 分析FPGA机遇与挑战以及应对措施
分析FPGA机遇与挑战以及应对措施
英特尔在美国总部召开了名为“以数据为中心(Data-Centric)”的创新峰会。在会上,以英特尔执行副总裁、数据中心集团总经理Navin Shenoy为首的各产品线主要负责人介绍了英特尔在大数据时代的发展愿景和布局,对“以数据为中心的计算(Data-Centric Computing)”的潜在市场进行了分析,并且公布了若干英特尔相关软硬件产品的发展路线图。
本次峰会披露了很多关于FPGA的重大动态,其中包括正式宣布了基于英特尔FPGA的智能网卡产品线,以及其第一款代号为“Cascade Glacier(冰川瀑布)”的量产版智能网卡。作为这款产品的FPGA研发团队的主要成员之一,笔者从立项之初就参与了它的各项研发工作,并负责了多个软硬件模块和系统的设计与验证任务。因此对于这款产品的正式对外发布,我倍感欣喜,并希望通过本文进一步梳理和分析峰会的技术细节,以及从以下几个方面探讨FPGA在大数据时代的各种机遇和挑战:
1.英特尔“泛数据中心”业务及其潜在市场
2.基于FPGA的智能网卡产品线的正式发布
3.英特尔人工智能计算加速器产品系列的相关布局
4.FPGA开发的痛点与潜在方案
英特尔“泛数据中心”业务
近年来,英特尔一直积极的寻求业务转型,即从一家以个人计算机和CPU为主的企业,转向以数据为中心并围绕其发展全栈式解决方案的公司。为了实现这一目标,这几年英特尔先后收购了FPGA大厂Altera(167.5亿美金),自动驾驶大厂Mobileye(153亿美金),人工智能芯片初创公司Nervana、机器视觉公司Movidus等众多公司扩展其产品线,并同时招揽了两位芯片设计大神Jim Keller和 Raja Koduri分别担任半导体工程总负责人和芯片总架构师,负责统领英特尔各类芯片(特别是高端数据中心芯片)的整体架构和路线图规划。另外,英特尔旗下的风投部门仅在2017年就投资了包括地平线在内的十余家AI初创企业,各领域总投资额超过五亿美元。
推动这场变革的主要力量,就是目前方兴未艾的大数据浪潮。目前,全世界现有的超过90%的数据都是在过去的两年内产生的。随着人工智能、自动驾驶、5G、云计算等各种技术的不断发展,各类数据将会基于源源不断的产生,预计到2025年时,数据总量将比现在增长10倍。由于上述技术的发展都基于对大数据的研究和分析,因此有人形象的将数据比作未来人工智能时代的石油。
随着数据量的增长和技术的发展,对数据进行处理的能力也有了长足的进步。特别是随着摩尔定律的延续,从2012年至2017年,处理数据所需的计算和存储成本分别下降了56%和77%;同时,处理数据的性能相较2006年则提升了41倍,如图1所示。然而即便如此,现如今只有不到1%的数据被有效的进行了处理、分析和利用。由此可见,如何高效的以数据为中心进行现有系统的优化设计、升级和创新,拥有着巨大的市场潜力和前景。

图1:摩尔定律的延续带来的数据处理性能的增长
在本次峰会上,英特尔对其2022年的大数据相关的潜在市场规模(Total Addressable Market – TAM)做了自己的预测,如下图所示:

图2:2022年英特尔大数据相关的潜在市场规模
英特尔的各类以数据为中心的业务部门主要包括四个子业务群:第一,传统的数据中心业务,包括Xeon处理器、网络、连接等;第二,非易失性存储业务;第三,物联网和自动驾驶业务,包括各类人工智能相关的业务部门;第四,FPGA业务。我在本文中将将其统一称作“泛数据中心”集团。至2022年,泛数据中心集团的潜在市场规模将超过2000亿美元,并由此成为英特尔历史上最大的市场机遇。其中,各个子业务群的市场规模分别为,传统数据中心业务超过900亿美元、非易失性存储业务750亿美元,物联网和自动驾驶业务330亿美元,FPGA相关的业务也超过80亿美元。
为此,英特尔提出了“全栈式”的数据中心系统解决方案路线图,并由此打造以数据为中心的基础架构,如下图所示。

图3:英特尔全栈式数据中心解决方案
可以看到,这个路线图主要由“三驾马车”进行驱动,分别是传输、存储和计算。值得注意的是,图中在传输和计算的部分都明确标出了FPGA的存在。下文将进一步分析FPGA在这两个领域中所面临的主要机遇和挑战。
使用FPGA智能网
卡加速数据中心网络
(1)数据中心网络市场高速增长
在2022年,FPGA的数据中心相关业务的潜在市场规模将达到80亿美元,较现在增长将超过30亿美元。就英特尔FPGA业务部(原Altera)而言,其数据中心相关业务的年同比增长率在今年一季度达到了140%,与高端FPGA器件相关的增幅达50%,而整体业务也有超过两位数的增长,见下图所示。
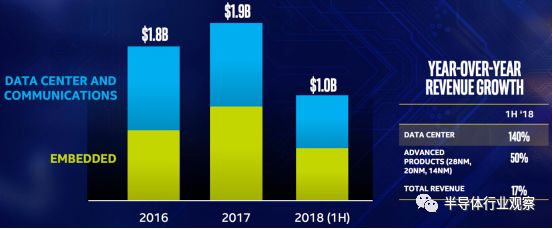
图4:英特尔可编程业务部年增长率
FPGA的一个最主要的应用领域就是对各类网络数据进行并行化处理。这里的网络,既包括传统的有线通信网络,也包括正在兴起的5G无线网络,以及在数据中心里的各类网络连接。
(2)FPGA智能网卡产品线发布
前文中提到,作为本次峰会的一大亮点,英特尔发布了全新的基于FPGA的智能网卡产品线,以及其中的首款量产级产品,代号为“Cascade Glacier(冰川瀑布)”。由此进一步扩充了英特尔的以太网硬件产品线,形成了传统网卡(ASIC)+智能网卡(FPGA)+网络功能加速卡(FPGA)的完整产品组合,如下图所示。

图5:英特尔数据中心以太网硬件产品线
这类智能网卡的产生背景是为了应对数据中心网络流量的爆炸性增长。从下图可以看到,全球数据中心的网络流量将从2016年的6.8Z字节(1ZB等于10的12次方GB)暴增至2021年的20.6Z字节,年复合增长率约为25%。同时值得注意的是,这其中大部分的网络流量都是在数据中心内部的,因此如何优化处理这类网络流量就成了亟需解决的课题。另外,在目前的通信及云服务提供商的数据中心里,部分CPU核心被用来实现必须的存储和网络功能,如针对虚拟化交换的OVS(Open Virtual Switch),以及针对I/O虚拟化的Virtio等等,这样使得宝贵的CPU资源被非用户任务占用,造成可用CPU资源的压缩和紧张。为解决这些问题,Cascade Glacier智能网卡由此产生。
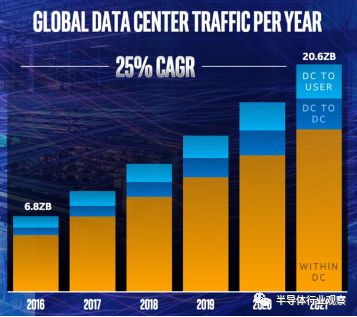
图6:全球数据中心网络流量增长率
如图7所示,Cascade Glacier基于英特尔Arria10系列FPGA,能为云数据中心的网络流量提供2x25GbE的数据处理加速。

图7a:FPGA智能网卡Cascade Glacier
与传统网卡以及现有的其他智能网卡相比,它提供了业界唯一的对Virtio协议的硬件支持和加速,使得云数据中心里的虚拟机可以进行无缝的动态迁移,而不需要安装额外的驱动,极大的扩展了数据中心的部署灵活性。另外,它将原本在CPU上实现的OVS功能完全卸载到FPGA上实现,释放了宝贵的CPU资源。另外,它还提供了FPGA灵活的可编程以及低功耗的特点,方便在数据中心中大规模部署,以及对常用网络功能进行定制化加速。作为英特尔独立开发的量产级智能网卡产品,Cascade Glacier会与英特尔”泛数据中心“架构中的其他组成部分,如Xeon CPU、存储器、AI协处理器和加速器等,进行软硬件深度整合,从而提供完整的端到端的系统解决方案。目前,Cascade Glacier已经进入了最后的批量装配阶段,并预计将于2019年一季度正式出货。
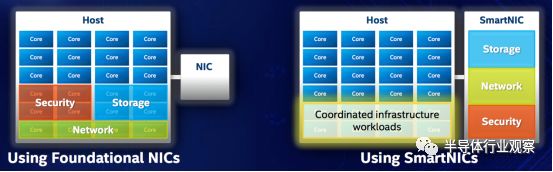
图7b:使用智能网卡进行CPU功能卸载
Cascade Glacier可以算是英特尔针对云数据中心而设计开发的第一代基于FPGA的智能网卡量产产品,很好的解决了行业痛点,因此已经吸引了很多大型云服务提供商的关注。相信在不久的将来,会有更多关于这款产品的详细信息和部署情况被正式公布,届时我会更深入的介绍关于Cascade Glacier的更多性能特点。
(3)针对网络功能虚拟化和加速的FPGA智能网卡
我曾经在之前的博文《白皮书技术解析 - 为下一代电信基础设施寻找有效的虚拟网络体系架构》中详细分析了FPGA是如何应用在网络功能虚拟化(Network Function Virtualization – NFV)这一新兴场景,并帮助中国电信实现电信网络的转型升级的。

图8:网络功能虚拟化与FPGA
通过NFV技术,电信数据中心网络可以实现转发面与控制面解耦分离,从而只需使用标准的服务器、存储和网络硬件设备,并借由FPGA的硬件加速,就能完成各类核心网络功能,而无需再购买配置各类专用的网络设备。NFV是目前电信网络发展的大趋势,并非由英特尔提出。但可以发现,其核心思想与上文提到的英特尔“泛数据中心”的三驾马车不谋而合。英特尔也是目前唯一一家可以提供结合了传输、存储和计算的全栈式半导体解决方案的公司。
在2017年的甲骨文开发者大会上,英特尔公布了一款正在开发中的智能网卡原型机,如下图所示,并对使用这款智能网卡进行网络数据加解密的性能进行了现场展示。这款智能网卡基于英特尔Arria10系列FPGA,并包含一枚英特尔XL710以太网控制器,因此可以同时实现高速网络数据处理以及灵活的基于FPGA的定制计算需求。作为这款板卡最早期的FPGA开发者之一,我认为这款产品及其后续的升级版本将会在数据中心的网络功能加速领域有着广阔的前景。

图9:针对NFV与网络功能加速的FPGA智能网卡
人工智能计算加速器
产品系列的相关布局
在本次峰会上,英特尔宣布了Xeon处理器的详细路线图,即基于英特尔14nm工艺的Cascade Lake(2018年底出货),基于14nm工艺的Cooper Lake(2019年出货),以及基于10nm工艺的Ice Lake(2020年出货)。这三款Xeon处理器都在内部集成了对深度学习加速器的原生支持,从而更好的针对人工智能应用进行计算和加速。除此之外,英特尔还展示了“泛数据中心”业务群中针对人工智能应用的全栈芯片产品组合。
图10:英特尔人工智能芯片产品组合
在人工智能的计算和加速领域,FPGA也被广泛用作硬件加速模块来使用,并被部署于数据中心本身以及很多边缘计算的场合。
首先,在数据中心领域,最有名的例子就是微软在其数据中心对FPGA使用进行的一系列针对人工智能计算的开创性的探索。例如,微软在它最新公布的“脑波项目(Project Brainwave)”中,使用了英特尔FPGA,构建了实时深度学习平台。它利用了FPGA的低延时、高并行、低功耗的特点,实现了对Bing搜索服务、微软Azure云平台等多项业务的跨越式加速。关于微软的FPGA项目已有很多文章进行介绍,本文不再展开。
其次,英特尔于2017年发布了用于Xeon服务器的新一代标准化的“可编程加速卡(Programmable Acceleration Cards – PACs)”,以及配套的加速栈开发软件和用户接口,如下图所示,并已经得到了包括戴尔、富士通、浪潮等服务器大厂的采用和配套支持。这款加速卡可以使用户在多个领域进行定制计算加速,包括人工智能、大数据、高性能计算等。

图11:英特尔基于FPGA的可编程加速卡
第三,FPGA的应用也逐步扩展到网络边缘和端点,例如智能安防、视频采集和处理、自动驾驶和机器人等等,直接在数据来源进行计算加速,并进行人工智能模型的推断和处理。
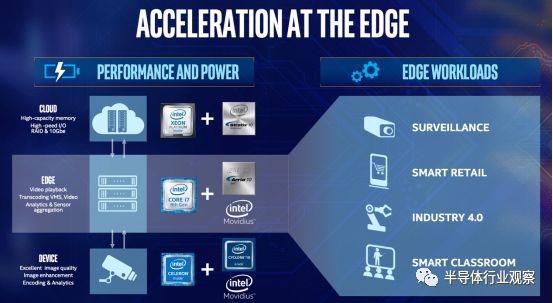
图12:FPGA在边缘网络计算中的应用场景
边缘计算+人工智能通常是国内外初创企业切入市场的主要领域。这一方面是由于数据中心市场太过庞大,因此被巨头牢牢把持难以进入,另一方面也是由于在这个领域更容易通过创新的算法和方案获得一席之地。我国的两个主要代表企业就是地平线和深鉴科技。其中,前者已获得英特尔领投的A+轮近一亿美元投资,并通过此次投资将FPGA 事业部负责人Dan McNamara安排加入了地平线的董事会;而后者已在A+轮融资后被另一个FPGA大厂Xilinx全资收购。由此,可以十分清晰的看到FPGA公司对边缘计算和人工智能领域的积极布局。
FPGA开发的
痛点与潜在方案
至此可以看到,英特尔已经在泛数据中心领域开展了全面的布局和规划。其中,FPGA在驱动大数据传输和计算这两个关键领域均扮演着重要角色,并且覆盖了从云端到网络边缘的各个部分。然而,尽管FPGA被某些国内媒体热捧为“万能芯片”,真正的实现对FPGA的广泛使用还是存在很多难点亟待克服。
第一,学界和业界仍然没有开创性的方法简化FPGA的开发,这可以说是现阶段制约FPGA广泛使用的最大障碍。和CPU或GPU成熟的编程模型和丰富的工具链相比,高性能的FPGA设计仍然大部分依靠硬件工程师编写RTL模型实现。RTL语言的抽象度很低,往往是对硬件电路进行直接描述,这样一方面需要工程师拥有很高的硬件专业知识,另一方面在开发复杂的算法时会有更久的迭代周期。因此,FPGA标榜的可编程能力与其复杂的编程模型之间,形成了鲜明的矛盾。
近五到十年来,高层次综合(High Level Synthesis - HLS)一直是FPGA学术界研究的热点,其重点就是希望设计更加高层次的编程模型和工具,利用现有的编程语言比如C、C++等,对FPGA进行设计开发。在这期间有趣的成果层出不穷,其中有代表性的HLS初创公司有多伦多大学Jason Anderson教授及其学生创办的LegUp Computing,以及UCLA丛京生教授创办的Falcon Computing等。
在工业界,两大FPGA公司都选择支持基于OpenCL的FPGA高层次开发,并分别发布了自己的API和SDK等开发工具。这在一定程度上降低了FPGA的开发难度,使得C语言程序员可以尝试在FPGA平台上进行算法开发,特别是针对人工智能的相关应用。尽管如此,程序员仍然需要懂得基本的FPGA体系结构和设计约束,这样才能写出更加高效的OpenCL模型。另外,基于OpenCL的FPGA设计移植性不是很好,且严重基于厂商提供的开发工具和底层模块的性能,调试起来也不甚便利。
在数据中心网络应用领域,两大FPGA公司也开始支持名为P4的网络编程语言。P4语言大约于2014年由斯坦福大学的Nick McKeown教授提出,主要用来描述网络交换、路由选择和数据包处理规则,非常适合数据中心里高速网络通信的应用场景。关于P4的具体内容在本文中不再展开,其内容值得再写一篇文章详细探讨。其实相比全通用的HLS设计而言,类似于P4的针对某类特定应用的HLS工具或许有更大和更快的发展前景。
类似的还有英特尔最新发布的OpenVINO(Open Visual Inference & Neural Network Optimization - 开放的视觉推理和神经网络优化)开发套件。顾名思义,OpenVINO专为计算机视觉和深度学习在边缘计算的应用场景进行优化,其最大特点是支持英特尔的全栈视觉加速方案,包括CPU、GPU、FPGA以及Movidius VPU等,并支持多种深度学习框架。其中,在FPGA上使用OpenVINO进行开发,可以取得高达19倍的性能提升,如下图所示。
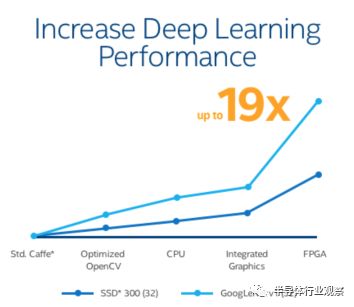
图13:使用OpenVINO实现深度学习的性能提升
第二,FPGA并非适用于各种应用场景。特别是对于一些边缘计算和嵌入式应用,它们对价格、功耗、性能以及可靠性的统筹要求很高,其中往往价格会是主要的考虑因素。这样基于FPGA的方案相比于GPU、SoC或者ASIC的方案并没有很大的优势,这是由于FPGA并非针对某一特殊应用场景而设计优化。
为了解决这个问题,英特尔近日收购了“结构化ASIC”设计公司eASIC,并计划将其整合到公司的FPGA事业部中。结构化ASIC设计可以看成是FPGA与ASIC的折中,如下图所示。它通过牺牲FPGA的可编程性换取低功耗、低成本和高性能,同时通过牺牲ASIC的优化设计和布局换取更快的设计流片时间。因此对于很多对成本和功耗敏感的应用场景,这种结构化ASIC的设计方法有着很强的竞争力。
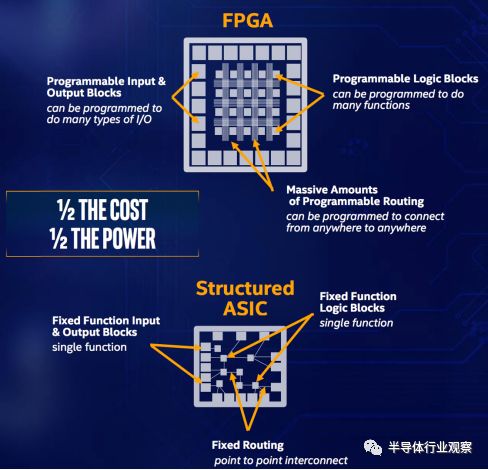
图14:FPGA与结构化ASIC设计比较
结语
本文总结了在英特尔“以数据为中心(Data-Centric)”的创新峰会上发布的和FPGA相关的主要技术内容,并由此延伸探讨了FPGA在人工智能和大数据时代的机遇和挑战。可以说,如今FPGA在泛数据中心应用领域再次焕发新生,各种全新机遇接踵而至。同时我们看到,机遇往往伴随着挑战,只有勇于应对挑战,才能在新的时代不断前进。
-
FPGA
+关注
关注
1629文章
21736浏览量
603326 -
人工智能
+关注
关注
1791文章
47274浏览量
238468 -
大数据
+关注
关注
64文章
8889浏览量
137438
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论