 实行实时3D目标检测的方法讨论
实行实时3D目标检测的方法讨论

基于激光雷达的三维目标检测对于自动驾驶而言是不可避免的选择,因为它与对环境的理解直接相关,从而为预测和运动规划奠定了基础。对于除了自动化车辆之外的许多其他应用领域,例如增强现实、个人机器人或工业自动化,对实时高度稀疏的三维数据进行推断的能力是一个不合适的问题。
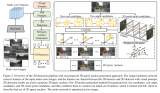
我们引入了Complex-YOLO,这是一种最先进的仅针对点云(point clouds)的实时三维目标检测网络。在本研究中,我们描述了一个网络,该网络通过一个特定的复杂的回归策略来估计笛卡尔空间(Cartesian space)中的多类三维立方体,从而扩展YOLOv2(一种用于RGB图像的一个快速二维标准目标检测器)。
因此,我们提出了一个特定的Euler区域提议网络(Euler-Region-Proposal Network,E-RPN),通过在回归网络中添加一个虚构的和一个真实的分数来估计目标的姿势。这是在一个封闭的复杂空间中结束的,从而避免了单角度估计的奇异性。E-RPN支持在训练过程中进行良好的泛化。
我们在KITTI基准套件上进行的实验表明,我们的性能优于当前领先的三维目标检测方法,尤其在效率方面。我们取得了对汽车、行人和骑车者进行测试的最先进的结果,比最快的竞争者快5倍以上。此外,我们的模型能够同时以高精确度估计所有的8个KITTI类,包括货车、卡车或坐着的行人。
近年来,随着汽车激光雷达传感器的巨大完善,点云处理对自动驾驶而言变得越来越重要。供应商的传感器能够实时提供周围环境的三维点。其优点是直接测量所包含的目标之间的距离。这使我们能够开发出用于自动驾驶的目标检测算法,该算法能够精确地估计出三维中不同目标的位置和航向。与图像相比,激光雷达点云稀疏,其密度分布在整个测量区域中变化。这些点是无序的,它们在本地进行交互,并且主要是不能被孤立分析。点云处理对于基本转换应该是始终保持不变的。
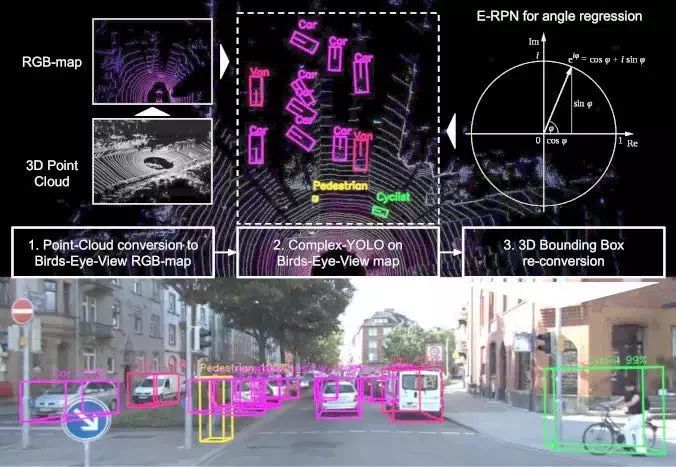
Complex-YOLO是一个非常有效的模型,可直接在仅基于激光雷达的鸟瞰RGB视图上进行操作,以估计和精确定位3D多类边界框。该图的上半部分显示了诸如预测目标等基于Velodyne HDL64电云的鸟瞰图,下半部分显示3D边界框被重新投影至图像空间中。注意:Complex-YOLO仅基于激光雷达进行操作,而不需要相机图像作为输入。
一般而言,基于深度学习的目标检测和分类是众所周知的任务,并且在图像的2D边界框回归的建立中得到了广泛应用。研究的重点主要是精确度和效率的权衡。在自动驾驶领域,效率更为重要。因此,最好的目标检测器往往使用区域提议网络(RPN)或类似的基于网格的RPN方法。这些网络非常高效、准确,甚至能够在专用的硬件或嵌入式设备上运行。尽管点云上的目标检测依然很少,但它们正变得越来越重要。这些应用程序需要能够预测3D边界框。目前,主要有三种不同的深度学习方法:
使用多层感知器的直接点云处理。
通过使用卷积神经网络(CNN)将点云转换为体素或图像堆栈。
组合式融合方法。
最近,基于Frustum的网络在KITTI 基准套件中表现出了很好的性能。该模型在3D目标检测方面排名第二,在汽车、行人和骑行者的鸟瞰检测方面同样排名第二。这是唯一的方法,它直接使用Point-Net直处理点云,而不使用激光雷达数据和体素创建中的CNN。
然而,它需要预处理,因此它必须使用相机传感器。基于另一个对标定的相机图像进行处理的CNN,它通过利用这些检测将全局云点最小化到基于截面的已减少点云。这种方法有两个缺点:
模型的精准度在很大程度上依赖于相机图像及其相关的CNN。因此,该方法不可能仅适用于激光雷达数据。
整个管道需要连续运行两种深度学习方法,这会导致运算时间更长而效率更低。参考模型在NVIDIA GTX1080i GPU上大约以7fps的低帧率运行。
与之相反,Zhou等人提出了一种仅适用于激光雷达数据的模型。就这方面而言,它是KITTI上仅使用激光雷达数据进行3D和鸟瞰探测的最佳模型。其基本思想是在网格单元上运行端到端的学习,而不使用人工制作的特征。网络单元格的内部特征是在训练期间利用Pointnet方法学习的。在顶部建立一个预测3D边界框的CNN。尽管拥有很高的精准度,但该模型在TitanX GPU上的最快运算时间为4fps。
Chen等人报道了另一种排名很靠前的方法。其基本思想是利用人工制作的特征将激光雷达点云投影到基于体素的RGB地图上,如密度、最大高度和一个具有代表性的点强度。为了获得具有更高精准度的结果,他们使用了基于激光雷达的鸟瞰图,基于激光雷达的前视图以及基于相机的前视图的多视图方法。这种融合处理需要很长时间,即便在NVIDIA GTX 1080i GPU上也仅为4fps。另一个缺点是需要辅助传感器输入(相机)。

空间真实数据分布。上图左侧的样本检测描绘了鸟瞰区域的大小,右侧图显示了《我们准备好了自动驾驶吗? kitti视觉基准套件》中所注释的2D空间直方图。该分布概述了用于注释的照相机的水平视野以及地图中遗留的盲点。
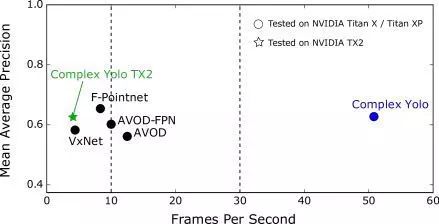
性能比较。该图显示了与运行时间(fps)相关的mAP。所有模型都在Nvidia Titan X或Titan Xp上进行测试。Complex-Yolo的运行速度比KITTI基准测试中最有效的竞争对手快5倍,进而获得准确的结果。我们在一个专用的嵌入式平台(TX2)上对我们的网络进行了测试,并与五种领先的模型进行了比较,结果表明我们的网络具有合理的效率(4fps)。Complex-Yolo是首个用于实时3D目标检测的模型。
本文首次提出了基于激光雷达的点云3D目标检测的第一个实时高效深度学习模型。我们在KITTI基准测试套件中就精准度(如上图所示)而言突显了我们最新的成果,其卓越的效率超过50fps(NVIDIA Titan X)。我们不像大多数主流方法那样需要额外的传感器,例如相机。这一突破是通过引入新的E-RPN(一种借助复杂数字来估计方位的Euler回归方法)实现的。无奇点的封闭数学空间允许鲁棒角度预测。
我们的方法能够在一条前进的道路上同时检测多种类别的目标(例如:汽车、火车、行人、骑行者、卡车、有轨电车、坐着的人等)。这种全新的方法可以在自动驾驶汽车中实现落地应用,并且以此来区别于其他车型。我们甚至在专业的嵌入式平台NVIDIA TX2(4fps)展示了实时性能。在今后的研究工作中,我们计划在回归中加入高度信息,在空间中真正实现独立3D目标检测,并在点云预处理过程中利用速度-空间相关性,以获得更好的分类性能和更高的精准度。
-
3D
+关注
关注
9文章
3024浏览量
115595 -
激光雷达
+关注
关注
982文章
4554浏览量
197120
发布评论请先 登录
iTOF技术,多样化的3D视觉应用
如何实行温度实时检测
热点技术讨论:3D设计中的挑战
京东方推出裸眼3D产品 可实时转换2D和3D画面
谷歌开发pipeline,在移动设备上可实时计算3D目标检测
基于图像的3D目标检测是自动驾驶领域综述
为什么选择3D,3D芯片设计要点分析
如何利用车载环视相机采集到的图像实现精准的3D目标检测
CCV 2023 | SparseBEV:高性能、全稀疏的纯视觉3D目标检测器

如何搞定自动驾驶3D目标检测!

Nullmax提出多相机3D目标检测新方法QAF2D



评论