 关于华为AI芯片的性能分析和介绍
关于华为AI芯片的性能分析和介绍
日前,华为公布了其最新的AI芯片战略,并正式推出了基于达芬奇架构设计的的云端和边缘端的AI芯片。作为国内ICT产业、集成电路领域的一个重要角色,华为的这次公布,让行业内的人沸腾了。甚至出现了华为将在云端AI芯片领域干掉英伟达、谷歌,在边缘端会对这个领域的AI芯片初创者或者老玩家带来灭顶之灾。但华为真的有那么强大的影响力吗?我们来看一下本文作者对华为战略和整个市场影响力的分析。
近日,华为在联接大会2018发布了其全栈全场景AI解决方案,涵盖了从终端到云端,从AI芯片到深度学习训练部署框架的多层解决方案,其在AI领域投入的决心可谓巨大。然而,如果仔细分析其具体落地,我们会发现华为的战略特别实用主义,并没有去刻意追求技术上的精致,而是快速做了一个能满足需求的框架,以求先占领市场再做迭代。本文将着重对华为的AI芯片战略做一分析,并加入一些华为AI芯片对整个产业影响的个人观点。
多战场全覆盖:华为的雄心壮志
华为在本次大会上公布了其AI战略,涉及的产品无论是深度还是广度都是非常惊人的。首先,从深度来说,其AI相关产品生态包含了从应用接口ModelArt(用于客户的应用直接接入AI功能),中层深度学习软件框架MindSpore,软硬件接口层CANN,直到专用硬件Ascend系列,最终可以为终端和云端的应用赋能。
华为的AI战线之深可谓是全球一流,仅有Google、百度等技术导向明显的互联网公司可以与之匹敌(Google拥有最流行的深度学习框架TensorFlow和芯片TPU,百度则拥有深度学习框架PaddlePaddle和芯片XPU),而诸如微软、亚马逊、腾讯等其他云服务领域厂商的战线深度,尤其是在硬件领域的投入决心,都远远不及华为。

华为的战线如此之深,究其原因无外乎是“有纵深才能有壁垒”。
对于华为这样的巨头公司而言,只有把握住了生态链上的每一个环节,把开发者和用户的整个使用循环全部保留在自己的生态圈内,才能形成真正的壁垒,否则只要在任何环节存在空白或者弱项,就有被竞争对手或者新兴公司单点突破的机会。而这样的壁垒一旦形成,不仅仅可以完成对于竞争对手的防御,更可以在整体生态上获得极高的利润——由于完整技术栈的不可替代性,从而可以收获大量利润。Nvidia就是把自己凡是能接触到的生态环节都打通并做到极致的公司,从而产生了极高的壁垒:硬件上有GPU,深度学习框架和软硬件接口层有CuDNN和TensorRT,因此在这几年深度学习人工智能高速发展中,Nvidia几乎占据了不可替代的地位。
然而,Nvidia人工智能生态中的底层硬件GPU却存在破绽,由于GPU对于人工智能算法的支持并非完美,因此造成了计算效率不高,也引得群雄逐鹿,众多公司纷纷进入人工智能芯片的战场。从这个角度来看华为正在做挑战Nvidia的事情,借着Nvidia GPU做人工智能效率低的弱点,希望构建自主的技术生态来取而代之。
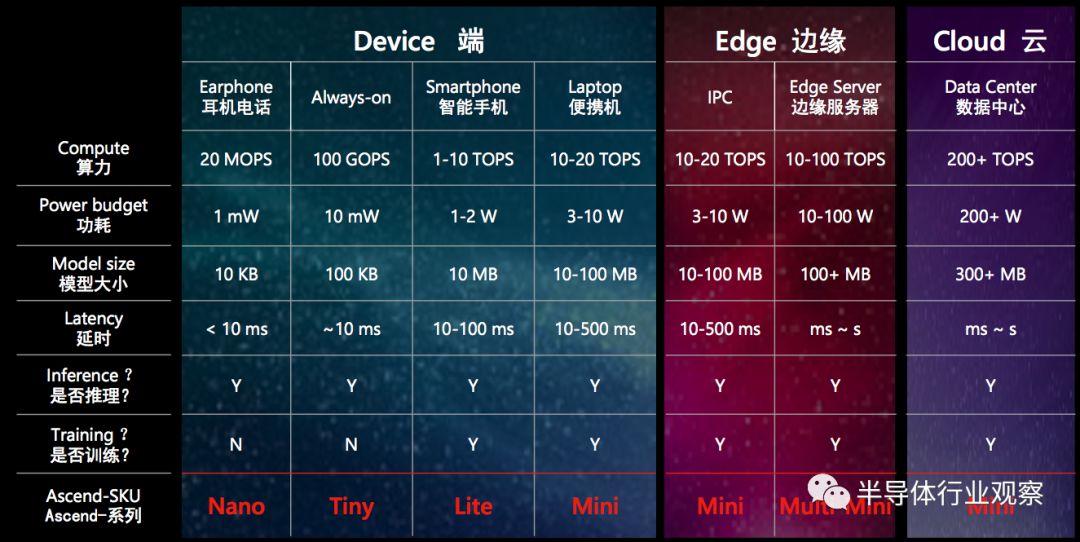
出了纵向深度之外,华为的战线横向也铺得很开。一旦有了一个设计完善的纵向框架,那么把这个框架在不同算力需求尺度上推广上将是非常容易的,对于华为这样以执行力强著称的公司来说这样的平推战术更是得心应手。一旦战略的深度和广度上都得到良好的执行,其最终的收益将是乘数效应(即收益正比于深度x广度),从而带来惊人的回报。从华为的战略广度来看,既包含终端(低功耗,中低算力),也包含边缘(中等功耗,中等算力)和云(高功耗,高算力)。在之前,华为的业务领域早已包含了从端(华为/荣耀手机以及智能家电)到云(华为云),因此在之前的业务上再部署推广人工智能可谓是水到渠成。
唯快不破:“达芬奇”架构
华为同时注重深度和广度的人工智能战略是以技术为基石的,而其技术栈中最具有挑战性,同时也是最具有区分度的就是底层芯片。为了满足华为战略上的需求,其芯片技术需要满足以下需求:
性能好,否则难以撼动Nvidia的位置,这毫无疑问是战略深度中最重要的一个要素;
设计可伸缩性好,同一架构可以通过修改设计规模快速部署到不同算力尺度的应用,从而实现战略广度快速铺开的需求;
通用性好,能兼容尽可能多的操作;
上市速度要快。
以上四点要同时满足是非常困难的,尤其是一些非常痴迷于技术的公司,往往会选择去探索新的芯片架构以把前三个需求做到极致,这也就意味着放弃了第四个能快速上市的需求,因为新架构往往意味着较长的研发周期和较大的风险,难以做到快速上市。而华为的选择则是在传统架构上做足够的工程优化,并不追求极致性能,但求能满足用户需求并快速落地。与之对应的是华为使用在Ascend系列芯片中的达芬奇架构。
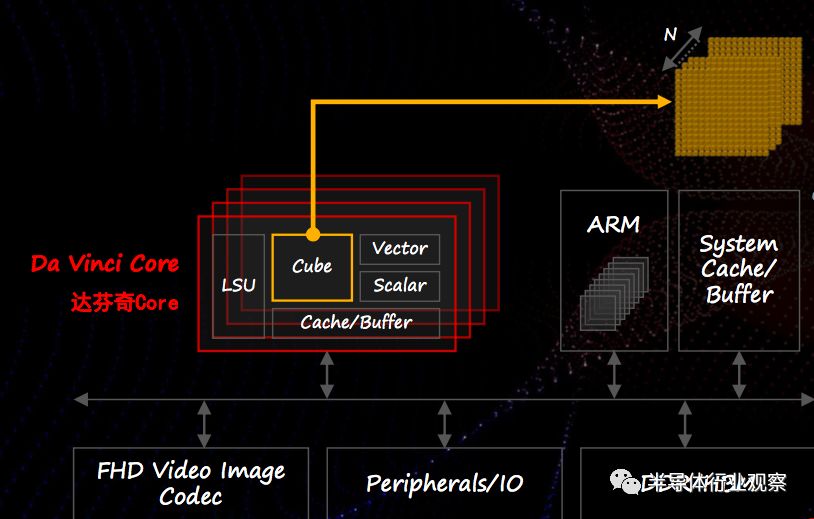
从Ascend芯片的架构来看,其实就是传统的ARM核+AI加速器的模式,而其AI加速器就是达芬奇核心。达芬奇核心从架构上看起来也并没有使用炫技式的前沿技术,而是简单直接地把计算用的乘加器(MAC)按照不同的计算组织成不同的方式,并搭配标准的数据缓存。当要做人工智能相关的计算时,可以使用按cube(“三维立方”) 模式组织的MAC群,从而支持相关计算。当需要其他常规计算时,则可以使用矢量或标量计算MAC。对于不同规模的芯片,可以通过放置不同数量的达芬奇核心来满足需求,因此同一个达芬奇核心的设计可以灵活地满足华为战略横向上不同应用的需求。
这次的大会上,华为发布了Ascend 910和Ascend 310,其中Ascend 910针对云端应用,使用7nm工艺在350W的功耗上实现了256 TOPS半精度浮点数算力或512 TOPS 8位整数算力,并且集成了128通道全高清视频解码器;而Ascend 310针对边缘应用,使用12nm工艺在7W的功耗上实现了8 TOPS半精度浮点数算力或16 TOPS 8位整数算力,并且集成了单通道全高清视频解码器。从中,我们可以看到华为的战略横向野心很大,但是第一个落地的市场看来还是机器视觉市场。
从公布的芯片性能上来看,这次Ascend 910以及Ascend 310特意提到了视频解码器,显然是与视频应用有关;此外,达芬奇架构中的cube式MAC阵列估计也是为了同时兼顾云端训练应用和机器视觉推理应用而做的选择。从技术上看,cube式MAC阵列非常适合卷积神经网络。卷积神经网络是目前机器视觉应用最流行的模型,而机器视觉应用则可以说是这一波人工智能应用中落地幅度最大的。在卷积神经网络中,卷积计算的形式(如下图)可以被达芬奇的cube式MAC阵列高效支持,而决策树、贝叶斯等其他常见机器学习算法在cube式MAC阵列上运行却不见得有什么优势,因此可以猜测达芬奇的架构设计首要目的是为了支持卷积神经网络推理,而优化卷积神经网络推理就意味着主打机器视觉。
换句话说,达芬奇架构是在通用性上有意识地做了折衷以换取较合理的开发时间和成本。另一方面,做云端训练的时候由于数据往往是批量到来,因此使用cube式MAC阵列也能一次处理一个批次中的不同并行数据,从而也能较好地支持训练。然而,如果从从架构上做比较,cube式的MAC阵列的效率相比Nvidia GPU的SIMD架构未必会有本质上的提升,因此从训练的角度来看达芬奇架构可以说是Nvidia GPU的替代者,但很难说是超越者。
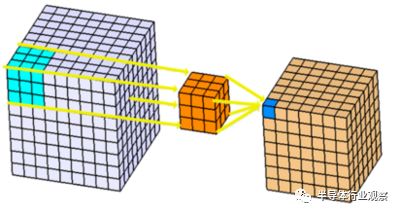
我们不妨将达芬奇架构与目前最热门的两种商用人工智能芯片架构做比较,即Nvidia的GPU和Google的TPU。Nvidia的GPU架构源自经典的GPU多核并行架构,为了优化人工智能计算,加入了对于矩阵运算的优化支持(Tensor Core)。但是GPU并非天生为人工智能而生,因此在卷积神经网络推理等主流应用上,GPU架构的效率并不高,因此华为达芬奇为卷积神经网络优化过的架构相比GPU的计算效率要强不少。与Google的TPU相比,达芬奇架构则显得更加简单直接。
TPU上使用了优美的脉动阵列(systolic array)架构,该架构虽然很久之前就被人们提出,但是迟迟没有找到合适的应用,因此TPU采用脉动阵列从某种意义上可以说是重新发明了脉动阵列,给了脉动阵列以新生。脉动阵列的优势是对于内存带宽的需求大大减少,但是问题在于难以做小,一旦做小了效率就会大大下降——在TPU等级的云端高算力应用脉动阵列是合适的,但是在终端低算力低功耗应用中脉动阵列的效率就不高。因此达芬奇架构相比TPU的脉动阵列来说更灵活,能满足不同算力需求,也即满足了华为AI战略中的横向部分。

最终比拼的还是生态
从之前的分析中,我们的结论是华为的达芬奇架构是一个出色的架构,与Nvidia的GPU和Google的TPU相比性能并不落下风,但是其可伸缩性却远好于GPU和TPU,能快速部署到多个不同算力等级的应用中。为了能充分发挥可伸缩性强的优势,华为的AI芯片必须能尽快进入多个不同的应用领域,因此最终比拼的还是综合生态而非一两个特定应用上的性能对比,正如两军交战最终看的是能否实现战略意图而并不比纠结于一两座城市的得失。那么,在与Google和Nvidia等生态玩家的比拼中,华为有哪些优势和挑战呢?
从公司基因来看,Google是一家技术驱动的互联网公司,Nvidia是芯片硬件公司,而华为则是设备提供商。Google一切业务的源头都是互联网,因此也希望把一切新扩展的业务规划到互联网的范畴中。Google属于第一批看到人工智能潜力的公司,在自己的业务中早早就用上了人工智能,并开发了全球最流行的深度学习框架TensorFlow。
当人工智能得到更多认可后, Google Cloud上开放了深度学习应用接口给用户使用,并且在发现人工智能计算需要新一代芯片后着手研发了TPU。对于Google来说,最关键的生态环节在于人工智能入口即TensorFlow,一旦TensorFlow成为人工智能的绝对主流框架,那么Google就将成为制订下一代人工智能标准化实施方案的主导者,这可以说与当年Google把握了互联网搜索入口如出一辙。另一方面TPU其实只是其生态中并不怎么重要的一环,事实上TPU最早是给Google内部自己使用以节省云计算功耗并加速训练模型用的,Google并没有强烈的让所有用户都用上TPU的决心。
Nvidia则是底层芯片硬件公司,最关注的是GPU是否能卖得足够好,CuDNN和TensroRT可以认为是GPU在人工智能时代的驱动程序,但却不是Nvidia的主要盈利点,而Nvidia更不会尝试去做人工智能时代入口之类的尝试,而是会更倾向于把自己定义为“人工智能计算的赋能者”。
相比Google和Nvidia,华为事实上在一个更中间的位置,因为华为是一个解决方案提供商,最终是为了解决客户的需求,因此其解决方案中既要包含硬件又要包含软件。华为在底层硬件和上层软件接口上都有与Nvidia和Google重合竞争的部分,但是其解决方案提供者的地位则是与Nvidia以及Google都没有任何竞争。
举例来说,如果中国某零售巨头要做智能零售解决方案,需要高速边缘服务器,这样的公司将会是华为的目标客户,却并非Google或Nvidia的目标客户,因为这三家公司中只有华为有意愿给这样的客户提供服务器软硬件以及云端接入的完整解决方案。而此次发布的Ascend芯片则很明显是瞄准了安防、智能零售等新兴机器视觉解决方案市场,在这些市场Nvidia和Google的基因决定了它们都不会涉足。
虽然目前华为和Google以及Nvidia在边缘计算解决方案领域并没有直接竞争,但是随着华为在云端布局加深,与Nvidia和Google将会有正面竞争。如前所述,Google的TensorFlow是手中的一张王牌,凭着TensorFlow的开放性以及社区建设,目前TensorFlow已经能完美支持多种不同的硬件平台,另一方面华为的MindSpore配合CANN则更像是面对自家芯片做的定制化解决方案,性能卓越但是开放性却可能会成为一个挑战。另一方面,在硬件层面,达芬奇如果想彻底战胜Nvidia的GPU或许还需要在芯片架构上更进一步,如果无法对GPU有数量级的性能优势,最终恐怕还是会陷入苦战。
对AI芯片行业的影响
这次华为大举进军AI芯片,是AI芯片领域的一个重要事件。天下之势,分久必合,合久必分,最初的系统厂商如IBM,SUN等的系统都是包含了自研芯片,直到以Intel为代表的标准化处理器芯片崛起以及计算市场利润变薄后这些系统公司才逐渐放弃自研芯片而转而采用Intel的标准化处理器芯片;而AI市场目前看来潜力巨大,不同场景差异化大而且对于芯片效率有很高的需求,这也就为系统厂商重新开始自研芯片提供了足够的动力。 我们认为华为这次自研AI芯片是系统厂商自研芯片趋势的延续。
在华为之前,已经有Google、Facebook、亚马逊、阿里巴巴、百度等诸多互联网系统厂商开始了AI芯片研发,而华为作为中国芯片研发能力最强的系统厂商,进入AI芯片领域可谓是理所当然,因为对于系统厂商来说拥有了自研芯片才能拥有真正的核心竞争力。华为这次进军AI芯片预计将会引发更多系统厂商进入AI芯片领域,估计海康、大华、旷视、商汤、依图等都有自研芯片(或者与其他芯片公司合作研发自己专属的定制化芯片)的商业动力,我们在不久的将来预计会看到更多系统厂商发布自己的芯片,反之缺乏自研芯片能力的系统厂商的生存空间将会受到挤压,要么逐渐消失,要么找到新的商业模式。
另一方面,对于AI芯片初创公司来说,华为的AI芯片目前并没有对外销售的打算,因此华为并非直接竞争对手。此外,由于AI芯片细分市场多,差异化大,华为的AI芯片更有可能发挥鲶鱼效应,激励这些AI芯片初创公司去寻找华为无暇顾及的细分市场,例如功耗小于1W的超低功耗市场等等。
此外,华为的Ascend系列AI芯片也并非不可战胜,其架构如前所述并非属于常人无法想象的黑科技,而更像是一款经过仔细工程优化的AI加速器。因此AI芯片公司如果拥有下一代技术,即使与华为在云端正面竞争也有胜算。
最后,我们必须看到不少AI芯片初创公司实际上也是系统厂商,其AI芯片也是主要供自己的系统使用,如Rokid等。对于这类自研AI芯片的初创系统厂商来说,华为施加的竞争压力会更大,因为华为实际上走了和这些厂商一样的道路,本来这些初创公司系统中的亮点是自研芯片,但是现在相对于同样拥有自研芯片的华为来说这个就不再成为亮点了。对于这些厂商,如何找到属于自己的差异化市场避开华为的锋芒就成了目前亟待解决的问题。
-
芯片
+关注
关注
455文章
50699浏览量
423061 -
机器视觉
+关注
关注
161文章
4366浏览量
120265 -
人工智能
+关注
关注
1791文章
47176浏览量
238163
发布评论请先 登录
相关推荐
AI芯大PK:三星首款AI芯片NPU,性能或超华为苹果

从华为mete10发布,看国产芯片崛起之路
年底入手全球首款AI手机华为Mate 10 Pro还是值得的
中国企业的崛起!全球AI芯片Top24榜单7家中国公司上榜
AI智能芯片火热,全芯片产业链都积极奔着人工智能去
【免费直播】让AI芯片拥有最强大脑—AI芯片的操作系统设计介绍.
【HarmonyOS HiSpark AI Camera】开箱介绍
华为芯片性能第一!华为海思麒麟970超越高通骁龙845
华为在AI芯片大战中有什么优势?
关于AI芯片格局性能介绍和应用





 工商网监
工商网监
评论