reason和warrant(R,W)或删除reason(C,W)。
后一种设置允许模型额外考虑reason和claim中的线索,以及与warrant组合相关的线索。
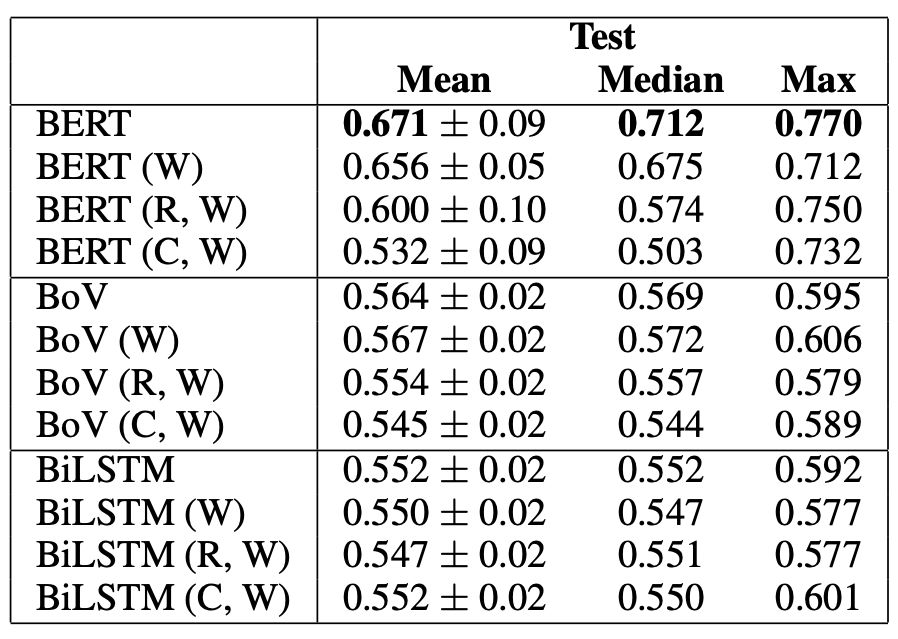
表3用BERT Large、BoV和BiLSTM作为基线探测实验结果
实验结果如表3所示。仅在warrant(W)上,BERT的准确率最高可达71%。与其最高峰值的77%差了6个百分点。
而(R,W)比(W)增加了4个百分点,(C,W)增加了2个百分点,这就是刚才说到了那6个百分点。
基于这一证据,研究人员发现BERT的全部表现可以通过利用虚假的统计线索来解释。
对抗性测试集
由于数据集的原始设计,消除了ARCT中标签统计线索的主要问题。
鉴于R∧A→¬C,可以通过否定claim并反转每个数据点的标签来产生对抗性示例(如图4所示)。

图4 原始和对抗数据点。claim被否定,warrant被交换。W和A的标签分配保持不变。
然后将对抗性示例与原始数据进行组合。这通过镜像两个标签周围的提示分布来消除该问题。
验证和测试集中大多数claim的否定已经存在于数据集中的其他地方。剩下的claim被一个以英语为母语的工作人员人工进行动否定。
研究人员尝试了两种实验设置。
首先,在对抗集上评估在原始数据上训练和验证的模型。由于过度拟合原始训练集中的线索,所有结果都比随机差。
其次,模型在对抗性训练和验证集上从头开始训练,然后在对抗性测试集上进行评估。其结果如表4所示。
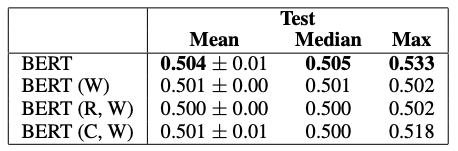
表4 BERT Large在具有对抗性训练和验证集的对抗性测试集上的结果。
BERT的峰值性能降低至53%,平均值和中值为50%。从这些结果中得出结论,对抗性数据集已成功地消除了预期的线索,从而提供了对机器参数理解的更可靠的评估。
这一结果更符合研究人员对这个任务的直觉:由于对这些论点背后的现实知之甚少或一无所知,良好的表现应该是不可行的。
任务描述、基线、BERT与统计线索
任务描述和基线
设t i = 1, . . . ,n索引数据集D中的每个点,其中| D | = n。在每种情况下,两个候选warrant被随机分配二进制标签j ∈ {0, 1},使得每个具有相同的正确概率。输入是c(i)的表示,reason r(i),保证零w0(i),并且保证一个w1(i)。标签y(i)是对应于正确授权的二进制指示符。所有模型的一般体系结构如图2所示。学习共享参数θ以独立地使用参数对每个warrant进行分类,得到 logit:
zj(i)=θ[c(i);r(i);wj(i)]
然后将它们连接起来并通过softmax以确定两个warrant上的概率分布p(i)= softmax([z0(i),z1(i)])。那么预测是y(i)= arg maxjp(i)。基线是一包载体(BoV),双向LSTM(BiLSTM),SemEval获胜者GIST,Botschen等人的最佳模型,人类表现(表1)。对于我们的所有实验,我们使用网格搜索来选择超参数,退出正则化和Adam进行优化。当验证准确度下降时,我们将学习率anneal1/10。最终参数来自具有最大验证精度的epoch。BoV和BiLSTM输入是在640B上训练的300维GloVe嵌入。GitHub上提供了重现所有实验和详细说明所有超参数的代码。(https://github.com/IKMLab/arct2)
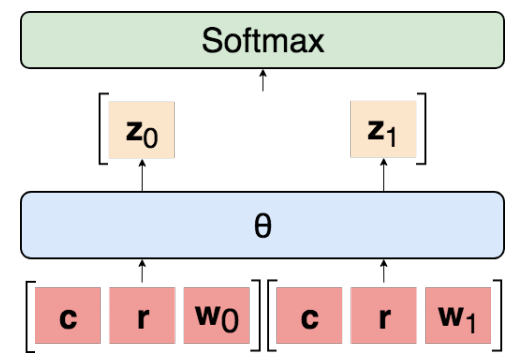
图2:我们实验中模型的一般架构。为每对argument-warrant独立计算 logit,然后连接并通过softmax传递。
BERT
我们的BERT分类器如图3所示。claim和reason连接在一起形成第一个文本段,与每个warrant配对并独立处理。将最终层CLS向量传递到线性层以获得对数zj(i)。整个架构都经过精心调整。学习率为2e-5,我们允许最多20个训练期,从最佳验证集准确度的时期获取参数。我们使用Hugging Face PyTorch实现。
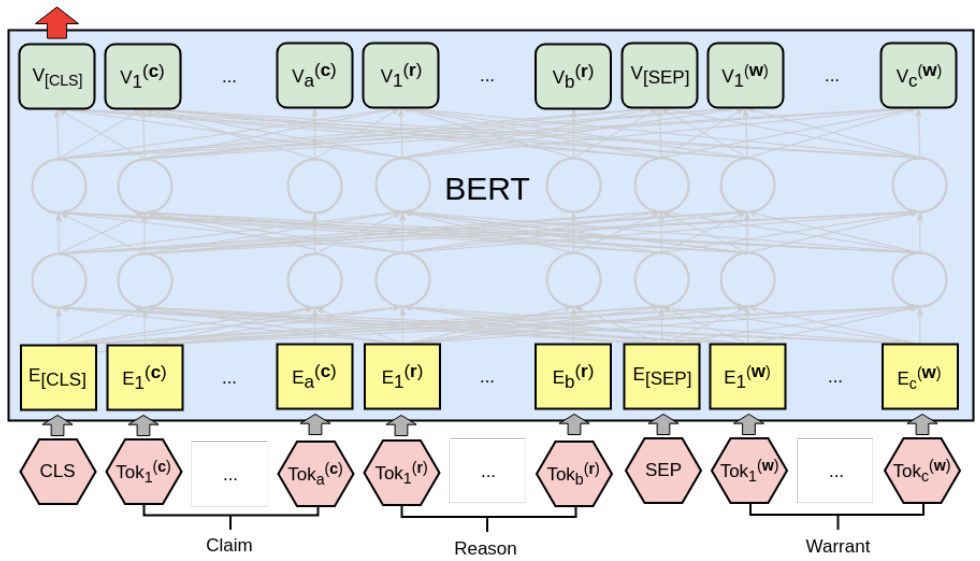
图3:使用BERT处理参数一对argument-warrant。reason(长度为a的单词)和claim(长度b)一起形构成第一句话,而warrant(长度c)是第二句。然后将最终的CLS矢量传递到线性层以计算 logit zj(i)。
Devlin et al.报告说,在小型数据集上,BERT有时无法训练,产生退化的结果。ARCT非常小,有1210次训练观察。在5/20运行中,我们遇到了这种现象,在验证和测试集上看到接近随机精度。这些情况发生在训练准确性也不明显高于随机(<80%)的情况下。除去退化曲线,BERT的平均值为71.6±0.04。这将超过先前的技术水平 - 中位数为71.2%,这是一个比整体平均值更好的平均值,因为它不受退化情况的影响。但是,我们的主要发现是这些结果没有意义,应该被丢弃。在接下来的部分中,我们将重点放在BERT的77%峰值性能上。
统计线索
ARCT中虚假统计线索的主要来源是标签的不均匀分布。接下来便将展示这些线索的存在和性质。
虽然可能存在更为复杂的线索,但是研究人员只考虑了一元图和二元图的情况。
研究人员的目标是计算模型利用线索k的有益程度,以及它在数据集中的普遍程度(表示信号的强度)。
首先,定义几个概念:
线索的适应性(applicability):αk,定义为在一个标签上出现的数据点数;
线索的生产率(productivity):πk,定义为预测正确答案的适用数据点的比例;
线索的覆盖率(coverage):ξk,定义为适用情况占数据点总数的比例。
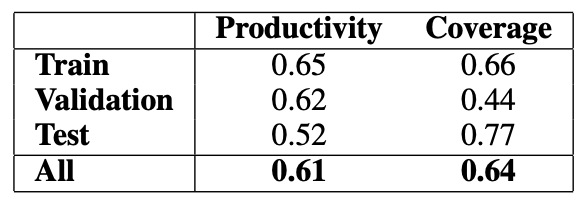
表2 适用“not”在warrant中的存在来预测ARCT中标签的生产率和覆盖率。
表2给出了研究人员发现的最强的unigram线索(“not”)的生产率和覆盖率。它提供了一个特别强的训练信号。虽然它在测试集中的效率较低,但它只是许多这样的线索之一。
研究人员还发现了许多其他的unigram,尽管总体生产率较低,但大多数是高频词,如“is”、“do”和“are”。与“not”连用的bigram,如“will not”和“can”,也被发现是高效的。
-
数据集
+关注
关注
4文章
1242浏览量
26282 -
自然语言
+关注
关注
1文章
293浏览量
14036 -
nlp
+关注
关注
1文章
491浏览量
23355
原文标题:台湾小哥一篇论文把BERT拉下神坛!NLP神话缺了数据集还不如随机
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
揭秘:是什么造就了苹果神话?
NLP的介绍和如何利用机器学习进行NLP以及三种NLP技术的详细介绍

NLP-Progress库NLP的最新数据集、论文和代码
一位NLP算法工程师对NLP的看法
NLP 2019 Highlights 给NLP从业者的一个参考
NLP技术对BI而言有那么重要吗?
知识图谱是NLP的未来吗?




评论