 关于Kirin 970的NPU的性能分析
关于Kirin 970的NPU的性能分析
去年,华为推出了业界首款集成NPU的移动芯片Kirin 970。作为新一代的旗舰,这个SoC上面的CPU集成了8个核心,其中 4 个为高性能的 ARM 公版 A73 架构,最高主频 2.4GHz(麒麟 960 是 2.36GHz),4 个为低功耗的 ARM 公版 A53 架构,最高主频 1.8GHz(麒麟 960 是 1.84GHz);GPU则是集成了ARM最新的Mali-G72 架构。
另外,除了传统移动手机SoC必备的通信基带、ISP、DSP、Codec和协处理器外,Kirin 970还首次集成了专门为深度学习而定制的NPU,FP16 性能达到了 1.92 TFLOP。具体来看, NPU 是 CPU 的 25 倍,GPU 的 6.25 倍(25/4),能效比上,NPU 更是达到了 CPU 的 50 倍,GPU 的 6.25 倍(50/8)。这是华为面向现在火热的人工智能市场扔出的一个杀手锏。
以上都是华为的一家之言,下面我们就来探讨一下华为这颗芯片NPU的真正实力。首先,我们先来了解一下NPU的概念。
什么是NPU?
准确来说,当我们谈到人工智能在计算领域的用途的时候,更多强调的是机器学习。
而当我们讨论人工智能在硬件层面的深入研究的时候,谈论的则更多是针对专门的硬件模块所进行的卷积神经网络的优化和执行工作。
在解释卷积神经网络如何工作的时候,我们从上世纪八十年代开始的工作已经远远超出了研究工作,其根本目的是试图模拟人脑神经元的行为。
注意,这里的一个关键词是“模拟”,虽然到目前为止并没有任何神经网络能够从硬件层面模仿人脑的结构。
不过在学术领域,尤其是在神经网络领域已经存在了很多理论。在过去的十年中,已经开发出了一套软件能够在GPU的硬件层面模拟整个过程。
比如说,研究人员通过不断的迭代和发展美国有线电视新闻网的模型,极大的提升了新闻的准确性和效率。
当然,GPU并不是最适合运行人工智能的硬件,也不是唯一一个能够进行高度的并行运算的处理器。
随着人工智能的不断发展,越来越多的公司希望在实际应用当中将人工智能实现商业化,这就要求硬件能够提供更高的性能,更高的效率。
因此,我们也看到了更加专业的处理器的出现,其架构就是针对机器学习等应用。
谷歌是第一家宣布推出此类硬件的公司,该公司在2016年推出了TPU。但是,虽然这类专业的硬件能够在处理人工智能等工作方面在硬件和功率方面获得更高的效率,但是也失去了灵活性。
谷歌TPU芯片和主板
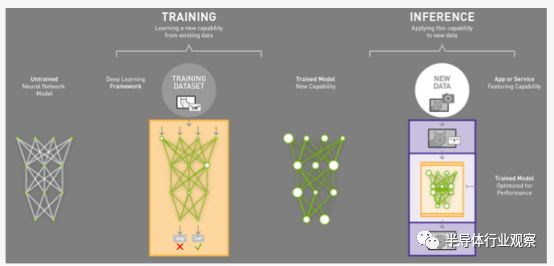
在这类专门的人工智能处理器当中,影响其工作效率的主要有两个方面:要存在一个经过训练的模型,其中主要包括模型在今后的运行中可能涉及到的相关的数据。一般情况下,模型的训练是大密度的,需要经过大批量的训练才能实现更高的精度。也就是说,在实际运行中,有效的神经网络要比实际用到的神经网络要庞大的多。
因此,普遍存在这样一个思路,就是模型的主体训练工作由更加庞大的GPU服务器或者是TPU云服务器来完成。
其次,神经网络的运行需要一个执行模型,通过不断注入新的数据,完成模型的演算来实现整个过程。一般情况下,我们将输入数据,然后通过神经网络模型得到输出结果的模式称之为推理。
不过实际的推理过程与模型当中的训练过程对于计算的要求也存在着很大的不同。
虽然推理和训练都需要用到高密度的并行计算,但是推理能够以较低精度的计算来完成,同时执行模型部分所需要的计算性能也较低,这也就意味着推理过程能够在更加便宜的硬件上来进行。
这一功能反过来引导整个行业走向更加注重边缘设备(用户设备)的方向,因为这些设备能够提供更高的性能效率和需求更低的功耗。
也就是说,如果本地设备当中存在一个已经经过训练的模型,就可以使用该设备来进行推理过程,而不需要将数据上传到云端服务器当中来进行数据的处理。
这一过程将会减轻可能存在的延迟,功耗和带宽等问题,同时也避免了隐私问题,因为输出端数据永远不会离开用户设备。
随着神经网络推理功能在终端设备上运行的不断实现,对于不同处理器能够实现何种功能的研究以及选择工作也在不断深入。
CPU、GPU甚至DSP都能够在终端设备上实现推理功能,但是这些处理器之间存在着巨大的效率差距。通用处理器适合绝大多数的工作,但是他们天生就不是被设计用来进行大规模的并行计算的。GPU和DSP甚至表现的更好,也有巨大的提升空间。
但是,此外,我们也见到了一种新的处理加速器的出现,比如麒麟970里面使用的NPU。
由于这类处理加速器是新近出现的设备,所以到目前为止,业界并没有更出一个统一的命名方式。华为海思命名的是一种方式,而苹果则是以另外一个名字命名。
不过从普世意义上来看,我们能够将这些处理器统一称之为神经网络IP。
为麒麟970 NPU提供IP的是一家名为寒武纪的中国IP供应商,据了解,NPU采用的IP是经过优化之后的产物,而不是直接采用现有IP。同时,华为还要求Cambricon能够与之共同发展改进该IP,因为在实际的应用当中,实际情况与计算情况,有时候还是会存在着一些差距。
但是,我们需要明白的是,我们应当避免对神经网络的理论性能数据过多关注,因为这些数据并不一定与实际性能有关,同时由于对神经网络IP了解有限,最终结果如何也未可知。
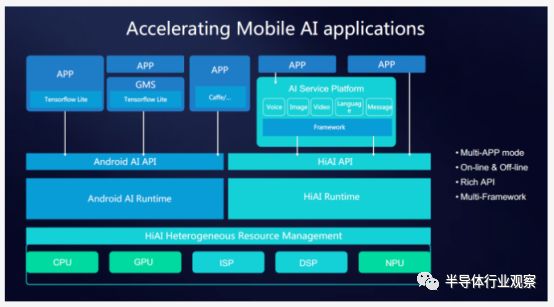
当使用CPU以外的其他硬件设备来运行神经网络的时候,第一个障碍就是利用适当的API来访问模块。
传统的SOC和IP供应商已经能够提供专用的API和SDK来进行使用该类硬件的神经网络的应用开发。而海思提供的API不仅仅能够管理CPU,也能够用来管理GPU和NPU。虽然目前海思还没有对外公开该API,但是据了解,海思将会在今年晚些时候与开发商一起进行开发。
其他的厂商,诸如高通也提供了SDK来帮助程序开发人员在GPU和DSP等硬件的基础上进行神经网络的开发工作,当然还有其他一些IP供应商也有提供自己专门的软件开发工具来进行相关的开发。
但是,针对特定供应商的API同样存在着局限性,未来我们需要不同的供应商能够提供统一的API来进行更加快速,便捷的开发工作。
谷歌目前正在开展这项工作,该公司计划在安卓系统8.1当中引入相关的名为NN API的模块。
另外一个需要注意的问题是,目前很多的类似于NN API的只能够支持一部分功能,比如只能够支持NPU的一部分功能,如果开发人员想要在NPU的基础上,充分开发和利用硬件的性能,开发者就需要有专门的API来开发这类硬件。
Kirin 970的NPU性能测试
为了完成这类开发工作,我们还需要一个基准测试,来测试不同的供应商提供的API能够利用到NPU多少性能。
不幸的是,在现阶段,我们还缺少类似的实现该基准测试的方法,目前只有中国的一个厂商推出了相关的软件:在中国比较流行的鲁大师基准测试软件在最近推出了一个基于人工智能测试的框架,用来测试NPU和高通SNPE框架。
据了解,目前该基准测试能够测试三种不同的神经网络,VGG16, InceptionV3和ResNet34。
这类软件不仅能够测试相关的处理器的性能,并给出相关的结果。同时也能够以图形化的方式,从平均功率,效率以及绝对性能等三个维度展示处理器的处理能力。
从这类软件呈现的图形数据我们能够观察到处理器的性能差异,CPU和NPU在进行相关运算时到底有多大的差距。
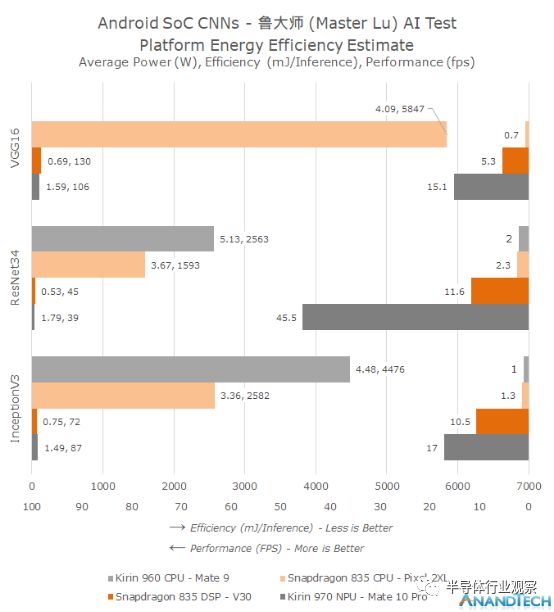
当使用CPU来进行运算的时候,通常情况下CPU只能以1-2fps的速率进行计算,而所需要的功耗也异常的高。比如骁龙835和麒麟960的CPU在运算的时候,都需要以超过平均负载的工作负载进行运算。
相比较而言,高通的Hexagon DSP能够实现相对于CPU5到8倍的性能。
而华为的NPU的性能则更加明显,相对于ResNet34,NPU能够实现4倍的性能提升。
不难发现,不同的处理器之所以在性能方面表现出如此巨大的差异,是因为这些处理器的设计不同,所针对的处理器应用场景也不同。
由于卷积神经网络在运算的过程中需要进行大量的并行计算,因此,像麒麟NPU这样的专门的处理器在执行的过程中往往能够实现更高的性能。
而在功耗方面,我们则发现,相对于其他的处理器,NPU能够实现50倍的改进,尤其是在卷积神经网络实际的运用当中,这种能耗的提升更加明显。
同时,我们也发现,高通的DSP也能够实现类似于华为NPU同等级的功耗水平。这似乎表明,高通推出的骁龙845处理器中应用的Hexagon 685能够在性能方面提升3倍。
在此,我想抱怨一下谷歌的Pixel 2:由于Pixel 2缺乏对于SNPE框架的支持,因此很难从真正意义上进行骁龙835的CPU基准测试。
不过从某种意义上来说,这也是理所当然的事情,毕竟谷歌在安卓8.1中才会引入NN API,未来谷歌将会推动安卓标准API在相关处理器方面的加速也是自然而然的。
但是,从另一方面来说,这也会限制传统的手机OEM厂商开发的能力。
这一决定往往会限制今后生态系统的发展,这也是为什么我们没有看到更多的手机GPU来进行相关的卷积神经网络加速工作。
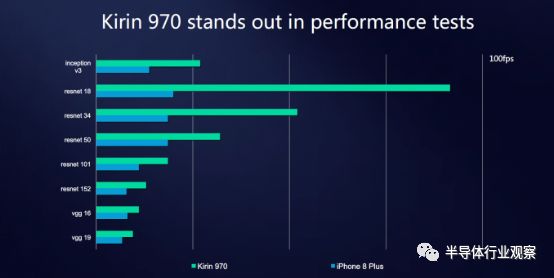
此外,虽然目前iPhone并不支持相关的基准测试,但是我们也能够从海思发布的相关数据中看到一些端倪。
从一些数字上我们能够看到,苹果所提供的神经网络IP虽然在性能方面超越了骁龙835处理器,但是仍然远远落后于海思的NPU。但是,我们无法单独核实这些数字是否真的适合相关的基准。
当然,最重要的问题在于,这类处理器能够带来什么好处?
海思表示,一个比较明显的例子是,美国有线电视新闻网通过应用处理器来进行降噪处理,能够在交通繁忙的情况下,将语音识别的准确度从80%提高到92%。
此外,还有在摄像头应用方面,Mate 10的摄像头能够在NPU的帮助下,通过推理,来识别不同场景,再基于场景对相机的设置进行智能的优化。
同时,Mate 10中所应用的微软翻译程序也能够使用NPU的离线加速翻译功能,这些都是令我印象深刻的应用。
而在手机内置的图片应用中,也能够智能识别图片来进行分类。
除了NPU能够对卷积神经网络进行相应的视觉处理之外,Cadence 的Tensilica Vision P6 DSP 和高通的Hexagon 680 DSP也能够实现相同的功能,只是目前并没有对终端用户开放而已。
但是,这并不表明,采用NPU的Mate 10就能够为终端用户带来决定性的差异化体验。同样,手机中这类神经网络的应用并没有在汽车,安全摄像头领域出现相同的杀手级应用。另外,由于生态系统的限制性问题,我们只能够在Mate 10见到相关的应用,我们能否在更多的场景中见到,华为是否愿意开发,与开发商一起共同开发,都是值得商榷的事情,不过华为在这方面的创新还是值得肯定的。
正如之前所说,华为和微软共同开发的应用似乎是Mate 10上最吸引人的应用,因此我们可以在此基础之上进行更多的探索。
目前来看,该应用能够智能识别传统的外文文本,并进行翻译,那么在未来是否可以AR方面的应用呢?
联发科在CES上为我们展示了一个相关的识别的例子:使用神经网络的视频会议编码器能够对美国有线电视新闻网的图像和视频进行识别,并反馈给编码器,从而提升视频的质量。
在未来,可以想见,越来越多的设备将会采用这类IP,开发人员也能够更容易的开发相关应用。
最后的思考
我在这篇文章里,并不是想强调麒麟970到底有多么的先进,只是希望借此机会表明,未来高端安卓智能手机处理器的竞争和发展格局将会出现很多令人振奋的变化。
随着iPhone智能手机生态系统进入10周年,我们也看到越来越多的垂直整合设备的出现。
并不是说苹果就一定是规则的制定者,只是在未来,一个更加成熟的生态系统当中,公司都需要能够自主的把控发展路线。否则,手机厂商将很难与其他厂商区分开来,更不用说为用户提供差异化的功能,或者与其他厂商竞争。
苹果很早就意识到了这一点。而华为也是目前为止唯一一家能够独自设立目前的OEM厂商。
同时,还有很多准独立厂商也在努力设计自己的芯片,他们凭借从IP供应商那里获得的CPU和GPU等关键零部件来进行设计。
根本上来说,麒麟970在CPU的性能与功率上面并没有与骁龙835有太大的差距,其误差只是体现在cortex-a73在实际应用中的体现而已。
考虑到骁龙820所采用的CPU虽然与三星自主开发的CPU略有差距,但是在实际应用中并不明显,而且三星到目前未知也没有计划去全力发展和整合自主CPU,考虑到这些,华为采用ARM CPU还是很有道理的。
而高通本身在自主设计CPU和GPU方面都具有一定的自主掌控能力,并与其它厂商有着很大的差距。
想象一下,在桌面GPU上领先的英伟达,与竞争对手相比,拥有33%的效率竞争优势,当这一优势扩大到75-90%的时候,这种选择就不言而喻了。
这种情况之下,厂商可以通过使用更大的GPU来补偿效率和性能方面的缺陷,而这些体验,终端用户几乎很难感觉到。
但是,这是一种不可持续的方案,因为这种方式正在不断蚕食厂商的毛利率。
除了CPU和GPU以及调制解调器IP之外,手机还需要更多的组件,这里就不深入探讨。
比如说,在麒麟970中使用的 Cadence Tensilica Vision P6 DSP确实能够提升相机的性能,但是也需要从软件方面来进行支持才可以。
NPU是一种尚处于起步阶段的新兴IP,麒麟970有很多竞争对手吗?并没有。这一功能为产品增加了竞争力吗?确实有,但可能没有想象中那么大。
软件生态系统的发展确实会拖慢手机产业的发展,但是没有相关硬件的支持,很多应用只有软件也是没有办法实现的。
华为的这一策略将来在全行业采用将是不可避免的。
海思的NPU芯片证明海思作为一家芯片设计公司也能够设计出与高通,三星匹敌的处理器。但是,海思的发布时间并不遵循传统安卓手机厂商的发布规律,因此我们预计会有新的处理出现,在性能方面超过麒麟970。
现实是,华为是能够将芯片设计和终端产品整合在一起的唯一两家OEM供应商之一(编者按:其实三星也算一家,但是三星似乎采用高通的方案更多),也是唯一一家安卓厂商。在过去的几年里,这家厂商已经走过了漫长的道路,经历了太多的改进。最重要的是,华为始终能够把目标和执行目标放在一起,坚定不移的朝着移动业务这一正确方向发展,这是他们成功的关键原因。
但对这家中国厂商来说,未来的路还是很长。
-
处理器
+关注
关注
68文章
19388浏览量
230569 -
神经网络
+关注
关注
42文章
4777浏览量
100974 -
云服务器
+关注
关注
0文章
706浏览量
13389
发布评论请先 登录
相关推荐
NPU支持的编程语言有哪些
NPU的工作原理解析
如何选择合适的NPU型号
NPU的市场前景与发展趋势
NPU在边缘计算中的优势
NPU技术如何提升AI性能
什么是NPU芯片及其功能
NPU与GPU的性能对比
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
什么是NPU?什么场景需要配置NPU?
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
基于RK3588的NPU案例分享!6T是真的强!
芯品# 物联网市场性能最高的 NPU





 工商网监
工商网监
评论