 关于晶圆与芯片之间的联系与异同
关于晶圆与芯片之间的联系与异同
芯片代工厂商正在将新节点工艺和现有节点的不同工艺大量投入到市场,给芯片制造商带来了困扰和一系列的挑战。
目前已有10nm和7nm的全节点工艺,正在研发5nm和3nm工艺。同时引入了越来越多的半节点或“node-let”技术,包括12nm,11nm,8nm,6nm和4nm。
Node-let在全节点工艺的基础上发展而来。例如,12nm和11nm比16nm/14nm的版本稍先进,8nm和6nm与7nm属于相同类别。
节点名称不再像过去一样直接反映晶体管的实际尺寸。一些芯片制造商通过大肆吹捧节点名称来显示其在「工艺竞赛」中的领导地位。而实际上,其中的数字是随意定义的,许多业内人士仅把它们当作营销术语。
节点的数字很容易理解。对于代工厂客户来说,挑战在于决定使用哪个工艺进行设计以及是否可以提供价值。随着IC设计成本的增加,客户不再能负担得起每个节点开发一个新的芯片。西门子(Siemens)旗下Mentor的总裁兼首席执行官Wally Rhinesyu 说,“所以你必须比较和选择,了解自己的需求和代工厂的能力。”
对于代工厂来说,挑战在于拓展所有这些新工艺,新的10nm和7nm工艺预计将在2018年进行大批量生产,新工艺是当前16nm / 14nm finFET晶体管的缩小版,并且更加复杂。finFET中,电流的控制是通过将栅极加到鳍的三个面上实现的。
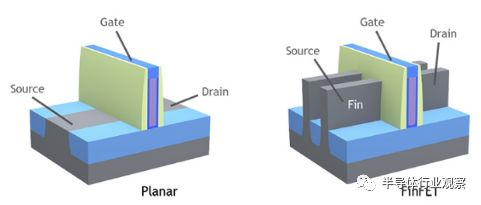
图1:FinFET与平面晶体管 来源:Lam Research
第一代10nm / 7nm工艺将采用光刻和多图案成形设计(multiple patterning),引入了更多的掩膜层和更小的特征尺寸。缺陷更难被发现。10nm/7nm的工艺中不同制造设备的差异也变得更难处理。
显然,这个行业面临一些挑战,“7nm晶圆代工产品的使用可能令人失望,”Gartner的分析师Samuel Wang说,“我之所以这样认为,是因为设计者首个7nm芯片的硅成品率远远低于以前的节点。设计成本高,设计复杂,与合作者深入合作需求高,这些都使一次性设计成功7nm的SOC变得遥不可及。”
一段时间后,芯片制造商发现有可能会解决这个问题。之后,为了简化这个过程,供应商希望在7nm和/或5nm工艺的第二阶段加入极紫外(EUV)光刻。但是,EUV也存在一些挑战。
FinFET预计将缩小至5nm。 除此之外,芯片制造商正在研究各种下一代晶体管类型。 客户也正在评估其他选项,如高级包装。
总的来看,全节点工艺周期从传统的2年增加至2.5到3年。尽管如此,在全节点和半节点技术基础上,业界面临着以更快速度提供更多更复杂技术的压力。应用材料(Applied Materials)半导体产品集团高级副总裁Prabu Raja说,“这个行业正在快速地发展,客户每年都在推动我们在各个方面做出新的改变。”
什么是节点?
芯片由晶体管和内部互连组成,我们把晶体管看作开关。通过铜布线实现晶体管顶部的互连,这些布线使电信号实现在晶体管间的传递。
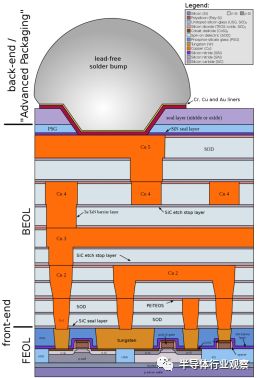
图2:具有前端和后端的芯片。 来源:维基百科
芯片有10到15层铜互连。通常,第二金属层M2的间距最窄。 TechInsights的分析师Andy Wei表示,“以前,技术节点名称根据最窄节距定义,通常是最合适的布线间距(在M2)。”
随着每个节点推进,晶体管规格缩小了0.7倍。采用光刻技术缩小晶体管尺寸,晶体管缩小的同时,性能提升15%,成本下降35%,面积增加50%,功耗降低40%。这个定理普遍适用于90nm, 65nm, 45nm等数字定义的不同工艺。
但是,28nm以后定理开始失效。英特尔仍遵循0.7倍的缩放规律,但在16nm/14nm,其他规律不再遵循以上定理,不再与金属层间距那么相关。 “之前节点的名字有一定的含义,通常与金属节距有关,”魏说,“在某些方面,我们不再考虑节距,而是把关注点更多地放在下一个节点及其特征上。”
因此,节点名称和规格不再与M2间距一致,而且不同厂商的也不一样。总而言之,如今的节点名称“更像是一个市场化的数字”,他说,“当然,每一个节点都是上一个节点的改进。”
更重要的是,28nm以后晶体管的尺寸缩小更加困难。光刻可以解决一些尺寸缩小的方法,但不适用于所有的尺寸。
因此,单个晶体管的成本——按比例缩小的关键指标——不再遵循陡峭地线性下降的规律。“如果我们除金属间距外加入其它的考虑,这将更加不符合线性下降的规律。如果我们根据金属间距除以一个实际因子来定义节点名称,曲线将变得平缓,但实际上并不符合我们所期望的缩放比例。”他说。
而且,随着设计成本的不断增加,更少的代工厂客户可以承担得起先进节点工艺的费用,16nm/14nm芯片的平均集成电路设计成本为8000万美元,而28nm平面器件的平均集成电路设计成本仅为3000万美元。根据Gartner的说法,设计一个7nm的芯片要花费 2.71亿美元。
工艺节点为16nm / 14nm的finFET对很多客户来说非常昂贵。 “如果客户不需要finFET的性能,那根本不用考虑16nm/14nm的finFET,因为它太贵了。”联华电子(UMC)美国销售的副总裁Walter Ng表示,“据我们了解,目前仍有大量的客户关注28nm,只有特别少的客户在关注finFETs。
有很多应用不需要前沿的工艺节点。“你看汽车电子或物联网,很多客户无法承担前沿工艺的费用,因此,很多汽车电子也不会用到最先进的工艺节点,”Ng说。
也有可以承担起先进节点工艺设计费用的代工厂客户,因为他们需要将最先进的工艺应用于像智能手机这样的传统的应用程序。
人工智能,机器学习和电子货币是推动工艺节点发展的几个最新应用。 “深度学习应用正在席卷全球,其中的训练需要巨大的计算能力,通常由GPU和专用处理器加速。”D2S首席执行官Aki Fujimura表示,“仅此就会增加全球对高性能计算的需求。所以毫无疑问,发展7nm及以下的工艺很有必要。尤其是适用于仿真,图像处理和深度学习的GPU。要实现所有的这些事情,我们必须有足够的计算能力。
出于以上考虑,半导体行业不能停止,甚至不能放慢脚步,这也是为什么芯片制造商一直在寻求使芯片尺寸缩小的新方法。许多方法属于过度缩放(over-scaling)的范畴。英特尔称之为“超微缩技术(hyper-scaling)”。
例如,从22nm / 20nm开始,芯片制造商开始使用193nm浸入式光刻以及各种多图案成形技术。为了减小40nm多的间距,多图案成形在制造中进行了多次光刻,蚀刻和沉积。
同时,原来的平面结构也发展成了三维结构。finFET就是一个最好的例子。然后出现了全栅覆盖结构(gate-over-contact)和其他结构。这反过来改变了材料的混合集成。 “当考虑到垂直结构时,又会出现许多新材料。 那如何对这些材料进行沉积和刻蚀?关于材料的选择方式就出现了巨大的变化,”Applied的Raja说。
再举一个例子,供应商使用的设计协同优化技术。其中的想法是在每个节点,在一个标准单元布局中减小单元高度和单元大小。
标准单元是设计中预定义的逻辑元件。这些单元被放置在一个网格中,track用来是标准单元高度的计量单位。例如,根据微电子研究中心(Imec)的说法,10nm可能有7.5轨道高度(7.5-track height),64nm的栅极间距,48nm的金属间距。
在7nm情况下,高度大概为7 至 6 tracks,据微电子研究中心分析,栅极和金属间距分别为56nm和36nm。
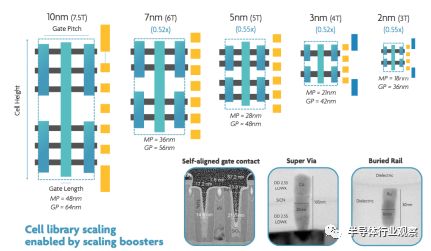
图3缩放单元使单元库缩小 来源:Imec
这反过来又使缩放提升了0.52倍。“尺寸缩放与标准单元高度缩放并行。” Imec半导体技术和系统的执行副总裁An Steegen说,“这种方式使节点到节点减小了50%的面积。”
14nm开始,英特尔通过引入双高度轨道技术(double-height track)——将两组轨道相结合——进一步推进了这一技术。 “(英特尔)把原来的宽单元折叠起来,”TechInsights的Wei说,“表面上看,它好像使用了更多的区域。它比较窄,但高度变为原来的两倍,折叠起来面积更小。当你折叠单元时,可以使用更小的线路,而且整体的电阻更小,性能更好。”
这种技术是否可以使缩放再次符合传统单个晶体管曲线仍存在争议,但是此技术和其他技术成为了这个等式中不可缺少的一部分。 “你需要这些技术,因为你正在使新节点技术更加复杂。”格罗方德(Global Foundries)的首席技术官Gary Patton表示,“你需要超微缩技术来满足缩放2倍多的要求。”
那么,节点和node-let(有时称为inter-nodes)的定义是什么?“至少从英特尔的角度来看,全节点与之前的节点相比需要接近2倍的晶体管密度的提高,” 英特尔高级研究员、流程架构与集成总监Mark解释说,“全节点也是我们通常引入技术改进的地方,例如高k /金属栅极和finFET。半节点就是在全节点上进一步优化的地方。”
如何选择成了一个问题
无论如何,代工厂客户都不知道如何去选择。下面的图表中列出了一些选项。
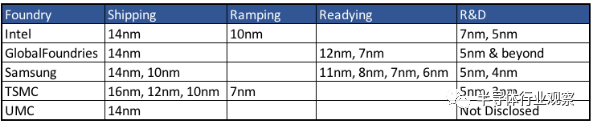
图1:代工厂计划和现状 来源:分析员,代工厂报告/半导体工程
节点解密的一种方法是将英特尔的战略与其他战略分开。英特尔引入了一个全节点的流程,在此基础上开发增强功能。Bohr说:“英特尔经常每三年有一个大动作,然后在此基础上反复的进行小修改。”
其他芯片制造商的全节点和半节点工艺从名字上来看似乎是领先于英特尔的, “其中有些是为了竞争,” Bohr说,“英特尔工艺竞赛中仍处于领先地位。”
然而,代工厂正在为客户提供各种选择。假如16nm / 14nm是一个起点。 “有些将保持在14nm,之后直接跳到7nm,”Global Foundries的Patton说,“而有些正在寻找14nm的扩展。”
例如,12nm是16nm / 14nm的延伸。它的性能比16nm / 14nm稍好。
前沿,代工厂正在研发10nm / 7nm。英特尔的14nm工艺大致相当于其他代工厂的10nm。英特尔的10nm相当于Global Foundries和台积电的7nm,三星的8nm。
Patton解释说:“在我所说的“7nm”中有四种技术。“我们可以讨论其中哪一个技术最高,哪个性价比最好,但是他们都在PPAC中拥有相同的编码。”
Patton指的是客户关注的关键指标——功耗、性能、面积和成本。那么哪个节点提供最好的PPAC?类似于以前,它在很大程度上取决于设计和应用。 Semico Research的制造总经理Joanne Itow表示,“代工厂的客户很精明,知道他们决定与谁合作、使用哪些流程最终取决于技术的性能、经济性以及代工厂与客户之间的融洽程度。”
一位匿名的代工厂客户概述了一个可能的策略。一般来说,一家公司的旗舰芯片产品是针对16nm / 14nm和7nm等全节点工艺的。
那么,一家公司可能会有一些附加产品或新的芯片预定为16nm/14nm。对于这些来说,公司将会考虑像12nm / 11nm这样的半节点工艺。根据代工厂的说法,“代工厂不只是缩放所有的层,而是用12nm / 11nm的半节点工艺来缩放选定层。所以,我们可以在不增加掩膜层,不增加成本和复杂性的条件下从14nm发展到11nm。”
由于一些原因,12nm和/或11nm是很有吸引力的。多数情况下,16nm/ 14nm与12nm和11mnm之间的IP相似,因此我们很容易决定转向12nm和11nm的半节点工艺。但是,如果IP在12nm和/或11nm不可用,代工厂客户要尽量避免转向12nm和11nm的半节点。
12nm和/或11nm之后,客户可以发展到7nm或类似的工艺。所有这一切都取决于生态系统。并不是所有的代工厂和IP公司都可以承担起在每个节点和节点间开发IP。 “这使半节点的应用变得复杂。这不仅仅是工艺技术,而且还需要IP”据某些消息。
所以客户必须考虑个解决方案。 “你必须更深入地看每个过程,了解规格。 “在选择使用哪个工艺时,很大程度取决于你设计中的重要参数。” Mentor的Rhines说,“代工厂拥有可以使用的物理IP,或者有能力将RTL级别的IP综合到设计中并使其运作,这一点也很重要。”
最重要的是,7nm的情况下代工厂需要与客户进行更多的合作。 Gartner公司的王先生说:“除了使这种技术可以在7nm情况下进行生产外,晶圆代工厂还需要花费更多的时间来帮助设计公司降低设计成本、验证IP和首个成品,以缩短产品上市的时间。
还有一些其他的考虑。代工厂客户也必须检查各种流程,并决定是否满足需求。
并不是所有的工艺都是一样的,但是代工厂正迈入10nm / 7nm的大体方向。 首先,他们在每个节点上都做出更高更薄的鳍片以增大驱动电流。例如,英特尔的14nm finFET技术中鳍片间距42nm,鳍片高度42nm。 10nm工艺中,英特尔的鳍片间距34nm,鳍片高度53nm,这意味着鳍片更高。

图4: 14nm与10nm中的鳍片,金属,栅极间距和单元高度 来源:英特尔
芯片制造商想通过EUV光刻来形成鳍片和其他结构。EUV将有助于简化这一过程,但对于10nm / 7nm来说该技术尚未成熟。 所以对于10nm / 7nm,最初他们将使用193nm浸没式光刻(193nm immersion)和多图案化。 例如,采用193nm浸没式光刻和自对准四重图案(SAQP),英特尔在10nm工艺中开发了36nm金属间距。
英特尔的10nm工艺有12层金属层。最低的两个互连层由铜变为钴,使电迁移率提高了5-10倍,通孔电阻降低了2倍。
相比之下,Global Foundries的7nm finFET工艺具有30nm的鳍距,56nm的接触栅极间距以及40nm的金属间距。与英特尔不同,Global Foundries在金属层上使用了自对准双重图案。
“这使后端操作更加灵活,”Patton说, “我们通过其他方式获得密度。 所以,如果你有关键的线路,你可以广泛地布线。”
Global Foundries的策略与英特尔在互连金属方面也有所不同。“我们通过对铜线的改进,提高了近100倍的电迁移率,所以我们可以继续使用铜来布线,其产量和复杂性有很大的优势。” Patton说。
不过,Globa lFoundries正在使用钴作为MOL,从而降低了接触电阻。

图5:各个节点中的互连,接触点和晶体管 资料来源:应用材料
不过,晶圆代工厂在发展10nm / 7nm中也面临一些挑战,因此客户必须密切关注该技术的关键问题。 “首个挑战就是是边缘放置错误,这是特征尺寸(CD)和覆盖导致的,”TEL和高级技术成员Ben Rathsack说,“在你将前端连接到后端的过程中,MOL往往会遇到一些问题,这确实是最复杂的地方。”
随着时间的推移,台积电和Global Foundries希望在7nm的第二代中加入EUV。而三星计划一开始就计划在7nm的工艺中加入EUV。
这取决于EUV的准备情况, Rathsack说:“如果EUV足够成熟,可以用来节约成本,那也许在7nm的第二代或第三代中,都可能会有EUV的出现。”
关于未来
目前还不清楚是否所有的节点工艺都会长期存在。更大的问题是,finFET尺寸会缩小到哪里? “5nm的布线非常清晰,FinFET至少会发展到5nm。:“还有可能到3nm,” Lam Research公司首席技术官Rick Gottscho表示,“之后还会有其他的解决方案,无论是水平还是垂直的全栅结构(GAA)。会出现新的材料,也会有很多挑战。”
业界正在探索横向全栅FET(gate-all-around FET)和纳米FET(nanosheet FET)。 在这两种情况下,一个finFET放在旁边,栅环绕在其周围。
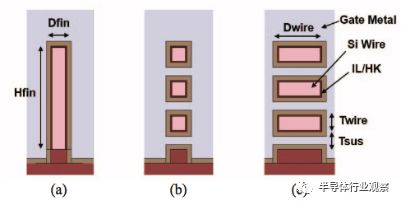
图6:(a) finFET, (b) nanowire和 (c) nanosheet的模拟截面
现在说5nm及以下会发生什么还为时过早。“一些代工厂仍没有确定5nm器件结构。 台积电和GF可能会使用finFET,三星可能会选择5nm(和4nm)的全栅结构(GAA)。 英特尔目前还不清楚,”Gartner的王说,“除非7nm下使用EUV生产有成功的案例,否则我不相信设计师可以发展为5nm的承诺。”
-
芯片
+关注
关注
459文章
51568浏览量
429780 -
晶圆
+关注
关注
52文章
5024浏览量
128638 -
晶体管
+关注
关注
77文章
9837浏览量
139499
发布评论请先 登录
相关推荐
什么是晶圆测试?怎样进行晶圆测试?
晶圆切割目的是什么?晶圆切割机原理是什么?
晶体管晶圆芯片
晶圆表面各部分的名称
关于晶圆介绍以及IGBT晶圆的应用

为什么芯片是方的,晶圆是圆的?

晶圆术语 芯片ECO流程





 工商网监
工商网监
评论