 智能语音对抗攻击面临的四大挑战
智能语音对抗攻击面临的四大挑战
随着人工智能技术的快速发展,语音成为一种新型的人机交流方式,如我们手机上的语音助手Apple Siri、Google Assistant和Microsoft Cortana等,智能音箱Google Home、Amazon Echo、阿里巴巴的天猫精灵和小米的小爱同学等等。它们方便了人类与机器交互的同时,不仅连接了Twitter、Facebook这样的社交网络,也将汽车、智能门锁和智能电视等物联网设备连接起来。
由此可见,语音交互越来越多地关系着人们的生命和财产安全,因此,智能语音的安全性也成为工业界和学术界的研究重点。
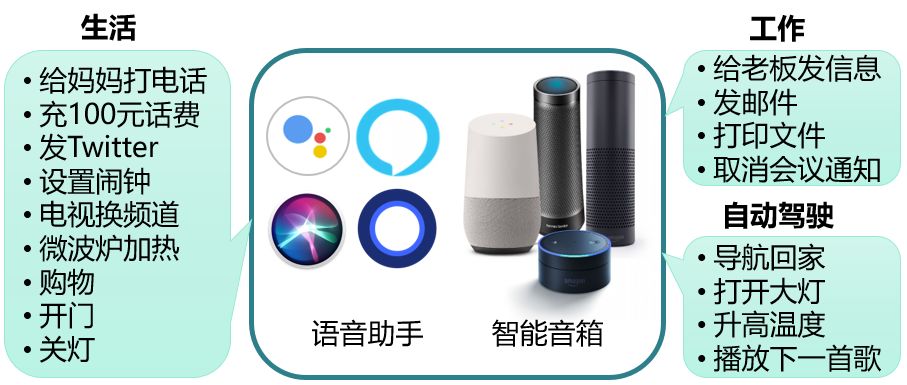
图1 智能语音的应用
传统攻击通过安装恶意应用和传播病毒等途径入侵到系统中,但是如何实现智能化的攻击方式还未知。既然声音成为人机交互的新型方式,那么利用声音欺骗人工智能系统成为一种攻击方法,同时能够突破传统方式需要接触设备的局限性。为了在人耳无法觉察的情况下让智能语音设备识别出里面的指令,加州伯克利分校和浙江大学的研究学者分别将语音信息嵌入到了噪声和超声波之中,从而控制智能语音助手和音箱[1][2]。
结合日常生活中大家喜欢听音乐的习惯,中国科学院信息工程研究所陈恺研究员和波士顿大学Shengzhi Zhang教授等人实现了利用音乐为载体攻击语音识别系统的研究[3],这种特殊修改过的音乐被称为是“恶魔音乐”。试想,如果我们在开车或者家中听的广播是攻击者精心制作的“恶魔音乐”,人耳听起来并不能觉察出什么异常,但是智能语音系统却能识别出其中“开门”的控制命令,那么将对我们的安全构成难以控制的威胁。
图2 “恶魔音乐”在人们享受音乐的时候与智能语音系统对话
对抗攻击:类似于生活中人类感观误识别的问题,智能系统也有一定的误判。因此,研究者想到通过对一个正常样本做微小的修改,然后在人们感观觉察不出来有什么差异的情况下对智能系统造成对抗攻击,这种欺骗人工智能系统的特殊样本被称为是“对抗样本”。从2013年开始大家特别关注对抗攻击,利用梯度下降算法自动化地在原始样本上加微小扰动形成对抗样本,在人类无法觉察的同时让机器识别错误,从而造成逃逸攻击。
图3 对抗样本攻击
针对智能语音的对抗攻击:如果把语音识别系统看成一个API接口,音频以wav格式为代表,那么音频wav有两种途径传输给语音识别系统API(1)直接输入(2)播放音乐并通过实际应用环境中的物理设备采集之后再输入给API。因此,对抗样本攻击分别可以视为“Wav-to-API(WTA)攻击”和“Wav-air-API(WAA)攻击”。
图4 “恶魔音乐”直接上传给语音识别API的WTA攻击
图5 “恶魔音乐”在实际环境中播放再由智能设备采集识别的
WAA攻击
智能语音对抗攻击存在下面四个挑战:
自动化:需要找到合适的目标函数,利用梯度下降方法在原始样本上添加扰动逼近目标函数,使最终生成的对抗样本可以被识别为特殊的文本结果。
物理攻击:实际应用中播放、录音设备以及周围环境噪声会对样本的特征造成干扰,难以实现物理攻击。
隐蔽性:在保证成功率的前提下尽可能小地修改原始样本,逃过人耳的觉察。
迁移性:在一个平台上攻击成功的对抗样本同样可能攻击其他平台,但是由于平台之间的差异性,样本的迁移性通常比较低。
语音识别原理
传统语音识别包括特征提取、声学模型和语言模型三个模块。其中特征提取是对时域信号分帧并计算每帧的频域特征,通过一系列的变换最终得到模拟人耳的听觉特征。声学模型描述的是特征的统计特性和实际发声的音素对应关系,音素是组成单词的最小单元,这一模型由神经网络训练得到。由于语言有一定的语法、词法规则,人们训练出语言模型表示音素、字、词、句之间的关联关系,语言模型由加权有限状态转换器表示。具体来看这个语音识别过程:首先提取音频的特征向量,然后计算观察状态的统计特性,对应出这些状态代表音素的可能性概率值,进而计算音素上下文关联的状态转换关系,最后计算出特征向量对应音素序列概率最大的路径,这个路径对应的句子就是识别(解码)结果。
图6 语音识别原理
音频直接上传给系统的WTA攻击
语音识别不同于图像识别的是:声学模型需要结合后面的语言模型共同决定识别结果,而且由于发音的延续性,语音识别受一定的上下文关系影响。由于语言模型结构复杂,攻击者可以首先逆向分析出什么样的声学模型输出结果(神经网络的计算结果)一定会被解码成目标文本,然后以这样的输出结果作为目标函数修改原始音频,直到生成的对抗样本达到或者非常接近这个目标,那么这个对抗样本就能够被识别为想要的文本。确定目标函数后,进一步用梯度下降算法修改x(t)逼近这个目标函数,从而生成修改幅度较小的对抗样本x‘(t)=x(t)+δ(t),即直接将音频上传给语音识别系统API的WTA攻击已经成功。
图7 WTA攻击原理图
物理世界的WAA攻击
考虑到实际生活应用中,音乐通常是被播放出来再被语音识别系统录音接收的,这里播放和录音设备的电子噪声以及环境的背景噪声均会对嵌入音频的特征进行破坏,直接的办法是在对抗样本生成过程中引入“噪声模型”模拟这种影响。即在对抗样本生成过程中加入模拟的噪声,保证这样之后仍然能够被系统识别为目标指令,那么嵌入到音乐中的音频特征就足够强到可以抵抗实际噪声的破坏。但是由于对实际应用中噪声建模需要大量工作,可以采用“随机噪声”代替,从而很大程度上简化噪声模型的构建过程,同时由于随机噪声不拘泥于模拟特殊的设备和环境影响,这种方式生成的对抗样本具有更强的适应能力,可以很好地实现多种设备及多种环境下的物理攻击。
图8 WAA攻击原理图
智能语音安全问题越来越多地受人们重视,本文介绍了一种针对传统语音识别的对抗攻击方法。通过逆向分析语音识别算法,挖掘深度神经网络的脆弱性,然后采用梯度下降算法自动化地修改音乐生成对抗样本,即生成“恶魔音乐”在人们无法觉察的情况下攻击语音识别系统。进一步通过引入噪声模型模拟实际应用场景中设备和环境噪声的影响,提升对抗样本的鲁棒性,从而能够在实际应用中攻击商业化平台(如科大讯飞的讯飞输入法),而且这种攻击通过网络或者无线信号传播之后攻击仍然有效。
对抗样本是人工智能安全应用的一个重要威胁,挖掘深度学习算法的脆弱性,研究深度学习的对抗攻防技术对于人工智能落地具有重要意义。目前来看,提高对抗样本的隐蔽性、迁移性和物理攻击成功率还有很远的路要走。
-
语音识别
+关注
关注
38文章
1742浏览量
112710 -
智能语音
+关注
关注
10文章
786浏览量
48810
原文标题:CommanderSong:“恶魔音乐”攻击智能语音识别系统
文章出处:【微信号:bdtdsj,微信公众号:中科院半导体所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
《具身智能机器人系统》第10-13章阅读心得之具身智能机器人计算挑战
鉴源实验室·如何通过雷达攻击自动驾驶汽车-针对点云识别模型的对抗性攻击的科普
人工智能的语音识别技术详解
随机通信下多智能体系统的干扰攻击影响研究






 工商网监
工商网监
评论