 回顾FPGA的三个时代分析和可编程介绍的分析
回顾FPGA的三个时代分析和可编程介绍的分析

来源:本文由半导体行业观察翻译自IEEE Fellow Stephen M. (Steve) Trimberger写的文章Three Ages of FPGAs: A Retrospective on the First Thirty Years of FPGA Technology,谢谢。
自引入以来,现场可编程门阵列(FPGA)的容量增加了10000倍以上, 性能增加了100倍. 单位功能的成本和功耗都减少了超过1000倍. 这些进步是由工艺缩放技术所推动的, 但是 FPGA 的故事比简单缩放技术的更复杂. 摩尔定律的数量效应推动了FPGA在体系结构、应用和方法方面发生质的变化. 因此, FPGA 已经经历了几个不同的发展阶段. 本文分别总结了发明、扩张、累积这三个阶段, 并讨论了它们的驱动压力和基本特征. 本文最后展望了未来的FPGA阶段.
Xilinx 在1984年引入了第一个现场可编程门阵列(FPGAs), 尽管直到Actel在1988年普及这个术语它们才被称为FPGAs. 在接下来的30年里,我们称之为FPGA的设备的容量增加了1万多倍,速度增加了100倍. 单位功能的成本和能耗降低了1000倍以上(见图1).

图1 Xilinx FPGA属性相对于1988年。容量指逻辑细胞计数。速度指可编程织物的同功能性能。价格指每个逻辑单元。能量指每个逻辑单元。价格和能量按一万倍放大。数据来源: Xilinx发表的数据。
这些进步在很大程度上是由工艺技术驱动的, 随半导体的扩展, 很容易把 FPGA 的进化看成是一个简单的容量发展. 这种看法太简单了。FPGA 进展的真实故事要有趣得多。
自其引入以来, FPGA 设备经过几个不同的发展阶段已取得进展. 每个阶段都受到工艺技术机会和应用程序需求的驱动。这些驱动压力引起设备特性和工具的可观察变化。在本文中, 我们回顾了FPGA的三阶段. 每个阶段长达8年, 并且每一段在回顾中都很明显。
三个阶段分别是:
1)发明阶段, 1984–1991;
2)扩张阶段, 1992–1999;
3)累积阶段, 2000–2007.
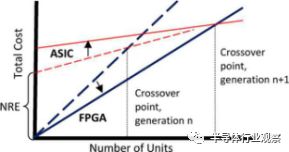
图2. FPGA与ASIC交叉点。 图表显示总成本与单位数量。 FPGA线条较暗,从左下角开始。 随着下一个工艺节点的采用(从较早节点的虚线箭头到稍后节点的实线箭头),由垂直虚线表示的交叉点变大。
二、前言: 关于FPGA的重大问题有哪些?
A.FPGA VS ASIC
20世纪80年代,专用集成电路(ASIC)公司为电子市场带来了一个惊人的产品:定制集成电路。 到20世纪80年代中期,有数十家公司在销售ASIC,在激烈的竞争中,成本低,容量大,速度快的技术更具受青睐。 当FPGA出现的时候,它在所有这几个方面上都并不突出,但却一枝独秀。这是为什么?
ASIC的功能是由自定义掩模工具决定的。ASIC的客户为这些掩模工具支付了前期的一次性工程(NRE)费用。由于没有定制的工具,FPGA降低了预付成本和建立定制数字逻辑的风险。通过制造一种可以被成百上千的客户使用的自定义硅设备,FPGA供应商可以有效地平摊所有客户的NRE成本,从而不会对任何一个客户收取任何费用,又同时增加了每个客户的单位芯片成本。
前期的NRE成本确保了FPGA在某些数量上比ASIC更具成本效益。FPGA供应商在他们的“交叉点”上吹嘘这个数字,这个数字证明了ASIC的更高的NRE开销。 在图2中,图线显示了购买数量单位的总成本。 ASIC具有NRE的初始成本,并且每个后续单元将其单位成本增加到总数。 FPGA没有NRE电荷,但是每个单元的成本都比功能相当的ASIC要高,因此斜率更陡峭。 两条线在交叉点相遇。 如果所需的单元数量少于此数量,则FPGA解决方案便宜; 超过该数量的单位表明ASIC具有较低的总体成本。
由于NRE成本占ASIC总体拥有成本的很大一部分,所以FPGA每单位成本超过ASIC成本的优势随着时间的推移而减少。 图2中的虚线表示某个工艺节点的总成本。 实线表示下一个工艺节点的情况,NRE成本增加,但是每个芯片的成本较低。 FPGA和ASIC都利用低成本制造,而ASIC NRE收费继续攀升,推高交叉点。 最终,交叉点变得如此之高,以至于大多数客户,单元的数量已经不再适用于ASIC。 定制芯片只保证非常高的性能或很高的体积; 所有其他人可以使用可编程解决方案。
摩尔定律最终将推动FPGA能力覆盖ASIC要求,这是对可编程逻辑业务的一个基本早期认识。如今,器件成本在性能,上市时间,功耗,I / O容量以及其他功能方面都不如FPGA。许多ASIC客户使用较老的工艺技术,降低了NRE成本,但降低了单芯片成本优势。
FPGA不仅消除了前期掩蔽费用并降低库存成本,而且通过消除整个类别的设计问题也降低了设计成本。这些设计问题包括晶体管级设计,测试,信号完整性,串扰,I / O设计和时钟分配。
与低前期成本和简单设计一样重要的是,主要的FPGA优势是即时可用性和降低的故障可见性。尽管大量的仿真时,ASIC第一次似乎很少是正确的。随着晶圆制造周转时间在几个星期或几个月内,芯片重新调整对时间安排造成重大影响,而且随着掩膜成本的上升,芯片重新调整对公司日益增长的水平而言是显而易见的。错误的高成本要求广泛的芯片验证。由于FPGA可以在几分钟内完成重做,因此FPGA设计不会因为错误而延误数周。因此,验证不一定要彻底。 “自我模仿”,俗称“下载试用”,可以代替大量的模拟。
最后看一下ASIC生产风险:ASIC公司只有在客户的设计投入生产时才赚钱。 在20世纪80年代,由于开发过程中需求的变化,产品故障或完全设计错误,只有三分之一的设计实际投入生产。 三分之二的设计损失了钱。 这些损失不仅由ASIC客户承担,还由ASIC供应商承担,这些供应商的NRE收费很少包括他们的实际成本,从未在快速贬值的制造设施中弥补失去机会的成本。 另一方面,可编程逻辑公司和客户仍然可以小批量赚钱,并且可以快速纠正小的错误,而不需要昂贵的掩模。
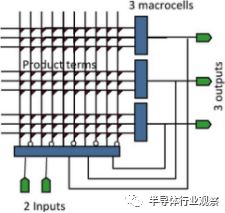
图3.通用PAL架构。
B. FPGA VS PAL
可编程逻辑在FPGA之前就已经建立起来了。在20世纪80年代早期,EPROM编程的可编程阵列逻辑(PAL)已经开辟了一个市场。但是,FPGA具有体系结构优势。为了理解FPGA的优势,我们首先看看这些早期的80年代器件的简单可编程逻辑结构。一个PAL设备,如图3所示,由一个两级逻辑结构组成。显示输入在底部。在左边,一个可编程和阵列产生产品条款,以及输入和它们的反转的任何组合。右侧块中的固定或门完成宏单元产品术语的组合逻辑功能。每个宏单元输出是芯片的输出。宏单元中的可选寄存器并反馈到和阵列的输入使得实现非常灵活的状态机成为可能。
不是每一个功能都可以通过PAL的宏单元阵列实现一次,但是几乎所有的常用功能都可以,而那些不可能通过阵列实现的功能。无论执行的功能还是位于阵列中的位置,通过PAL阵列的延迟都是相同的。 PAL具有简单的拟合软件,可将逻辑快速映射到阵列中的任意位置,而不会影响性能。 PAL适配软件可以从独立的EDA供应商处获得,使IC制造商可以轻松地将PAL添加到他们的产品线中。
从制造的角度来看,PAL是非常有效的。 PAL结构与EPROM存储器阵列非常相似,其中晶体管被密集地包装以产生有效的实现。 PAL与存储器非常相似,许多存储器制造商能够用PAL来扩展他们的产品线。当周期性内存业务出现停滞时,内存厂商进入可编程逻辑业务。
当考虑缩放时,PAL的架构问题是显而易见的。在和阵列中的可编程点的数量随着输入数量的平方(更确切地说,输入乘以乘积项)的平方增长。工艺缩放以收缩因数的平方来提供更多的晶体管。然而,阵列中的二次增加限制了PAL仅通过收缩因数线性增长逻辑。 PAL输入和产品期限也很重,所以延迟随着尺寸的增加而迅速增长。像任何这种类型的存储器,PAL都具有跨越整个芯片的字线和位线。随着每一代,所编程的晶体管的驱动与负载的比例下降。更多的投入或产品条款增加了这些线路的负载。增加晶体管尺寸以降低电阻也提高了总电容。为了保持速度,耗电量急剧上升。大型PAL在区域和性能上都是不切实际的。作为回应,在20世纪80年代,Altera率先推出了复杂可编程逻辑器件(CPLD),由多个PAL型块组成,其中较小的交叉开关连接。但FPGA具有更具可扩展性的解决方案。
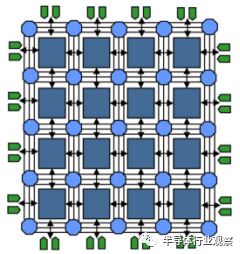
图4.通用阵列FPGA架构。 4 4阵列,每行和每列有三条接线轨迹。 开关位于交叉点的圆上。 设备输入和输出分布在阵列周围。
FPGA的创新是消除了提供可编程性的数组和阵列。相反,配置存储器单元分布在阵列周围以控制功能和布线。这种改变放弃了PAL结构的类似存储器阵列的效率,有利于架构的可扩展性。如图4所示,FPGA的架构由一系列可编程逻辑块组成,并与现场可编程开关互连。 FPGA的容量和性能不再受到阵列的二次增长和布线布局的限制。并不是每一个功能都是芯片的输出,所以容量可以随着摩尔定律而增长。
•FPGA架构看起来不像内存。 设计和制造与内存非常不同。
•逻辑块较小。 不能保证一个单一的功能可以融入其中。 因此,提前确定将有多少逻辑适合FPGA是很困难的。
•FPGA的性能取决于逻辑放置在FPGA中的位置。 FPGA需要布局和布线,所以完成的设计的性能不容易事先预测。
•需要使用复杂的EDA软件来将设计融入FPGA。
随着阵列和阵列的消除,FPGA架构师可以自由构建任何逻辑模块和任何互连模式。 FPGA架构师可以定义全新的逻辑实现模型,而不是基于晶体管或门,而是基于自定义功能单元。 延迟模型不需要基于金属线,而是基于节点和开关。 这个架构自由迎来了FPGA的第一个阶段,即发明阶段。
三、发明阶段 1984~1991
首款FPGA,即赛灵思XC2064,只包含64 个逻辑模块,每个模块含有两个3输入查找表 (LUT) 和一个寄存器。按照现在的计算,该器件有 64 个逻辑单元——不足 1000 个逻辑门。尽管容量很小,XC2064 晶片的尺寸却非常大,比当时的微处理器还要大;而且采用 2.5 微米工艺技术勉强能制造出这种器件。
每功能的晶片尺寸和成本至关重要。XC2064 只有 64 个触发器,但由于晶片太大,成本高达数百美元。产量对大晶片来说是超线性的,因此晶片尺寸增加 5% 就会让成本翻一倍,让良率降至零,同时也导致初期的赛灵思无产品可卖。成本控制不仅仅是成本优化的问题;更是牵扯到公司生存问题。
在成本压力下,FPGA 架构师寻求通过架构和工艺创新来尽可能提高 FPGA 设计效率。尽管基于 SRAM 的 FPGA 是可重编程的,但是片上 SRAM 占据了FPGA 大部分的晶片面积。基于反熔丝的 FPGA 以牺牲可重编程能力为代价,避免了 SRAM 存储系统片上占位面积过大问题。
在20世纪80年代,赛灵思的四输入LUT架构被认为是“粗粒度”的。四输入功能被视为逻辑设计中的“甜蜜点”,但网表分析表明许多LUT配置未被使用。而且,许多LUT没有使用投入。为了提高效率,FPGA架构师希望能够消除逻辑块中的浪费。几家公司实现了包含固定功能的更细粒度的体系结构,以消除逻辑单元浪费。 Algotronix CAL使用一个固定MUX功能实现双输入LUT 。 Concurrent公司(后来的Atmel)和他们的被许可人IBM公司使用了一种小型单元,包括双输入nand和异或门和CL器件中的一个寄存器。皮尔金顿将其架构作为逻辑块作为逻辑块。他们授权Plessey(ERA系列),Toshiba(TC系列)和Motorola(MPA系列)使用基于nand-cell的SRAM编程设备。细粒度架构的极限是交叉点CLi FPGA,其中各个晶体管通过反熔丝可编程连接相互连接。
早期的FPGA架构师指出,高效的互联体系结构应该遵守集成电路的二维性。 PAL的长而慢的线被相邻块之间的短连接代替,这些短连接可以根据需要通过编程串联在一起以形成更长的路由路径。最初,简单的传输晶体管将信号引导通过互连段到相邻的块。接线效率高,因为没有未使用的导线部分。这些优化极大地缩小了互连区域,并使FPGA成为可能。与此同时,由于大电容和通过晶体管开关网络分布的串联电阻,通过FPGA布线增加了信号延迟和延迟不确定性。由于互连线和交换机增加了尺寸,但不是(计费)逻辑,所以FPGA架构师不愿增加太多。早期的FPGA非常难以使用,因为它们缺乏互连。
四、发明阶段回顾
在发明阶段,FPGA很小,所以设计问题很小。虽然他们是可取的,综合甚至自动布局和路由不被认为是必不可少的。许多人认为,即使在当时的个人电脑上尝试设计自动化也是不切实际的,因为在大型计算机上ASIC的布局和布线正在进行。手动设计,无论是逻辑的还是物理的,都是可接受的,因为问题的规模很小。手工设计往往是必要的,因为芯片上的路由资源有限。
完全不同的体系结构排除了ASIC业务中可用的通用FPGA设计工具。 FPGA供应商为其设备增加了EDA开发的负担。随着FPGA供应商尝试并改进其架构,这最终被认为是一个优势。过去十年的PAL制造商依靠外部工具供应商提供软件来将设计映射到他们的PAL中。因此,PAL供应商仅限于工具供应商支持的架构,导致商品化,低利润率和缺乏创新。在FPGA架构蓬勃发展的同时,PLD架构被扼杀。
强制性软件开发的另一个优势是,FPGA客户不需要从第三方EDA公司购买工具,这会增加NRE成本。正如他们对NRE收费一样,FPGA供应商将他们的工具开发成本分摊到他们的硅定价中,从而使他们的设备的前期成本非常低。无论如何,EDA公司对FPGA工具的兴趣不大,因为市场分散,数量少,销售价格低廉,而且需要在动力不足的电脑上运行。
在发明阶段,FPGA比用户想要投入的应用要小得多。因此,多FPGA系统变得流行起来,自动化的多芯片分区软件被确定为FPGA设计套件的重要组成部分。
图5. FPGA架构系谱树
五、FPGA回顾
发明的阶段以在FPGA业务中的残酷耗损而告终。 第三节和在图5的FPGA族谱里大部分的公司或产品名称,一个现代读者可能不会不知道。 许多公司消失了。 其他人在退出FPGA业务时悄然出售资产。 这种损耗的原因不仅仅是正常的市场动态。 技术发生了重大变化,那些没有利用这些变化的公司就无法进行竞争。 由于摩尔定律引起的数量变化导致了使用半导体技术构建的FPGA的质变。 这些变化是扩张阶段的特征。
六、扩张阶段 1992~1999
到了20世纪90年代,摩尔定律继续快速前进,晶体管数量每两年增加一倍。由于开创无晶圆厂商业模式,FPGA创业公司在二十世纪九十年代初通常无法获得领先的硅技术。结果,FPGA开始落后于工艺引入曲线。在20世纪90年代,随着代工厂意识到使用FPGA作为过程驱动器应用的价值,他们成为了过程领导者。一旦能够用新技术生产晶体管和导线,代工厂就能够构建SRAM FPGA。 FPGA厂商出售他们巨大的设备,而代工厂改进他们的流程。新一代硅片的可用晶体管数量增加了一倍,这使可能最大的FPGA尺寸增加了一倍,而每个功能的成本也降低了一半。比简单的晶体管缩放更重要的是,引入化学机械抛光(CMP)允许铸造厂堆叠更多的金属层。由于昂贵的(不可消耗的)互连的成本比晶体管的成本下降得更快,FPGA供应商积极地增加了设备上的互连以适应更大的容量(参见图6),这对于ASIC来说是有价值的。这个快速的改进过程有以下几个效果。
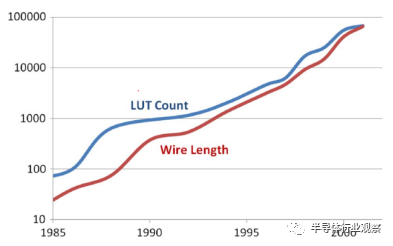
图6. FPGA LUT和互连导线的增长导线长度,以数百万个晶体管间距进行测量。
A.区域变得珍贵
在20世纪90年代中期没有人加入FPGA行业,他们认为成本不重要,或者地区不重要。但是,那些在20世纪80年代经历过产品开发痛苦的人当然看到了差异。在20世纪80年代,晶体管的效率是必要的,以便交付任何产品。在20世纪90年代,这仅仅是一个产品定义的问题。面积仍然是重要的,但现在它可以被交易的性能,功能和易用性。所得到的器件的硅片效率较低。在几年前的发明阶段,这是不可想象的。
B.设计自动化变得必不可少
在扩展阶段,FPGA器件容量随着成本的下降而迅速增长。 FPGA应用程序对于手动设计而言变得太大。 1992年,旗舰产品Xilinx XC4010交付了一个(声称)最多10000个门。到1999年,Virtex XCV1000被评为一百万。在20世纪90年代早期,在扩张阶段开始时,自动布局和路由是首选的,但不是完全可信的。到20世纪90年代末,自动化综合,布局布线,是设计过程中需要采取的步骤。没有自动化,设计的努力就会太棒了。现在,FPGA公司的寿命取决于设计自动化工具的目标设备的能力。那些控制他们软件的FPGA公司控制着他们的未来。
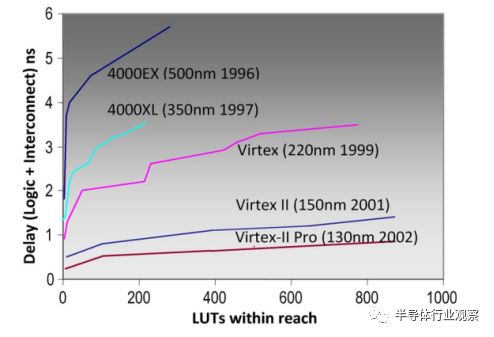
图7.更长线长分段性能缩放。
来自工艺缩放的更便宜的金属导致更多可编程的互连线,使得自动化的放置工具可以以较不精确的放置成功。自动化设计工具需要自动化友好型架构,具有常规和丰富的互连资源的架构,以简化算法决策。更便宜的电线也承认了更长的电线分割,跨越多个逻辑块的互连线。跨越多个块的电线有效地使物理距离逻辑更接近逻辑,从而提高性能。图7中的图表显示了来自工艺技术和互连范围组合的大的性能收益。过程缩放本身会降低曲线,但保持形状;更长的分割平坦了曲线。较长的分段互连简化了布局,因为采用较长的互连,将两个模块精确对齐以将其与高性能路径连接起来并不是必须的。
另一方面,当线段的整个长度未被使用时,金属迹线的部分被有效地浪费。许多硅片效率的发明架构是以布线效率为基础的,其特点是短线可以消除浪费。通常,他们严格遵循物理硅的二维限制,从而使这些FPGA成为“蜂窝”标签。在扩展阶段,更长的线分割是可能的,因为废金属的成本现在是可以接受的。由最邻近连接主导的体系结构无法与利用较长线分割的体系结构的性能或易于自动化相匹配。
类似的效率转变应用于逻辑块。在发明阶段,小的简单的逻辑块是有吸引力的,因为它们的逻辑延迟很短,并且因为在未使用或部分使用时浪费很少。当一个三输入函数在其中被实例化时,四输入LUT中的一半配置存储器单元被浪费了。聪明的设计人员可以手动将复杂的逻辑结构映射到最小数量的细粒度逻辑块,但自动化工具并不成功。对于更大的功能,连接几个小块的需求对互连提出了更高的要求。在扩张阶段,不仅有更多的逻辑块,而且块本身变得更加复杂。
许多具有不规则逻辑块和稀疏互连的高效发明架构难以自动布局和布线。在发明阶段,这不是一个严重的问题,因为设备足够小,手工设计是实用的。但扩张阶段的许多设备和公司都面临着过高的面积效率。基于最小化逻辑浪费的细粒度体系结构(如Pilkington nand-gate模块,Algotronix / Xilinx 6200多路复用器2LUT模块,交叉点晶体管模块)简直就不存在了。通过互连来实现其效率的架构也已经死亡。这些包括所有最近邻居基于网格的架构。扩展阶段也注定了时间复用设备,因为只需要等待下一代处理,相当的容量扩展就可以避免复杂性和性能的损失。 FPGA业务中的幸存者是那些利用工艺技术进步实现自动化的公司。 Altera首先将CPLD的长距离连接引入Altera FLEX架构。 FLEX比其他被短导线占主导地位的FPGA的自动化程度更高。它取得了快速的成功。 20世纪90年代中期,美国电话电报公司(AT&T)/朗讯(Lucent)发布了ORCA ,赛灵思公司在扩大XC4000互连数量和长度的同时扩大了设备规模。扩张阶段由此确立。
C.作为选择技术的SRAM的出现
摩尔定律快速发展的一个方面就是需要站在过程技术的最前沿。将容量加倍和逻辑成本减半的最简单方法是针对下一个工艺技术节点。这迫使FPGA厂商采用领先的工艺技术。采用新技术难以实现的技术的FPGA公司在结构上处于劣势。非易失性可编程技术如EPROM,Flash和反熔丝就是这种情况。当一种新的工艺技术可用时,可用的第一个组件是晶体管和电线,这是电子电路的基本组成部分。基于静态内存的设备可以立即使用新的更密集的进程。对于特定的技术节点,防伪设备被精确地推广为更高效,但需要数月或数年的时间才能确定新节点上的反熔丝。在反熔丝被证实的时候,SRAM FPGA已经开始在下一个节点上交付。防伪技术无法跟上技术发展的步伐,所以为了维持产品的平价,它们的效率要比SRAM高一倍。
防伪装置有第二个缺点:缺乏重新编程能力。随着客户习惯于“易失性”SRAM FPGA,他们开始体会到系统内可编程性和硬件现场更新的优势。相比之下,一次性可编程设备需要进行物理处理才能更新或修复设计错误。反熔丝设备的替代品是一个广泛的类似ASIC的验证阶段,这削弱了FPGA的价值。
摩尔定律在扩张阶段的快速发展将反熔丝和闪存FPGA降级为利基产品。
D. LUT作为选择逻辑单元的出现
虽然在扩张时期被记录下来的低效率,但有几个原因,LUT仍然存在并占据主导地位。首先,基于LUT的体系结构是综合工具的简单目标。这个说法在20世纪90年代中期会有争议,当时综合供应商抱怨FPGA不是“合成友好的”。这种观点产生是因为综合工具最初是针对ASIC设计的。他们的技术映射者期望一个小型库,其中每个单元被描述为一个带有逆变器的网络。由于LUT实现了22n个输入组合中的任何一个,所以完整的库将是巨大的。 ASIC技术映射工作者在基于LUT的FPGA上做了apoor工作。但到了20世纪90年代中期,有针对性的LUT映射器利用了将任意函数映射到LUT中的简单性。
LUT具有隐藏的效率。 LUT是一个内存,并且存储器在硅片中有效地布局。 LUT还可以节省互连。 FPGA可编程互连在面积和延迟方面是昂贵的。 FPGA互连不像ASIC那样简单的金属线,而是包含缓冲区,路由多路复用器和存储单元来控制它们。因此,更多的逻辑成本实际上是在互连。由于LUT实现了其输入的任何功能,因此自动化工具只需要在LUT中将所需的信号一起发送,以淘汰这些输入的功能。没有必要为了创建一小组输入的所需功能而使得多级LUT成为可能。 LUT输入引脚是可任意交换的,所以路由器不需要针对特定的引脚。结果,基于LUT的逻辑减少了实现功能所需的互连数量。通过良好的综合,来自未使用的LUT功能的浪费小于来自减少的互连要求的节省。
分布式存储单元编程允许架构自由,并使FPGA供应商几乎可以普遍获得工艺技术。用于逻辑实现的LUT减轻了互连的负担。 Xilinx衍生的基于LUT的体系结构出现在赛灵思的第二个来源:Monolithic Memories,AMD和AT&T。在扩展阶段,其他公司,特别是Altera和AT&T / Lucent也采用了存储单元和LUT架构。
七、插曲:FPGA 钟形容量曲线
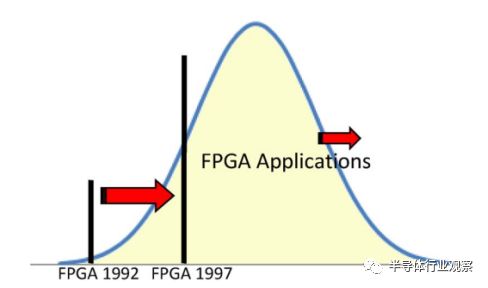
图8. FPGA市场的增长
图8中的钟形曲线表示ASIC应用程序的大小分布的直方图。某个时候的FPGA容量是X轴上的一个点,用竖条表示。条形图左侧的所有应用程序都是可以由FPGA来处理的应用程序,因此FPGA的可寻址市场是条形图左侧曲线下方的阴影区域。在扩展阶段,摩尔定律的FPGA容量增加了,所以吧移到了右边。当然,应用程序的整个钟形曲线也向右移动,但应用程序大小的增长速度比FPGA容量增长要慢。结果,代表FPGA的条形图相对于设计的分布迅速地移动。由于FPGA解决了曲线的低端问题,因此即使可用容量略有增加,也承认了大量的新应用。在扩展阶段,FPGA容量覆盖了现有设计的不断增长的一小部分,并逐渐成为解决大部分ASIC应用的技术。
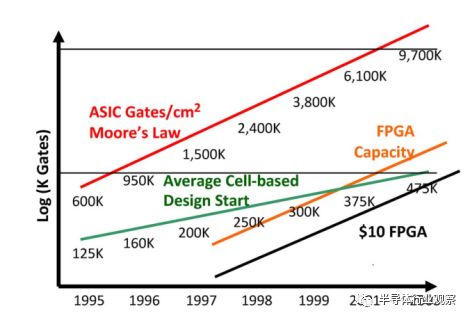
图9.设计差距 来源:Synopsys,Gartner,VLSI Technology,Xilinx。
从1990年代后期在EDA供应商中流行的“设计差距”幻灯片中也可以看出这种增加的适用性(图9)。按照摩尔定律,ASIC和FPGA的容量在增长:ASIC以每年59%的速度增长,FPGA以每年48%的速度增长。观察到的平均ASIC设计开始增长速度要慢得多,每年只有25%。因此,FPGA容量在2000年达到了平均的ASIC设计规模,但是对于一个大的(昂贵的)FPGA。但到了2004年,预计10美元的FPGA将满足ASIC的平均要求。在二十一世纪初,这个交叉点进一步发展,因为FPGA解决了ASIC市场的低端问题,而这些小型设计成为了FPGA设计。平均ASIC设计尺寸计算中不再包含小型设计,从而在新的千年中平均ASIC设计尺寸大幅增加。今天,由于FPGA几乎成功吸收了ASIC业务的整个低端市场,所以平均ASIC比图9所显示的要大得多。
八、扩张阶段回顾
通过扩张阶段,摩尔定律迅速提高了FPGA的容量,导致了对设计自动化的需求,并允许更长的互连分段。过于高效的架构,无法有效自动化简单地消失。 SRAM器件首先开发新的工艺技术并主导业务。由于FPGA器件容量的增长速度超过了应用的需求,FPGA正在侵蚀ASIC领域。用户不再要求使用多FPGA分区软件:设计有时适合于现有的FPGA。
随着FPGA越来越流行,EDA公司开始为他们提供工具。然而,EDA公司的提议被怀疑。 FPGA退伍军人已经看到PLD供应商如何通过交出软件而失去对其创新的控制。他们拒绝让这种情况发生在FPGA领域。此外,主要的FPGA公司担心客户可能会依赖外部EDA公司的工具。如果发生这种情况,EDA公司可以通过软件工具价格有效地提升FPGA NRE。这将削弱FPGA的价值主张,将交叉点转回到较低的交易量。一些重要的FPGA-EDA联盟是在合成域V中由定义体系结构的物理设计工具进行的。尽管联盟,FPGA公司保持竞争力的项目,以防止依赖的可能性。在扩展阶段,FPGA供应商发现自己与ASIC技术和EDA技术竞争。
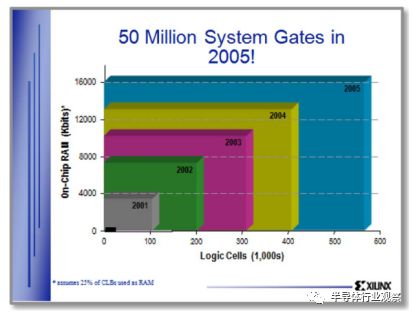
图10. 赛灵思市场营销,图片由Xilinx提供。
九、插曲:XILINX的市场
到20世纪90年代后期,扩展阶段在FPGA业务中得到了很好的理解。 FPGA供应商正在积极寻求处理技术,以解决其尺寸,性能和容量问题。 每一代新工艺都带来了许多新的应用。 图10中的幻灯片摘自2000年Xilinx市场推广演示。当时可用的最大的FPGA Virtex 1000被描述为左下角的小黑色矩形。 幻灯片显示,扩张阶段将继续有增无减,在接下来的五年里,把城门数量增加到5000万。 尽管摩尔定律坚定不移,但这并没有发生。 在下面的章节中,我们将研究真正发生的事情和原因。
图11. FPGA可寻址市场的增长正在缩小。
十、累积阶段, 2000–2007.
在新千年的开始,FPGA是数字系统的通用组件。容量和设计规模不断扩大,FPGA在数据通信行业中发现了巨大的市场。二十一世纪初的网络泡沫造成了对低成本的需求。硅片制造的成本和复杂性日益增加,消除了“临时”的ASIC用户。定制芯片对于一个小团队来说成功执行风险太大了。当他们看到他们可以将他们的问题融入到FPGA中时,他们就成了FPGA的客户。
就像在扩张阶段一样,摩尔定律的必然步伐使FPGA变得更大。现在他们比典型的问题大。有能力比所需要的要多,没有什么不好的,但是也没有什么特别的美德。结果,客户不愿意为最大的FPGA支付高额的费用。
仅仅增加产能也不足以保证市场的增长。再看图11,FPGA钟形曲线。由于FPGA容量通过了平均设计尺寸,钟形曲线的峰值,容量的增加承认逐渐减少的应用。几乎可以保证在扩张时期获得成功的产品的尺寸,在接下来的几年里,吸引越来越少的新客户。
FPGA供应商通过两种方式解决了这一挑战。对于低端市场,他们重新关注效率,并生产低容量,低性能的“低成本”FPGA产品系列:Xilinx的Spartan,Altera的Cyclone和Lattice的EC / ECP。
对于高端市场,FPGA供应商希望能够让客户更容易地填满他们宽敞的FPGA。他们为重要功能制作了软逻辑(IP)库。这些软逻辑功能中最值得注意的是微处理器(Xilinx MicroBlaze和Altera Nios),存储器控制器和各种通信协议栈。在以太网MAC在Virtex-4的晶体管上实现之前,它是作为Virtex-II的软核心在LUT中实现的。 IP组件的标准接口消耗了额外的LUT,但与节省设计工作量相比,效率不高。
大型的FPGA比一般的ASIC设计更大。到2000年代中期,只有ASIC仿真器需要多芯片分区器。更多的客户有兴趣在一个单一的FPGA上聚合多个可能不相关的组件。赛灵思推出了“互联网可重构逻辑”和FPGA区域划分,允许功能单元动态插入可编程逻辑资源的一个子集。
设计的特点在2000年代发生了变化。大型FPGA承认大型设计是完整的子系统。 FPGA用户不再只是简单地实现逻辑;他们需要他们的FPGA设计来遵守系统标准。这些标准主要是信号和协议的通信标准,用于连接外部组件或在内部组件之间通信。由于FPGA在计算密集型应用中的作用越来越大,处理标准也开始适用。随着FPGA成长为客户整体系统逻辑的一小部分,其成本和功耗也相应增长。这些问题比扩张阶段变得更为重要。
遵循标准,降低成本和降低功耗的压力导致了架构战略的转变,从简单地增加可编程逻辑和乘以摩尔定律,如在扩展阶段所做的,到添加专用的逻辑块。这些模块包括大存储器,微处理器,乘法器,灵活的I / O和源同步收发器。由专门设计的晶体管而不是ASIC门构成,它们通常比ASIC的实现效率更高。对于使用它们的应用程序,他们减少了可编程性的面积,性能,功耗和设计工作量。
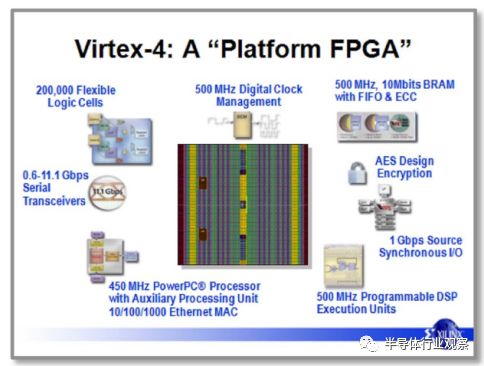
图12.赛灵思市场营销 图片由Xilinx提供。
其结果是“平台FPGA”,从2005年的赛灵思营销幻灯片中捕获到,如图12所示。与图10相比较,不再是数百万门的消息,而是预定义的,性能专用块。甚至“门”这个词也从幻灯片中消失了。这个FPGA不仅仅是LUT,触发器,I / O和可编程路由的集合。它包括乘法器,RAM块,多个Power-PC微处理器,时钟管理,千兆速率源同步收发器和位流加密,以保护设计的IP。 FPGA工具不断增长,以实现这一不断增长的实施目标。
为了减轻使用新功能和满足系统标准的负担,FPGA供应商提供了逻辑发生器,通过将其专用功能和软逻辑相结合来构建目标功能。软逻辑的生成器和库为软核和强化处理器上的外设提供了CoreConnect,AXI和其他总线的接口。他们还构建了围绕串行收发器的固定功能物理接口的总线协议逻辑。 Xilinx系统生成器和Altera DSP Builder自动化了DSP系统的大部分组装,由固定功能和LUT组合而成。为了简化微处理器系统的创建,赛灵思提供了嵌入式设计套件(EDK),而Altera则发布了其嵌入式系统设计套件(ESDK)。这些功能的演示包括在FPGA处理器上运行的FPGA,在FPGA架构中进行视频压缩和解压缩。
但是,那些不需要固定职能的积累年龄的客户是什么呢?对于不需要Power-PC处理器,存储器或乘法器的客户来说,该块的面积被浪费了,有效地降低了FPGA的成本和速度。起初,FPGA供应商试图确保这些功能可以用于逻辑,如果他们不是主要用途的需要。他们提供了“大型LUT映射”软件,将逻辑移入未使用的RAM块。赛灵思发布了“超级控制器”,将状态机映射到Virtex-II Pro中硬化Power-PC的微处理器代码。但是这些措施最终被认为是不重要的。这表明我们距离发明阶段还有多远,FPGA供应商和客户都只是接受了浪费的领域。 Xilinx副总裁表示,他将在FPGA上提供四个Power-PC处理器,并不关心客户是否使用其中任何一个。我们给他们免费的处理器。

表1 FPGA上选定专用逻辑
十一、插曲:所有阶段都如此
积累的阶段并不是独一无二的,正如增加设备的能力并不是独特的扩张阶段或独特的发明阶段的建筑创新。 在发明阶段,门,路由和三态总线是可用的,而算术,内存和专用I / O出现在扩展阶段(表1)。 在FPGA的各个阶段都增加了专用的模块,这充分表明它们将继续在多样性和复杂性方面发展。 一般来说,成功的专用功能本质上是通用的,使用可编程LUT和互连的灵活性来定制功能。 尝试生产针对特定领域或特定应用的FPGA尚未证明是成功的,因为它们失去了FPGA经济所依赖的批量生产的优势。 当然,直到“积累阶段”才引起了“通信FPGA”的兴起。
十二、累积阶段回顾
A.应用
“积累阶段”中FPGA的最大变化是目标应用程序的变化。 FPGA业务不是从通用的ASIC替代发展而是由通信基础设施的采用。 像Cisco这样的公司使用FPGA来定制数据路径,以便通过交换机和路由器转发大量的互联网和打包语音流量。 他们的性能要求消除了标准微处理器和阵列处理器,单位体积在FPGA交叉点内。 新的网络路由架构和算法可以在FPGA中快速实施并在现场进行更新。 在“积累阶段”,通信行业的销售额迅速增长,超过FPGA业务的一半。
当然,这一成功使得主要FPGA制造商为通信行业定制FPGA。通信专用FPGA集成了高速I / O收发器,数千个专用高性能乘法器,能够在不牺牲吞吐量的情况下制作大量数据路径和深度流水线。为了更好地满足通信应用需求而添加的专用块和路由减少了可用的通用逻辑区域。到2000年代末,FPGA不像通用数据路由引擎那样通用ASIC替代。随着多核处理器和通用图形处理器单元(GPGPU)的出现,FPGA仍然是高吞吐量,实时计算的首选。同时,FPGA保持其通用性。 FPGA逐位可编程能力确保了它们在包括控制和汽车系统在内的广泛应用中的持续使用。
B. 摩尔定律
经典的Dennard缩放,同时在成本,容量,功耗和性能方面进行了改进,在2000年代中期结束。 后来的技术世代仍然在容量和成本方面进行了改进。 电力也在不断改善,但与性能之间有着明显的折衷。从一个技术节点到下一个技术节点的性能收益是适度的,并且与节能相抵消。 这种效应在图1中的性能增长放缓中表现得很明显。这些折衷也推动了功能的积累,因为如在扩展阶段那样简单地依赖于工艺技术的缩放并不足以改善功率和性能。逻辑强化提供了必要的改进。
我们现在将步入FPGA的下一个阶段,那么下一个阶段是什么呢?
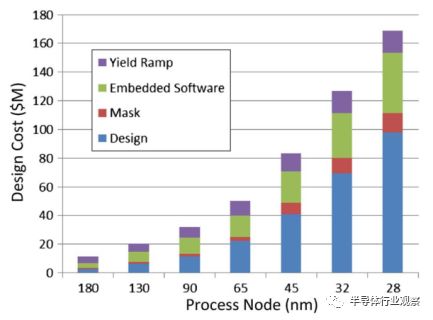
图13.按全球流程节点估算的芯片设计成本。数据:赛灵思和Gartner,2011。
十三、目前阶段:不再是可编程逻辑
在积累阶段结束之前,FPGA不是门阵列,而是集成了可编程逻辑的累积模块集合。他们仍然是可编程的,但不限于可编程逻辑。在累积阶段获得的可编程性的额外维度增加了设计负担。设计工作是FPGA与ASIC竞争的一个优势,与新近到来的多核处理器和GPU竞争是一个劣势。
FPGA开发者继续承受着压力。 2008年开始的经济放缓继续推动降低成本的愿望。这种压力不仅体现在降低功能价格的要求上,而且体现在降低使用这些设备的成本的低功耗上。后Dennard缩放处理技术未能实现新工艺技术在过去几十年中所带来的成本,容量,性能,功耗和可靠性方面的巨大并发利益。特别需要关注的是权力和绩效之间的权衡。怎么办?
A.应用
在积累阶段,20世纪80年代把定制设备推向市场的ASIC公司正悄然消失。当然,定制插座专用ASIC器件仍然存在,但仅限于具有非常大的体积或极端操作要求的设计。 FPGA是否打败了他们?好吧,部分。在2000年代,ASIC NRE收费对于大多数应用来说太大了。这可以在图13中看到,其中开发成本以百万美元绘制在技术节点上。定制设备的开发成本达到几十亿美元。一家将20%的收入用于研发的公司需要从芯片销售中获得5亿美元的收s入,以此来支付亿元的开发成本。 FPGA交叉点达到了数百万个单位。有很少的芯片可以销售,特别是微处理器,存储器和手机处理器。伴随着另一次经济衰退,销售不确定性和新产品收入的长期交易,结果是不可避免的:如果应用程序需求可以通过可编程器件满足,则可编程逻辑是首选解决方案。 FPGA的优势从最初的阶段起依然在运行:通过共享开发成本降低总体成本。
ASIC并没有消亡。 ASIC通过以应用特定标准产品(ASSP)片上系统(SoC)器件的形式增加可编程性而存活并扩展。 SoC结合了一系列固定功能模块和一个微处理器子系统。通常为特定应用领域选择功能块,如图像处理或联网。微处理器控制数据流,并允许通过编程以及现场更新进行定制。 SoC为硬件解决方案提供了结构,编程微处理器比设计硬件更容易。利用FPGA的优势,可编程ASSP器件服务于更广泛的市场,更广泛地分摊其开发成本。构建ASSP SoC的公司成为无晶圆半导体供应商,能够满足高开发成本所需的销售目标。
随着ASIC向SoC转移,可编程逻辑供应商开发了可编程SoC。这绝对不是在数据通信领域如此流行的数据吞吐量引擎,也不是门阵列。可编程系统FPGA是完全可编程的片上系统,包含存储器,微处理器,模拟接口,片上网络和可编程逻辑模块。这种新型FPGA的例子是Xilinx All-Programmable Zynq,Altera SoC FPGA和Actel / Microsemi M1。
B.设计工具
这些新的FPGA具有新的设计要求。最重要的是,它们是软件可编程的,也是硬件可编程的。微处理器并不是象“积累阶段”(Age of Accumulation)那样将简单的硬件模块放入FPGA中,而是包含一个带有高速缓存,总线,片上网络和外设的完整环境。捆绑软件包括操作系统,编译器和中间件:整个生态系统,而不是一个集成的功能块。一起编程软件和硬件增加了设计复杂性。
但这仍然是冰山一角。为了实现替代ASIC或SoC的目标,FPGA继承了这些器件的系统要求。现代FPGA具有功率控制,如电压调节和Stratix自适应体偏置。最先进的安全性是必需的,包括Xilinx Zynq SoC和Microsemi SmartFusion中的公钥加密技术。完整的系统需要混合信号接口来实现真实的接口。这些也监测电压和温度。所有这些都需要FPGA成为一个完整的片上系统,一个可信的ASSP SoC器件。因此,FPGA已经发展到逻辑门阵列通常不到面积的一半。一路上,FPGA设计工具已经发展到包含广泛的设计问题。 FPGA公司的EDA工程师数量与设计工程师的数量相当。
C.工艺技术
尽管在过去的三十年中,工艺规模一直在稳步持续发展,但摩尔定律对FPGA架构的影响在不同的阶段是截然不同的。为了在发明阶段取得成功,FPGA需要积极的架构和流程创新。
在扩张阶段,驾驶摩尔定律是解决不断增长的市场的最成功的方法。随着FPGA逐渐成为系统组件,它们被要求满足这些标准,网络泡沫破裂要求它们以更低的价格提供这些接口。 FPGA行业依靠工艺技术扩展来满足其中的许多要求。
自Dennard缩放结束以来,工艺技术的性能收益有限,无法达到功耗目标。每个工艺节点也提供了较少的密度改进。随着复杂工艺变得越来越昂贵,每个新节点中晶体管数量的增长减慢。一些预测声称,每个晶体管的成本将上升。像整个半导体行业一样,FPGA产业依靠技术扩展来提供改进的产品。如果改进不再来自技术扩展,那么它们从哪里来?
减缓工艺技术改进提高了新型FPGA电路和架构的可行性:回到发明阶段。但是这并不像回到1990年那么简单。这些改变必须在不降低FPGA的易用性的情况下进行。这个新阶段给FPGA电路和应用工程师带来了更大的负担。
D.设计努力
注意最后一节的重点是设备属性:成本,容量,速度和功耗。成本,容量和速度正是FPGA在20世纪80年代和90年代处于ASIC劣势的那些属性。然而他们兴旺起来。对这些属性的狭隘关注可能会被误导,就像ASIC公司在20世纪90年代对它们的狭隘关注导致他们低估了FPGA。尽管存在缺点,但可编程性给了FPGA一个优势。这种优势转化为风险更低,设计更简单。这些属性仍然有价值,但其他技术也提供可编程性。
设计工作和风险正在成为可编程逻辑中的关键要求。非常大的系统难以正确设计,需要设计师团队。组装复杂的计算或数据处理系统的问题促使客户找到更简单的解决方案。随着设计成本和时间的增加,它们成为FPGA的一个问题,如ASIC在20世纪90年代的ASIC NRE成本。从本质上讲,大的设计成本会破坏FPGA的价值主张。
就像30年前寻求定制集成电路的客户被ASIC吸引到FPGA一样,现在很多人都被多核处理器,图形处理器(GPU)和软件可编程应用特定标准产品(ASSP)所吸引。这些替代解决方案提供预先设计的系统软件,以简化到他们的映射问题。它们牺牲了易用性的可编程逻辑的一些灵活性,性能和功率效率。很明显,虽然有许多FPGA用户需要利用FPGA技术的极限,但是还有许多其他技术能力足够的人,但是由于使用这种技术的复杂性而使他们感到害怕。
设备的复杂性和能力促使设计工具的能力增加。现代的FPGA工具集包括从C,Cuda和OpenCL到逻辑或嵌入式微处理器的高级综合汇编。供应商提供的逻辑和处理功能库支持设计成本。工作的操作系统和管理程序控制FPGA SoC操作。 FPGA设计系统内置了团队设计功能,包括构建控制。一些功能是由供应商自己建立的,另一些则是不断增长的FPGA生态系统的一部分。
显然,可用性对于FPGA的下一个阶段至关重要。这种可用性是通过更好的工具,更高级的建筑,工艺技术的开发还是固定块的更多积累来实现的?最有可能的是,就像以前的每一个年龄都需要为每个年龄段做出贡献一样,所有的技巧都需要成功。还有更多。与其他阶段一样,FPGA的下一个阶段将只是在回顾中才会完全清楚。在整个年龄,期望看到历史悠久的好工程:从现有的技术生产出最好的产品。随着现有技术和“最佳”定义的不断变化,这一良好的工程将会完成。
十四、FPGA的未来
未来是什么?此后是什么阶段?我拒绝推测,而是发出一个挑战:记住Alan Kay的话:“预测未来的最好方法就是发明它。”
-
FPGA
+关注
关注
1664文章
22506浏览量
639397 -
摩尔定律
+关注
关注
4文章
640浏览量
81155 -
晶体管
+关注
关注
78文章
10443浏览量
148667
发布评论请先 登录
探索UPSD3212A/C/CV:集成8032 MCU、USB与可编程逻辑的闪存可编程系统设备
如何实现可编程直流电源的脉冲输出模式

探索CAT5110/5118/5119:32抽头数字可编程电位器的奥秘
开源项目USB协议分析仪总体介绍

音频应用的利器:DS4420 I²C可编程增益放大器
Zynq全可编程片上系统详解
CDCE913 可编程1PLL VCXO时钟合成器技术手册
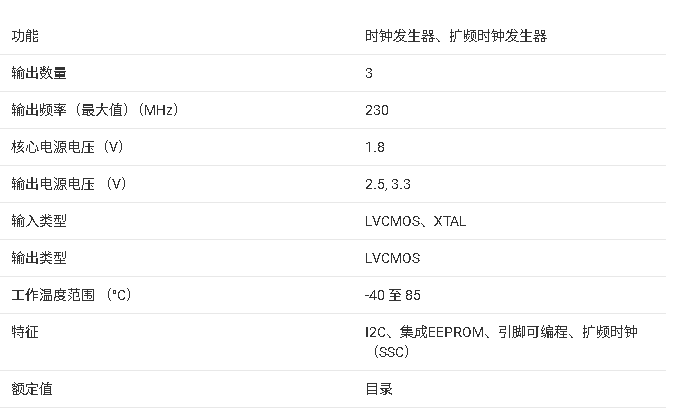
CDCE937 可编程 3-PLL VCXO 时钟合成器技术手册
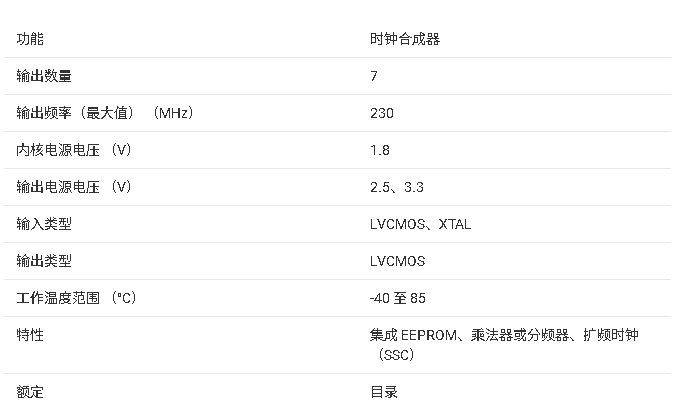
LP5560可编程单LED驱动器数据手册总结
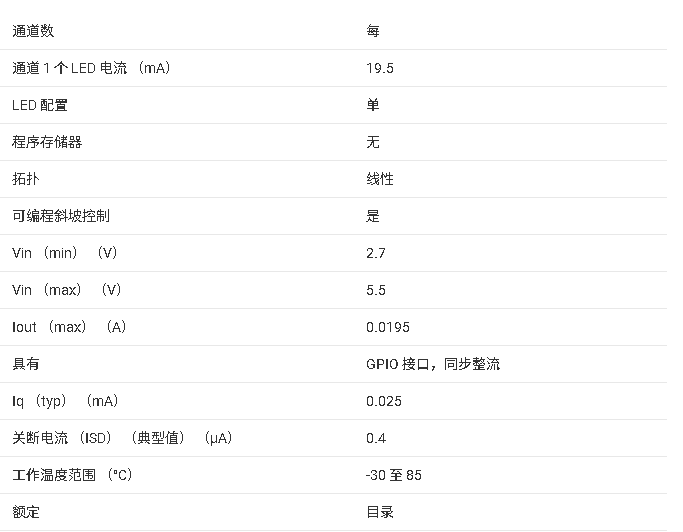
PGA855可编程增益仪表放大器技术解析与应用指南
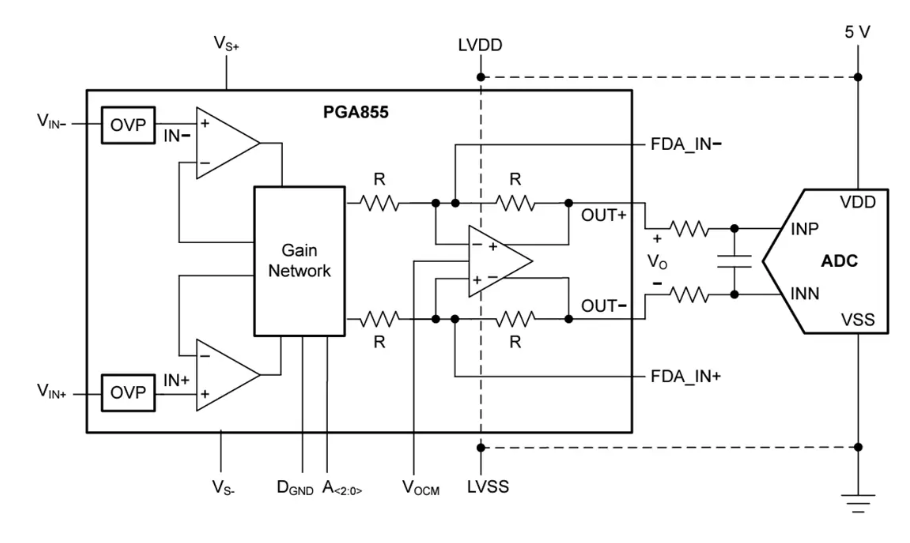
吉事励可编程交流恒流源原理及特点介绍

Texas Instruments PGA849精密可编程增益放大器数据手册
可编程SLIC语音芯片哪家好?

可编程低抖动VCXO:支持±150ppm拉力范围与1~3天快速交付




评论